 2025, Vol. 42
2025, Vol. 42扩展功能
文章信息
- 王峻, 王义盛, 何宇超, 段中兴.
- WANG Jun, WANG Yisheng, HE Yuchao, DUAN Zhongxing
- 基于多目标跟踪的公路隧道交通流检测方法
- Highway tunnel traffic flow detection method based on multiple object tracking
- 公路交通科技, 2025, 42(2): 23-30
- Journal of Highway and Transportation Research and Denelopment, 2025, 42(2): 23-30
- 10.3969/j.issn.1002-0268.2025.02.003
-
文章历史
- 收稿日期: 2022-12-08




2. 中交隧道工程局有限公司, 北京 100024;
3. 西安建筑科技大学 信息与控制工程学院, 陕西 西安 710055
2. CCCC Tunnel Engineering Co., Ltd., Beijing 100024, China;
3. College of Information and Control Engineering, Xi'an University of Architecture and Technology, Xi'an, Shaanxi 710055, China
在隧道能耗构成中,通风和照明系统的能耗占主要比例,尤其在特长隧道中,这一问题更加突出。其原因在于隧道内部的特殊环境,使得传统的交通流检测方法存在信息采集局限、精度较低以及适应性差等问题,无法实时准确地反映交通流的变化。因此,亟需开展对隧道交通流的精确、快速检测方法方法研究,以实现对交通流的实时动态监测,优化通风和照明系统的控制策略,从而有效降低能耗并提升隧道管理的智能化水平。
目前,交通量检测方法主要基于车辆检测与目标跟踪等技术和方法[1-4]。近年来,随着智能理论和技术的发展和广泛应用,许多学者开始研究基于深度学习的交通流检测方法,将算法搭载至摄像机等硬件设备环境中,实现视频采集、车辆检测跟踪、交通流技术的有效结合,取得了系列的研究进展。李珣等[5]基于Darknet框架融合YOLOv2算法对车辆目标检测取得了较为理想的效果;YOLOv3-tiny[6]的出现提高了检测算法的板端实用性,该算法对硬件的性能要求较低,算法实时性较高,模型体积仅34.7 MB,但对于图像的深层特征提取能力较弱,泛化性能较差,检测效果不够理想;金立生等[7]针对动态多目标检测,提出了一种可移植于嵌入式设备的改进YOLOv3算法,提高了该检测算法的应用灵活性,但该类方法不能直接进行交通流统计,因此,学者们开始将多目标跟踪技术应用于交通流视频分析中。毛邵勇等[8]利用YOLOv3网络和DeepSORT技术设计了面向高速公路的车辆视频监控分析系统,能够基本实现交通流数量统计与异常事件检测;李永上等[9]通过改进YOLOv5s并结合DeepSORT技术有效获取公路场景下的交通流;赵璐璐等[10]基于YOLOv5s算法,通过融合SENet有效改善了交通流较大时算法的误检漏检情况;陈秀锋等[11]为区分不同车型目标,设计了类锚虚拟线圈的多流向交通流检测算法,通过不同预设尺寸的类锚线圈,对交通流车辆类型进行了有效区分;吴宏涛等[12]通过帧差算法,提出了一种对称帧差分约束下的交通视频车辆分割算法,提高了交通场景下的不同状态车辆目标检测精度。但基于监控视频分析的面向公路隧道场景的交通流量检测系统在中国还未得到广泛应用。为此,本研究提出基于多目标跟踪的交通流检测方法,为公路隧道照明和通风系统的优化控制提供理论与数据支撑。
1 检测网络与算法设计 1.1 交通流视频检测算法框架基于监控视频进行隧道交通流检测和统计主要面临以下问题和挑战:(1)车辆实时性检测要求高。由于交通流检测结果需要实时反馈,并且要求在同一平台进行多路监控视频分析,以得到车辆数目的结果反馈,因此对目标跟踪算法的快速性与准确性要求非常高。(2)监控画面多样。由于隧道主要位于山区或城市地下,内部交通环境复杂,而且因为光照条件、监控高杆的架设位置不统一等原因,监控画面效果难以保证,因此,对算法的泛化性要求较高。(3)车辆形变大。由于行驶车辆在监控画面中的尺寸变化,导致跟踪目标时容易出现漏标、误标的情况,影响跟踪与计数效果。为解决以上问题,并为隧道通风和照明系统运行控制提供准确的交通流数据,本研究提出基于多目标跟踪的交通流检测方法。首先,基于FairMOT算法[13],使用hardnet85[14]作为模型的backbone,以获取更为丰富的车辆特征信息,同时选择DLA60[15]作为检测分支,增强算法对于运动中车辆形状尺寸变化的适应性,提高车辆检测效果;其次,结合匈牙利匹配算法[16]与基于核相关滤波(Kernelized correlation filter,KCF) 的目标增量跟踪算法[17]进一步优化车辆目标跟踪效果;最后,设计虚拟绊线构建车辆检测跟踪ROI[18]区域,改进车流量的统计性能,增强车流量检测结果的可靠性。
面向隧道的交通流检测系统由视频采集、多目标跟踪和交通流统计3个部分构成,结构如图 1所示。

|
| 图 1 隧道交通流检测系统整体架构 Fig. 1 Overall architecture of tunnel traffic flow detection system |
| |
本研究算法通过摄像头采集隧道交通视频,然后进行分帧预处理,之后送入FairMOT多目标跟踪网络,进行多目标跟踪,并采用式(1)进行交通流与密度的转化:
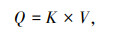
|
(1) |
式中,Q为车流量;K为车流密度;V为车辆行驶平均速度。
1.2 多目标跟踪算法框架本研究以FariMOT网络作为基础网络,FairMOT分为特征提取网络(Encoder-decoder)与Detection和Re-ID两个HEAD部分,结构如图 2所示。考虑到隧道车辆跟踪时,多路监控视频需要在同一平台进行目标跟踪与密度计算等操作,而DRAM带宽有限,检测效率难以优化,因此本研究使用HarDNet (Harmonic DenseNet) 二者不符作为特征提取网络,在不影响识别精度的前提下减少特征映射的DRAM流量,提高跟踪速度;使用DLA的变体DLA60作为Encoder-decoder模块,使得底层聚合和高层聚合之间加入更多的跳跃结构,获取更加丰富的特征;车辆目标在移动时形状大小会发生变化,在画面中目标过小或过大而产生形变都会影响跟踪效果,因此本研究设计虚拟绊线,来避免漏跟踪与误匹配的发生。

|
| 图 2 FairMOT算法框架 Fig. 2 FairMOT method framework |
| |
1.2.1 目标检测
目标检测包含以下4个部分:heatmap head,box offset and size head,Re-ID branch。其中,heatmap head用于预估目标中心位置,使用了与focal loss类似的损失函数;Box offset head使得预估的目标位置更精准,辅助目标中心位置的预估;Box size head对每个预估的目标中心,预估其对应box的长和宽;Re-ID branch对每个预估出的目标中心产生64维的特征图,该特征图用于后续计算前后帧目标的相似度。本研究采用anchor-free的目标检测范式,以避免检测到物体的中心与实际中心出现偏差而导致ID频繁变化的情况。
1.2.2 虚拟绊线设计在算法得到目标预估框大小、框坐标、目标中心位置以及目标特征信息之后,本研究在输入图像中设置虚拟绊线,对绊线内目标进行后续相似度、代价矩阵等计算操作,达到缩小目标重识别范围的目的。该操作可以过滤掉发生形变与尺寸过小的目标,间接提高目标的跟踪性能。对于输入图像取各道路区域边界线段与图像左右两侧的交接点,若一个交接点位于左右边界,一个交接点位于下方边界,且交接点高于h,h=kH,则从该交接点做平行于水平方向的直线作为计数下边界线,取距离下边界线h+1/2H高的水平线作为计数上分界线,其中H为图像的纵向高度,k为摄像机架设高度与俯仰角所决定的系数。设计示意如图 3所示。

|
| 图 3 虚拟双绊线示意图 Fig. 3 Schematic diagram of virtual double-tripwire |
| |
1.2.3 跟踪实现
跟踪过程的实现主要分为触线检测、信息关联和级联匹配3部分。逻辑结构如图 4所示。

|
| 图 4 多目标跟踪逻辑结构 Fig. 4 Logic structure of multiple object tracking |
| |
触线检测:当有新目标触发绊线时,对其进行跟踪检测,车辆计数加一,当其触发离开线时,停止跟踪。
信息关联:进行特征相似度计算以及检测框和预测框的马氏距离来确定目标信息的匹配程度,计算如式(2)所示:
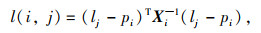
|
(2) |
式中,X为检测框与跟踪框的协方差矩阵;lj为第j个检测框的位置;lj为第i个跟踪框的位置;pi为第i个跟踪框位置。
级联匹配:当目标出现遮挡时,卡尔曼滤波就会造成目标丢失,如果此时继续匹配马氏距离则目标框会停留在原地,导致目标移除遮挡后不能继续跟踪,造成跟踪的不连续,级联匹配则是对最近出现的目标赋予更大的权重,使得目标进行强制更新,促使目标跟踪连续。
为了防止多目标跟踪因检测丢失目标导致无法继续跟踪,因此引入KCF算法,在MOT多帧匹配失效时,转为KCF跟踪,直到目标重新检出,再转为MOT跟踪,由此提高跟踪轨迹的连续性,确保交通流量统计的有效性。
2 试验设置与评价指标 2.1 试验环境为了更加客观地评估所提方法的有效性,所有试验均在paddlepaddle2.1.2+python3.7环境下训练和测试,使用显存为32G的Tesla V100显卡搭配CUDA10.1作为GPU环境。
本研究案例项目隧道采用盾构隧道穿越长江,公路工程主线全长约11.825 km,其中隧道段长6 409.5 m。设置互通3座,风塔2座,管理养护中心1处。采用双向六车道设计标准,设计行车速度80 km/h,路基宽度33 m。
此工程布设高清网络摄像机8台,每3车道架设一台摄像机,覆盖隧道双向出入口,不间断采集隧道出入口视频图像。摄像机安装高度距离地面不低于4.5 m,安装角度随隧道现场情况调整,尽可能减少车辆图像形变。
2.2 数据集与数据预处理采用BDD100K数据集[19]作为预训练数据集,以自建隧道数据集作为迁移学习训练数据集。BDD100K数据集由伯克利大学AI实验室(BAIR)于2018年5月发布。BDD100K数据集包含10万段高清视频,每个视频约40 s,720 p,30 fps。每个视频的第10 s对关键帧进行采样,得到10万张图片,图片尺寸为1 280×720,并进行标注。BDD100K数据集采集自6种不同的天气,其中晴天样本较多;采集的场景有6种,以城市街道为主;采集的时间有3个阶段,其中白天和夜晚居多。自建数据集由西安奥体和文昌门-和平门两个隧道采集的视频数据构成,文昌门-和平门隧道位于市区内,具有车流量大、车速适中等特点,该数据集的场景包括白天、夜间、出入口不同高度、俯角等视角,具有多场景变化的特点。视频总长为20 h,共抓取不同场景的视频帧图片2 430张。为提升模型的泛化性,以更好地应对实际场景中不同光照和角度以及遮挡带来的挑战,采用图像处理方法通过随机旋转、亮度调整、锐化和Mixup[20]等操作进行扩充,得到12 180张图片作为初始数据集。对初始数据进行筛选与标注后,得到的自建数据集为9 720张图片,并按8∶1∶1的比例,划分为训练集、验证集与测试集。
2.3 损失函数和学习率优化 2.3.1 损失函数(1) heatmap的损失函数
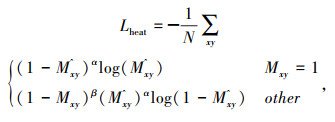
|
(3) |
式中,M^xy为heatmap的特征图;Mxy为heatmap的标注。
(2) boxsize和center offset的损失函数
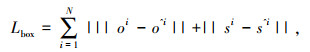
|
(4) |
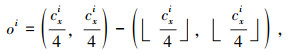
|
(5) |
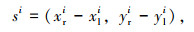
|
(6) |
式中,N为图中目标总数;(xl, yl)为目标左上角坐标;(xr, yr)为目标右下角坐标;(cx, cy)为目标中心坐标;oi为目标真实偏移;si为目标真实尺寸;o^i为center offset输出;s^i为boxsize输出。
(3) Re-ID的Embedding损失函数
Re-ID基本原理也属于分类任务,因此损失函数采用最常见的softmax损失函数[21]。
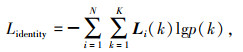
|
(7) |
式中,Li(k)为目标标注的one-hat向量; p(k)为预测ID编号的可能性分布。
(4) 框架整体损失函数
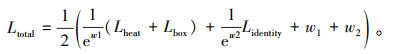
|
(8) |
为了更全面地评价模型性能,选用多目标跟踪常用评价指标,包括多目标跟踪准确度MOTA,平均数比率IDF1,目标ID异常切换次数IDSw以及跟踪速度FPS几种指标,以充分评价模型的性能与有效性。
(1) 多目标跟踪准确度MOTA
MOTA表示跟踪模型在处理误报、目标丢失、ID异常切换之外的正确样本占所有样本的比例,体现了跟踪器的跟踪轨迹性能,与目标的位置估计无关,其计算如式(9)所示:
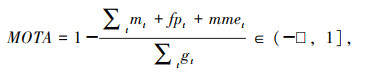
|
(9) |
式中,mt为视频序列t时刻中假阳性数量;fpt为假阴性数量;mmet为目标ID异常切换数量;gt为真实目标数量。因为假阴性、假阳性和ID异常切换数量之和有可能超出真实目标数量,因此MOTA数量可能为负值。
(2) 平均数比率IDF1
单一识别精确度IDP和识别召回率IDR不能很好体现多目标跟踪器准确跟踪的综合性能,因此引入IDF1指标,其计算如式(10)所示:
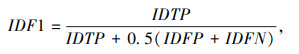
|
(10) |
式中,IDTP为视频序列中检测目标正确跟踪数量;IDFN为未跟踪数量;IDFP为错误跟踪数量。
(3) 目标ID异常换次数IDSw
被跟踪目标身份改变时称为异常ID切换,IDSw表示在整段视频序列中跟踪目标ID异常切换的次数。
(4) 多目标跟踪速度FPS
FPS表示多目标跟踪器每秒可以处理的视频帧数,该指标主要体现跟踪器的处理速度。
3 试验结果与分析 3.1 算法有效性验证为验证算法修改的有效性,本研究使用1 h隧道交通流视频(共2 564辆车)对各修改模块进行消融试验,并对指标统计如表 1所示,测试结果如图 5所示。
| 算法 | 指标 | |||
| MOTA/% | IDF1/% | IDSW | FPS | |
| FairMOT | 74.0 | 76.1 | 64 | 25 |
| FairMOT+DLA-60 | 80.8 | 81.1 | 56 | 23 |
| FairMOT+hardnet85 | 83.2 | 83.1 | 49 | 20 |
| FairMOT+DataAug | 76.5 | 77.2 | 59 | 24 |
| Ours | 83.3 | 81.9 | 48 | 20 |

|
| 图 5 试验结果 Fig. 5 Test result |
| |
通过车辆检测以及跟踪模块得到待跟踪出现的坐标、轨迹和帧数,输入至应用模块完成交通流量统计。在交通流量统计任务中,通过检测结果可看出,本算法可以有效识别新增目标并赋予正确的跟踪ID号,如图 5(a)所示,对于遮挡目标和小目标,本研究算法也能有效识别,如图 5(b)所示。但是如图 5(c)所示,画面中存在尺寸过小车辆,虽然网络可以有效检出目标,但不利于目标精确跟踪,最终会影响交通流量统计结果,因此在计数时采用双虚拟绊线设置,确保计数区域目标清晰,车辆越过触发线时开始跟踪并计数,越过离开线后停止跟踪。
为充分验证所提绊线策略的有效性,特对两隧道白天和夜间场景车流视频进行统计,并与实际测试结果对比,结果如表 2所示。
| 场景 | 车辆总数 | 算法统计数 | 误检数 | ID异常切换数 |
| 隧道1白天 | 522 | 513 | 3 | 4 |
| 隧道1夜间 | 435 | 423 | 1 | 2 |
| 隧道2白天 | 610 | 604 | 5 | 4 |
| 隧道2夜间 | 413 | 398 | 2 | 2 |
| 总计 | 1 980 | 1 938 | 11 | 12 |
实际视频通过车辆总数1 980辆,算法统计车辆数为1 938辆,漏检19辆,误检11辆,ID异常切换12辆,检出率为97.8%,准确率为98.8%,运行速度可达20帧/s,满足使用需求,通过该策略进一步弥补了模型检测缺陷,增强了系统的实用性。
4 结论为实现隧道交通流量的实时计算,本研究基于自建隧道车流数据集对FairMOT框架进行优化和二次训练,使用虚拟绊线构建车流ROI区域,融合匈牙利匹配算法和KCF,有效实现隧道车辆目标检测和跟踪,从而获得更加准确的隧道交通流量,为后续隧道通风、照明控制系统提供数据支持。
(1) 该方法充分考虑了隧道特点,基于现有多目标跟踪框架FairMOT优化构建,算法设计合理,经测验,目标检测、跟踪效果良好,能以较高的准确率获得隧道交通流量信息。
(2) 多目标跟踪框架FairMOT为轻量级框架,主干网hardnet85仅8.4M,便于实际应用部署,目标跟踪策略清晰明了,易于实现。
(3) 因隧道环境特殊性,因此引入虚拟绊线策略,构建车流ROI区域,提升目标检测和跟踪效果,而且因为交通拥堵或信号灯控制,隧道车流速度会发生大幅波动,引入双摄像头策略,提升隧道交通流量计算的准确性。
(4) 误报和漏报大多发生在车辆并行或严重遮挡情况下,正常交通状况下,误检、漏检率较低,满足实际使用需求。
| [1] |
张炳力, 秦浩然, 江尚, 等. 基于RetinaNet及优化损失函数的夜间车辆检测方法[J]. 汽车工程, 2021, 43(8): 1195-1202. ZHANG Bingli, QIN Haoran, JIANG Shang, et al. A method of vehicle detection at night based on RetinaNet and optimized loss functions[J]. Automotive Engineering, 2021, 43(8): 1195-1202. |
| [2] |
李晓欢, 霍科辛, 颜晓凤, 等. 基于特征加权视觉增强的雷视融合车辆检测方法[J]. 公路交通科技, 2023, 40(2): 182-189. LI Xiaohuan, HUO Kexin, YAN Xiaofeng, et al. A method for radar-camera fusion vehicle detection based on feature weighted and visual enhancement[J]. Journal of Highway and Transportation Research and Development, 2023, 40(2): 182-189. DOI:10.3969/j.issn.1002-0268.2023.02.022 |
| [3] |
黄思德, 黄荣军, 张岩坤, 等. 基于监控视频的交通事故自动识别算法[J]. 公路交通科技, 2024, 41(1): 169-176. HUANG Side, HUANG Rongjun, ZHANG Yankun, et al. An algorithm for automatic traffic incident detection based on surveillance video[J]. Journal of Highway and Transportation Research and Development, 2024, 41(1): 169-176. DOI:10.3969/j.issn.1002-0268.2024.01.019 |
| [4] |
徐谦, 李颖, 王刚. 基于深度学习的行人和车辆检测[J]. 吉林大学学报(工学版), 2019, 49(5): 1661-1667. XU Qian, LI Ying, WANG Gang. Pedestrian-vehicle detection based on deep learning[J]. Journal of Jilin University (Engineering and Technology Edition), 2019, 49(5): 1661-1667. |
| [5] |
李珣, 刘瑶, 李鹏飞, 等. 基于Darknet框架下YOLO v2算法的车辆多目标检测方法[J]. 交通运输工程学报, 2018, 18(6): 142-158. LI Xun, LIU Yao, LI Pengfei, et al. Vehicle multi-target detection method based on YOLO v2 algorithm under Darknet framework[J]. Journal of Traffic and Transportation Engineering, 2018, 18(6): 142-158. |
| [6] |
GONG H, LI H, XU K, et al. Object detection based on improved YOLOv3-tiny[C]//2019 Chinese Automation Congress (CAC). IEEE, Hangzhou: IEEE, 2019: 3240-3245.
|
| [7] |
金立生, 郭柏苍, 王芳荣, 等. 基于改进YOLOv3的车辆前方动态多目标检测算法[J]. 吉林大学学报(工学版), 2021, 51(4): 1427-1436. JIN Lisheng, GUO Baicang, WANG Fangrong, et al. Dynamic multiple object detection algorithm for vehicle forward based on improved YOLOv3[J]. Journal of Jilin University (Engineering and Technology Edition), 2021, 51(4): 1427-1436. |
| [8] |
毛昭勇, 王亦晨, 王鑫, 等. 面向高速公路的车辆视频监控分析系统[J]. 西安电子科技大学学报, 2021, 48(5): 178-189. MAO Zhaoyong, WANG Yichen, WANG Xin, et al. Vehicle video surveillance and analysis system for the expressway[J]. Journal of Xidian University, 2021, 48(5): 178-189. |
| [9] |
李永上, 马荣贵, 张美月. 改进YOLOv5s+DeepSORT的监控视频车流量统计[J]. 计算机工程与应用, 2022, 58(5): 271-279. LI Yongshang, MA Ronggui, ZHANG Meiyue. Traffic monitoring video vehiclle volume statistics method based on improved YOLOv5s+DeepSORT[J]. Computer Engineering and Applications, 2022, 58(5): 271-279. |
| [10] |
赵璐璐, 王学营, 张翼, 等. 基于YOLOv5s融合SENet的车辆目标检测技术研究[J]. 图学学报, 2022, 43(5): 776-782. ZHAO Lulu, WANG Xueying, ZHANG Yi, et al. Vehicle target detection based on YOLOv5s fusion SENet[J]. Journal of Graphics, 2022, 43(5): 776-782. |
| [11] |
陈秀锋, 吴阅晨, 邴其春, 等. 基于类锚虚拟线圈的多流向车流量检测算法[J]. 交通运输系统工程与信息, 2021, 21(2): 51-57. CHEN Xiufeng, WU Yuechen, BING Qichun, et al. A multi-direction traffic flow statistics algorithm based on anchor-loke visual loops[J]. Journal of Transportation Systems Engineering and Information Technology, 2021, 21(2): 51-57. |
| [12] |
吴宏涛, 孟颖, 雷凌昱. 一种对称帧差分约束的车辆自适应分割算法[J]. 公路交通科技, 2024, 41(4): 176-185. WU Hongtao, MENG Ying, LEI Lingyu. An adaptive vehicle segmentation algorithm based on symmetric frame differential constraint[J]. Journal of Highway and Transportation Research and Development, 2024, 41(4): 176-185. DOI:10.3969/j.issn.1002-0268.2024.04.018 |
| [13] |
ZHANG Y, WANG C, WANG X, et al. Fairmot: On the fairness of detection and re-identification in multiple object tracking[J].
International Journal of Computer Vision, 2021, 129(11): 3069-3087.
|
| [14] |
CHAO P, KAO C Y, RUAN Y S, et al. Hardnet: A low memory traffic network[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3552-3561.
|
| [15] |
YU F, WANG D, SHELHAMER E, et al. Deep layer aggregation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2403-2412.
|
| [16] |
CAO B, WANG J, FAN J, et al. Querying similar process models based on the Hungarian algorithm[J].
IEEE Transactions on Services Computing, 2016, 10(1): 121-135.
|
| [17] |
ZHAO F, HUI K, WANG T, et al. A KCF-based incremental target tracking method with constant update speed[J].
IEEE Access, 2021, 9: 73544-73560.
|
| [18] |
PRIVITERA C M, STARK L W. Algorithms for defining visual regions-of-interest: Comparison with eye fixations[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(9): 970-982.
|
| [19] |
YU F, CHEN H, WANG X, et al. Bdd100k: A diverse driving dataset for heterogeneous multitask learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual: IEEE, 2020: 2636-2645.
|
| [20] |
KIM J H, CHOO W, SONG H O. Puzzle mix: Exploiting saliency and local statistics for optimal mixup[C]//International Conference on Machine Learning. New York: ICML, 2020: 5275-5285.
|
| [21] |
WANG F, CHENG J, LIU W, et al. Additive margin softmax for face verification[J].
IEEE Signal Processing Letters, 2018, 25(7): 926-930.
|