 2024, Vol. 41
2024, Vol. 41扩展功能
文章信息
- 黄贤明, 翁成康, 黄海洋.
- HUANG Xian-ming, WENG Cheng-kang, HUANG Hai-yang
- 面向运输安全的高精度违禁品检测方法
- High Precision Contraband Detection Method for Transportation Safety
- 公路交通科技, 2024, 41(8): 55-65
- Journal of Highway and Transportation Research and Denelopment, 2024, 41(8): 55-65
- 10.3969/j.issn.1002-0268.2024.08.006
-
文章历史
- 收稿日期: 2024-04-08

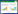


 ,
, X光安检是维护交通运输安全的一种重要手段。由于X光的透视性和假彩性,在对行李进行安检时,不需要打开行李箱即可完成检查。这为安检提供了极大便利。如今,X光安检仪已被广泛应用于世界上大多数的交通枢纽,如机场、车站等[1]。目前的安检工作主要依靠安检人员人工进行筛查。在检测过程中,安检人员首先使用X光安检仪辐照行李形成图像,然后通过图像判断是否存在违禁品。这对安检人员的专业知识和经验有着很高要求,而筛查工作本身也存在一定的漏报和误报率。在节假日等人流量巨大的情况下,长时间、高强度的识别工作易使工作人员处于疲劳状态,这更降低了审查的准确性。因此使用计算机视觉技术从X光图像中自动识别并标记行李中的违禁物品,能够降低人工成本、极大地提高效率和可靠性。
与一般目标检测相比,违禁品检测有许多不同,包括数据规模、种类范围、模型目标以及应用场景等。一般物品数据集通常包含数万到数十万张图像,类别数量在几十到几百种。而违禁品数据集较小,图像数量常在万量级,类别少于100种。一般目标检测针对日常生活中常见的多类别物品, 如人、动物、交通工具等。违禁品检测更侧重特定的禁止物品,如武器、爆炸物等。一般目标检测侧重提高海量物品类别的区分。而违禁品检测则要求较高的mAP和广泛类别的检测召回率。一般目标检测应用于较为开放的环境中。而违禁品检测更多应用于安检等对安全性要求极高的场景。
针对X光行李物品安全检测过程中存在的困难问题[2],国内外的研究人员提出了众多解决思路。例如,Li等[3]基于Mask R-CNN[4]模型,通过引入语义分割网络构建两阶段卷积神经网络(Convolutional Neural Network, CNN)模型,改善了X光下行李物品图像重叠引起的性能下降问题[5]。针对CNN训练过程中存在的数据缺乏问题[6],Zhu等[7]利用数据增强方法,将非X光下图像转化为类似X光下图像,并与不同背景组合,获得了用于CNN训练过程的数据。然而,这些工作未考虑到行李物品不规则的纵横比对模型训练以及预测的影响,这阻止了多尺度任务情况下模型检测性能的改善。基于上述工作带来的启发,我们设计了一种新的骨干网络HPCDNet(High Precision Contraband Detection Network)以提高检测精度、降低计算成本;其次,针对检测中存在的半透明、小型目标检测难题[8],我们设计了X-Head融合检测头。检测头使用损失函数缓解正负样本不均衡,同时通过改进非极大值抑制方式与上采样方法,提高了模型的表达能力。检测头还改进了空间金字塔池化[9]结构以获取多层次特征图,提高模型的检测精度。HPCDNet与X-Head共同组成了HPXD方法。在EDS数据集[10]与VOC数据集[11]上的试验结果显示,HPXD实现了具有竞争力的检测精度。
1 相关工作 1.1 目标检测计算机视觉是将生物对客观世界的感知、识别和理解等用计算机实现的技术。目标检测是计算机视觉的一个重要分支和应用,其目标相较于计算机视觉更具体,是在图像或视频中检测和定位人、车等对象实例[12]。2015年,RCNN[13]开启了深度学习在目标检测任务上的广泛应用。Fast R-CNN[14]以及Faster R-CNN[15]等模型构建了两阶段检测框架,在深度卷积网络中引入特征提取,明显改善了检测精度。根据检测过程是否产生锚框(Anchor),目标检测算法可以被分为两类,即Anchor-based算法与Anchor-free算法。在主流检测模型中,Lin等[16]于2017年发布的RetinaNet检测模型使用先验Anchor框对特征图上的每一个像素进行分类与回归,Anchor框的尺度与比例设计合理,这减轻了生成框的难度,提高了检测精度。而Tan等[17]于2020年推出的Efficientdet检测模型使用多尺度的Anchor框,在不同的特征级别为检测提供不同大小的先验框,这有助于检测不同尺度的对象。YOLO系列也采用Anchor框作为检测先验,在每个特征点上进行多类别与多尺度的检测。YOLOv5[9]、Ge等[18]的YOLOX和Wang等[19]的YOLOv7在Anchor框的数量选择和尺度设计上有不同,以实现最佳的速度和准确率。相比之下,Zhou等[20]于2020年提出的CenterNet没有使用Anchor框,它通过完全不同的中心点回归方案实现目标检测,使用基于关键点的特征表达方式,通过组件损失函数精确预测对象中心,实现高精度检测。在设计目标检测模型时,应该针对检测需求选择合适的方法。当前研究热点聚焦于检测器的精度及强健性的综合提升、以及检测模型在边缘计算等实际场景中的应用部署。在2020年,Transformer[21]架构被引入检测模型,DETR[22]使用Encoder-Decoder结构实现了端到端的目标检测。它没有任何区域提议,绕过了其他检测框架中普遍的不准确提议的限制,消除了由于新类的区域建议不准确而造成的约束。2021年,Hu等[23]研究提出了一种基于上下文感知聚合的密集关系提取目标检测模型。解决了以往目标检测中由于外观变化或遮挡从而导致同一类对象在查询和支撑样本之间变化很大时,整体特征产生误导的问题。2022年,Li等[24]探索了目标检测任务中的标签赋权问题。现有方法主要关注正样本权重设计,而负样本权重直接从正样本权重导出,这限制了检测器的学习能力。这种双重权重机制的独特设计可以独立设计正负样本权重,更有效区分样本重要性,优化目标检测器。
1.2 注意力机制注意力机制是一种用于对输入的信息进行加权处理的方法。20世纪90年代,认知领域的学者发现人类在处理信息时会自动过滤掉一些信息,于是将这种处理信息的机制称为注意力机制[25]。注意力机制能够自适应地调整权重,用于处理序列中较长距离的依赖关系,并且可以对不同维度的信息进行不同程度的关注,使模型能够更加关注重要的部分、减少无关的干扰,从而提升性能[26]。2014年,Mnih等[27]首次将注意力机制应用于视觉领域。至此,注意力机制在自然语言处理、计算机视觉等领域都得到了广泛的应用。
Hu等[28]聚焦于特征提取的通道维度,提出了SE Attention(Squeeze-and-Excitation Attention)。通过对通道间的依赖关系建模,SE Attention可以根据输入自适应地调整各通道特征响应值,增强网络的表示能力。从试验中得出的结果显示,SE Attention可以在增加一部分计算消耗的同时极大地提升网络性能。Woo等[29]提出的CBAM(Convolutional Block Attention Module)是一种用于前馈卷积神经网络的轻量级注意力模块。CBAM基于通道和空间双向注意力机制,融合了通道注意力模块和空间注意力模块,能够有效地提高模型对通道和空间信息的敏感度。Hou等[30]提出了一种为轻量级网络设计的新注意力机制(Coordinate Attention,CA)。CA将通道注意力分解为两个沿着不同方向聚合特征的一维特征编码过程,它们可以互补地应用到输入特征图来增强目标表示。
2 HPXD检测方法 2.1 基本框架HPXD的详细架构如图 1所示。检测的基本流程为,先对输入的图片预处理,将输入图片转化为相同尺寸的三通道RGB图片,输入到骨干网络中。根据骨干网络中的3层输出,在检测头部分输出不同尺度的特征图。经过卷积和批标准化处理,完成分类、前后背景分类、边框3类任务。最后输出不同尺度的预测结果。

|
| 图 1 HPXD的整体结构 Fig. 1 Overall structure of HPXD |
| |
2.2 HPCDNet骨干网络
骨干网络是实现目标检测定位、检测和分割的基石。它通过卷积与池化等操作抽取输入数据的高层语义特征,然后对这些特征进行提炼与压缩。骨干网络输出包含数据关键信息的特征图,为后续任务提供输入。还为任务提供先验信息,实现参数的共享与初始化。
HPXD的骨干网络整体结构如图 1中HPCDNet模块所示,由卷积单元(Conv Unit, CU)模块、高效层聚合网络(Efficient Layer Aggregation Networks, ELAN)层以及高效最大池化层聚合网络(Efficient Layer Max-pooling Aggregation Networks, ELMPAN)层组成。其中CU模块由卷积(Conv)层、批标准化(Batch Normalization, BN)层[31]以及损失函数组成,如图 2所示。

|
| 图 2 CU模块基本结构 Fig. 2 Basic structure of CU module |
| |
ELMPAN由CU模块以及最大池化(Max-pooling, MP)模块构成,如图 3所示。更深的网络可以有效地学习和收敛,因此通过控制梯度路径,可以在不破坏原有梯度路径的情况下增强学习能力。ELAN层与ELMPAN层的区别在于ELAN的输入不经过MP模块。卷积块注意高效层聚合网络(Convolutional Block Attention Efficient Layer Aggregation Networks, CBAELAN)层在ELAN层的基础上进一步使用扩展、混洗和合并基数让网络在最短梯度路径上堆叠更多块,并使用注意力模块替换了ELAN的输出,使模型能够关注重要的部分、减少无关干扰,提升检测表现。

|
| 图 3 ELMPAN层及CBAELAN层详细结构 Fig. 3 Detailed structures of ELMPAN layer and CBAELAN layer |
| |
2.3 X-Head融合检测头
X-Head融合检测头包括CU模块、MP模块、CBAELAN层、上采样解码(Up-sampling Decoder, UD)模块、后续3个尺度输出的RepVGG[32]模块以及SimCSPSPPF[33]模块。SimCSPSPPF是一种特征聚合模块。它能通过多尺度金字塔特征融合,组合不同层次的语义信息,产生语义更丰富的特征表达,减少计算量,增强检测性能。由Li等[33]在SPPF Block[9]的基础上简化而成,结构如图 4所示,通过卷积层以及多尺度MP模块的组合达到了检测速度和精度的平衡。

|
| 图 4 SimCSPSPPF模块详细结构 Fig. 4 Detailed structure of SimCSPSPPF mdule |
| |
MP模块如图 5所示。右分支通过最大池化(Max Pooling)使输入的长宽减半,通过CU模块对输入的通道数减半,左分支则通过第1个CU模块对通道减半,第2个CU模块对长宽减半,而后左右分支通过Concat合并,得到输入输出通道相同,长宽减半的输出。

|
| 图 5 MP模块结构 Fig. 5 MP module structure |
| |
UD模块结构如图 6所示。上采样插值方式为双线性插值法。双线性插值法克服了最近邻插值灰度值不连续的特点,因为它考虑了待测采样点周围4个直接邻点对该采样点的相关性影响。虽然计算量相比于最近邻插值法大,但是缩放后图像质量高、损失小,同时不会产生明显的马赛克和锯齿现象,因此更加适合X光下行李物品中违禁品检测场景。

|
| 图 6 UD模块示意 Fig. 6 Schematic diagram of UD module |
| |
RepVGG模块在训练和部署的时候结构不同,在训练时的结构为3×3的卷积加1×1的卷积分支,若输入和输出的通道以及宽高的尺度一致时再添加一个BN的分支,3个分支相加输出,如图 7所示。在应用时,为了方便部署,会将分支的参数重参数化到主分支上,取3×3的主分支卷积输出。

|
| 图 7 RepVGG模块示意 Fig. 7 Schematic diagram of RepVGG module |
| |
2.3.1 卷积块注意力机制
卷积块注意力机制(Convolutional Block Attention Module, CBAM)非常轻量化,整体流程如图 8所示。首先输入一个中间特征图至通道注意力模块获取通道注意力,将注意力权重作用于中间特征图。然后将施加通道注意力的特征图输入至空间注意力模块获取空间注意力,将注意力权重作用到特征图上。输入的特征图经过了通道和空间两个注意力机制的处理,特征被自适应细化。

|
| 图 8 CBAM基本流程 Fig. 8 Basic flow of CBAM |
| |
通道注意力模块(Channel Attention Module, CAM)如图 9(a)所示。首先通过全局平均池化与最大池化得到降维后的特征图,再将特征图送入多层感知机(Multi-Layer Perceptron, MLP)。最后将MLP输出的特征进行基于元素的加和操作,并经过Sigmoid激活函数处理,输出通道注意力特征图(Map-channel, Mc)。该过程能够充分挖掘不同通道之间的相关性,削弱冗余和无关通道的影响。

|
| 图 9 通道注意力模块与空间注意力模块详细结构 Fig. 9 Detailed structures of channel attention module and spatial attention module |
| |
空间注意力模块(Spatial attention module, SAM)如图 9(b)所示,首先输入通道注意力模块产生的特征图,对其做全局平均池化与最大池化通道拼接,经过卷积操作降维。再经过Sigmoid激活函数,输出空间注意力特征图(Map-spatial, Ms)。空间注意力得到2个特征图。将这2个特征图做模块根据每个空间位置的特征高低选取与之相似的空间区域,并将该区域内的特征作为该位置特征的重要参考,能够有效地提高模型对空间信息的敏感度。
2.3.2 非极大值抑制非极大值抑制(Non-maximum Suppression, NMS)算法[34]是目标检测中的一种常见的后处理技术。其用途为抑制重复的检测框,并只保留置信度最高的检测框。如今大部分的单阶段和两阶段检测算法在推断阶段都使用了NMS作为输出前的最后一步,例如Cascade R-CNN[35]等。NMS的变体多种多样,最为常见的即为Hard-NMS。但Hard-NMS直接删除相邻的同类别目标,对密集目标的输出不友好。而X光下行李物品又呈现出一种密集、层叠的状态。因此应当选取一种更先进的NMS方式,用于抑制多余的检测框,例如Merge-NMS[36]方式。Merge-NMS在Hard-NMS的基础上增加保留框位置平滑策略。它不仅能够抑制掉重复的检测框,而且还能够将相邻的检测框合并成一个更精确的检测框,从而减少误检情况,提高目标检测的精度和效率。
2.4 损失函数损失函数(Loss Function)是用来衡量神经网络学习的预测输出与真实目标值之间差异的函数。它反映了当前参数下模型的预测性能[37]。模型设计的目标是让预测值无限接近于真实值。因此需要通过调整参数,最小化损失函数,从而得到参数配置最优的模型。HPXD的损失函数包括类别置信度损失(Classification Loss, Lcls)、坐标回归损失(Localization Loss, Lloc)以及目标置信度损失(Confidence Loss, Lconf),有:
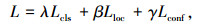
|
(1) |
式中,λ, β, γ为损失函数权重系数。α-IoU损失函数[38]的全称为Alpha-Weighted Intersection over Union。相比于传统的交叉熵损失函数,α-IoU可以更好地解决目标检测中的类别不平衡问题。在具体实现上,对于一个预测框和一个真实框,首先计算它们的交并比(Intersection over Union, IoU)。交并比作为目标定位的度量值,用于评估模型定位的准确性。其具体是指模型产生的预测边框与原图片标注的真值(Ground Truth, GT)的交叠比值。取值范围从0到1,数值越大表示重叠程度越大。通常认为IoU大于某一阈值(如0.5),则正确检测到了目标。如果该预测框和真实框属于同一类别,则将IoU作为损失函数的一部分。反之则将IoU乘以权重因子α,再将其作为损失函数的一部分。当某个类别的样本数量较少时,可以将权重因子设定为一个较大的值,使得该类别的检测结果更容易被优化。而对于样本数量较多的类别,可以将权重因子设定为一个较小的值,避免其影响整体的损失函数。α-IoU损失函数的计算式为:
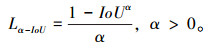
|
(2) |
目标检测的目的是检测和识别图像中的物体。为了保证精度,评估性能,需要使用性能评估指标。这些指标可以帮助我们评估模型在不同环境场景中的表现以及不同算法在同一任务上的优劣,以便选择最优的设计。通常,目标检测的性能评估指标主要包括准确度(Accuracy)、召回率(Recall)、精确率(Precision)、AP(Average Precision)、mAP(mean Average Precision)等[39],若将检测结果设定为正例(Positive)和负例(Negative)两种情况,则最终存在的结果将包括以下4种:即正确识别成正例的正例TP(True Positive)、错误识别成正例的负例FP(False Positive)、正确识别成负例的负例TN(True Negative)以及错误识别成负例的正例FN(False Negative)。
精确率(Precision)是指在所有检测出的目标中检测正确的概率,体现模型对负样本的区分能力,表示为:
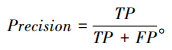
|
(3) |
召回率(Recall),指的是所有真实的正样本中被检测出来的样本占所有真正样本的比例,体现模型对正样本的识别能力,有:
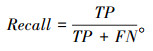
|
(4) |
平均精确率(Average, Precision, AP)指的是检测出的框的平均准确率,衡量模型在检测每一个类别目标时的精确度。AP可以反映模型在不同置信度下的表现,用置信度大于某阈值框的准确率平均值表示,有:
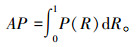
|
(5) |
mAP是多类别目标检测中的一种度量标准,表示模型在多类别检测任务上的平均性能。它可以反映模型在不同类别的表现,用所有类别的平均准确率的平均值表示,有:
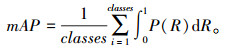
|
(6) |
数据集是根据不同需求,由多种数据类型打包的数据对象集合,使用优质数据集进行训练对于设计一个优秀的目标检测模型至关重要。本研究采用的数据集包括EDS数据集以及VOC数据集。其中EDS数据集包含了来自3台不同X光机器的14 219张图片,包括10类物品(Scissor, Plastic Bottle, Power Bank, Lighter, Umbrella, Laptop, Device, Glass Bottle, Knife, Pressure),共计31 655个目标实例,均由专业人员进行标注。
VOC数据集是一个用于图像分类、对象检测、语义分割等多种任务的数据集。VOC数据集最初只有4个类别(Bicycles, Cars, Motorbike, People)的标注数据用于分类检测任务,后扩充到了20个,见表 1。目前使用上主要有7个版本,分别是VOC07,VOC08,VOC09,VOC10,VOC11,VOC12和VOC07+12组合版。VOC07+12是VOC07和VOC12的组合版本,包含两个版本的数据集,共20个类别,21 502张图片,更加丰富的数据有助于训练和测试更加准确的检测模型,因此在本次试验中选择使用该数据集。
| 交通工具 | 动物 | 室内 | 人类 |
| 飞机 | 鸟 | 水壶 | 人类 |
| 自行车 | 猫 | 椅子 | |
| 船 | 牛 | 餐桌 | |
| 公交车 | 狗 | 盆栽 | |
| 汽车 | 马 | 沙发 | |
| 摩托车 | 羊 | 电视 | |
| 火车 |
本次试验中所使用模型训练环境为Ubuntu 20.04.2操作系统,GPU为NVIDIA GeForce GTX 1080 Ti,显存11 264 MB,CPU为Intel (R) Core (TM) i7-6850K,频率3.60 GHz,Python版本为3.7.13,深度学习框架版本为Torch 1.12.1+CUDA 10.2。我们使用与YOLOv7相同的优化器与学习设置,即试验初始学习率为0.01,循环学习率为2.3,动量为0.937,权值衰减率为0.000 5。模型迭代次数为100,批量大小为16,λ=0.125, β=0.05, γ=0.1。
3.3 性能分析 3.3.1 在EDS数据集上的对比试验为了验证HPXD的有效性,我们选择与Efficientdet,YOLOv5以及YOLOv7这些近年来被广泛使用的检测模型进行对比,试验在EDS数据集上进行,结果见表 2。可以看出HPXD在多个指标上都取得了最好的检测效果。HPXD的精确率为84.10%,对比Efficientdet,YOLOv5和YOLOv7分别提升了6.66%,4.00%,0.97%。这证明改进提高了算法的精确度,使其检测出的目标中真正目标的比例增加,从而提高了精确率。HPXD的召回率为73.88%,对比Efficientdet,YOLOv5和YOLOv7分别提升了24.31%,10.48%,2.78%。这说明改进算法使检测器的召回能力增强,能检测出更多真实目标,进而提高了召回率。HPXD的mAP为81.20%,对比Efficientdet、YOLOv5和YOLOv7分别提升了19.16%,10.52%,2.74%。这说明改进使得算法在提升精确率与召回率之外,还保障了多次检测中不同场景的稳定性,检测效果更加均衡,因此mAP得到了明显提升。
| 类别/模型 | Efficientdet | YOLOv5 | YOLOv7 | HPXD |
| 精确率/% | 77.44 | 80.10 | 83.13 | 84.10 |
| 召回率/% | 49.57 | 63.40 | 71.10 | 73.88 |
| mAP/% | 62.04 | 70.68 | 78.46 | 81.20 |
HPXD的实际检测效果如图 10所示。HPXD可以准确地识别出X光下行李物品中的违禁品,对违禁品的位置和类别进行标注,并给出置信度。

|
| 图 10 HPXD在EDS数据集上的检测效果 Fig. 10 Detection effect of HPXD on EDS dataset |
| |
Grad-CAM[40]是一种用于解释CNN的可视化技术,它利用CNN最后一层的特征图和类别输出之间的权重,生成每个类别对应的特征图中的热力图。这些热力图可以直观地展示CNN是如何做出分类判断的。具体来说,热力图中颜色更亮的区域表示CNN对该区域的激活程度更高,即CNN认为该区域对分类判断更重要;颜色较暗的区域表示CNN对该区域的激活程度较低,对分类判断的重要性较小。从表 2中可以发现HPXD展现出了最高的检测精度,其次是YOLOv7。因此在特征可视化试验中同样选择与YOLOv7进行对比。
从图 11中可以观察到,由于改进了特征提取和目标判断能力,HPXD的热力图中激活区域会更加集中,表现为颜色更亮和更热的区域,并且更能正确匹配真实目标的空间范围,贴合物品形状。而从YOLOv7模型的热力特征图中可以发现,由于判断不够准确,其激活区域明显更加分散和广泛,包括大量非目标区域。在EDS数据集上和试验结果和特征可视化结果可以证明:对比Efficientdet、YOLOv5以及YOLOv7这些近年来被广泛使用的检测模型,HPXD有着最高的检测精度,能够准确地完成X光下行李物品中违禁品检测。

|
| 图 11 HPXD与YOLOv7在EDS数据集上的特征可视化对比 Fig. 11 Comparison of feature visualization between HPXD and YOLOv7 on EDS dataset |
| |
3.3.2 在VOC数据集上的对比试验
从表 2中可以发现,在mAP达到70%以上的模型中,HPXD展现出了最好的综合检测性能,其余依次是YOLOv7、YOLOv5。由于YOLOv5有着和YOLOv7近似的模型架构,且均为耦合检测头。因此在VOC数据集的模型泛化性对比试验中,我们选择将HPXD与YOLOv7模型进行对比,试验结果见表 3。HPXD的召回率为83.67%,对比YOLOv7提升了1.29%。mAP为89.09,对比YOLOv7提升了0.56%。精确率为85.52%,对比YOLOv7降低了2.20%,出现了精确率降低的情况。这是由于HPXD模型在EDS数据集的训练中过度拟合了X光下行李物品数据,学习到了EDS数据集相较于VOC数据集中的一些特征上的偏差,对其他未出现的物品类别的泛化检测能力变差。即对特定目标的过度集中,而丢失了其他目标的判别能力,导致对非集中目标的检测精确率下降。但这并不意味着模型的性能出现了问题。在我们的设想中,目标检测模型应该更倾向于将更多的样本预测为正样本(即提高召回率),而这可能导致一些负样本被错误地预测为正样本(即降低精确率)。这种权衡取决于具体的任务需求和场景特点。通过试验数据可以观察到,模型在保持较高精确率的基础上进一步提升了召回率。在实际应用中,漏检(False Negative)的代价往往大于误检(False Positive),因为漏检可能导致重要的目标被忽略,而误检则只是引入了额外的干扰信息,即能够识别出大部分的违禁品。相比之下,虽然精确率也是评价分类器性能的重要指标之一,但在目标检测任务中,即使精确率很高,如果召回率降低,那么模型仍然会漏检关键目标,导致实际应用效果不佳。因此,这种权衡对于实际应用来说是有益的,因为它减少了不必要的干预和误报,同时保持了较高的检测率。
| 类别/模型 | YOLOv7 | HPXD |
| 精确率/% | 87.72 | 85.52 |
| 召回率/% | 82.38 | 83.67 |
| mAP/% | 88.53 | 89.09 |
表 3的试验结果充分证明HPXD在VOC数据集上具有良好的泛化性能,能够在较高的检测精度前提下完成大多数物体的检测。
3.3.3 消融试验在EDS数据集上对HPXD进行消融试验的结果见表 4。试验中的基准模型(Baseline)不包含其他模块,其精确率为83.13%,召回率为70.65%,mAP为78.45%。使用α-IoU作为定位损失函数后,精确率提升了2.51%,召回率提升了0.44%,mAP提升了0.40%。因此可以认为改进α-IoU损失函数能缓解正负样本不均衡,实现灵活的训练策略。使用Merge-NMS作为非极大值抑制方式后,其精确率降低了0.73%,其召回率提升了2.65%,mAP提升了0.82%,因此可以认为这样的改进能提高检测精度,降低漏检率,实现自适应的过滤策略。在检测头中使用SimCSPSPPF后,其精确率降低了1.54%,召回率提升了3.83%,mAP提升了2.28%。增加CBAM注意力机制模块后,其精确率降低了1.55%,召回率提升了2.87%,mAP提升了0.72%。因此可以认为这样的改进能提升关键特征的权重,使模型聚焦于图像中的关键信息,去除边缘背景信息。
| 方式 | 精确率/% | 召回率/% | mAP@.5/% |
| Baseline | 83.13 | 72.41 | 78.45 |
| +α-IoU | 85.64 | 69.89 | 78.85 |
| +CBAM | 81.98 | 73.52 | 79.17 |
| +Merge-NMS | 82.40 | 73.30 | 79.27 |
| +SimCSPSPPF | 81.59 | 74.48 | 80.73 |
4 结论
本研究围绕X光下违禁品检测开展研究,提出一种新的X光下违禁品检测方法HPXD,方法包括HPCDNet骨干网络和X-head融合检测头两个主要结构。通过在网络中融合CBAM多尺度注意力机制,使图像特征信息的提取效率增高,改善了HPXD的检测效果。通过改进上采样方法,提升了模型的表达能力,进而降低模型的计算量。同时通过改进非极大值抑制方式与空间卷积池化金字塔,提高了检测模型的检测准确率。在EDS数据集上的试验结果表明,HPXD实现了同比最高的综合检测性能,其mAP达到了81.20%。对比其他被广泛使用的先进模型最低提升2.74%,平均提升达到10.81%。同时还保证了EDS数据集中绝大多数单项物品的平均检测精度。HPXD在VOC数据集上同样达到了最高的检测精度,这表明了HPXD的高泛化性能。
面向未来,X光下违禁品检测技术还有很大的提高空间。一方面,可以设计更高精度的检测模型,增强对其他形态违禁品的识别能力,例如液态或凝固态。另一方面,可以通过优化图像处理过程,更准确提取违禁品的特征信息,提升模型的检测速度。持续的技术进步以及模型的可靠性和可解释性研究将使该领域朝着更智能化、自动化和全面化方向发展。
| [1] |
WELLS K, BRADLEY D A. A Review of X-ray Explosives Detection Techniques for Checked Baggage[J].
Applied Radiation and Isotopes, 2012, 70(8): 1729-1746.
DOI:10.1016/j.apradiso.2012.01.011 |
| [2] |
MERY D, SAAVEDRA D, PRASAD M. X-ray Baggage Inspection with Computer Vision: A Survey[J].
IEEE Access, 2020, 8: 145620-145633.
DOI:10.1109/ACCESS.2020.3015014 |
| [3] |
LI J, LIU Y, CUI Z. Segmentation and Attention Network for Complicated X-ray Images[C]//2020 35th Youth Academic Annual Conference of Chinese Association of Automation. Zhanjiang: IEEE, 2020: 727-731.
|
| [4] |
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-cnn[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
|
| [5] |
XIANG N, GONG Z, XU Y, et al. Material-aware Path Aggregation Network and Shape Decoupled SIoU for X-ray Contraband Detection[J].
Electronics, 2023, 12(5): 1179.
DOI:10.3390/electronics12051179 |
| [6] |
RAFIEI M, RAITOHARJU J, IOSIFIDIS A. Computer Vision on X-ray Data in Industrial Production and Security Applications: A Comprehensive Survey[J].
IEEE Access, 2023, 11: 2445-2477.
DOI:10.1109/ACCESS.2023.3234187 |
| [7] |
ZHU Y, ZHANG Y, ZHANG H, et al. Data Augmentation of X-ray Images in Baggage Inspection Based on Generative Adversarial Networks[J].
IEEE Access, 2020, 8: 86536-86544.
DOI:10.1109/ACCESS.2020.2992861 |
| [8] |
FENG Q H, XU X Z, WANG Z X. Deep Learning-Based Small Object Detection: A Survey[J].
Mathematical Biosciences and Engineering, 2023, 20(4): 6551-6590.
DOI:10.3934/mbe.2023282 |
| [9] |
ZHU X, LYU S, WANG X, et al. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 2778-2788.
|
| [10] |
TAO R, LI H, WANG T, et al. Exploring Endogenous Shift for Cross-domain Detection: A Large-scale Benchmark and Perturbation Suppression Network[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 2115-2116.
|
| [11] |
PINHEIRO P O, COLLOBERT R. From Image-level to Pixel-level Labeling with Convolutional Networks. [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1713-1721.
|
| [12] |
胡剑琇, 朱前坤, 张琼, 等. 基于智能手机的城市道路车辆即时识别[J]. 公路交通科技, 2023, 40(1): 208-217. HU Jian-xiu, ZHU Qian-kun, ZHANG Qiong, et al. Real-time Recognition of Vehicle on Urban Road Based on Smart Phone[J]. Journal of Highway and Transportation Research and Development, 2023, 40(1): 208-217. |
| [13] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
|
| [14] |
GIRSHICK R. Fast R-cnn [C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448.
|
| [15] |
REN S, HE K, GIRSHICK R, et al. Faster R-cnn: Towards Real-time Object Detection with Region Proposal Networks[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149.
|
| [16] |
LIN, TSUNG-Yi. Focal Loss for Dense Object Detection. [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
|
| [17] |
TAN M, PANG R, QUOC V Le. Efficientdet: Scalable and Efficient Object Detection. [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10781-10790.
|
| [18] |
GE Z, LIU S, WANG F, et al. Yolox: Exceeding Yolo Series in 2021[EB/OL]. [s. n. ](2021-8-6)[2023-7-15]. https://arxiv.org/abs/2107.08430.
|
| [19] |
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable Bag-of-freebies Sets New State-of-the-art for Real-time Object Detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 7464-7475.
|
| [20] |
ZHOU X, KOLTUN V, KRÄHENBVHL P. Tracking Objects as Points. [C]//In European Conference on Computer Vision. Glasgow: ECCV, 2020: 474-490.
|
| [21] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[J].
Advances in Neural Information Processing Systems, 2017, 30.
DOI:10.48550/arXiv.1706.03762 |
| [22] |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-End Object Detection with Transformers[C]//European Conference on Computer Vision. Glasgow: IEEE, 2020: 213-229.
|
| [23] |
HU H, BAI S, LI A, et al. Dense Relation Distillation with Context-aware Aggregation for Few-shot Object Detection [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtu: IEEE, 2021: 10185-10194.
|
| [24] |
LI S, HE C, LI R, et al. A Dual Weighting Label Assignment Scheme for Object Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 9387-9396.
|
| [25] |
冯凤江, 杨增刊. 基于图卷积和注意力机制的高速公路交通流预测[J]. 公路交通科技, 2023, 40(9): 215-223. FENG Feng-jiang, YANG Zeng-kan. Expressway Traffic Flow Forecast Based on Graph Convolution and Attention Mechanism[J]. Journal of Highway and Transportation Research and Development, 2023, 40(9): 215-223. DOI:10.3969/j.issn.1002-0268.2023.09.025 |
| [26] |
GUO M, XU T, LIU J, et al. Attention Mechanisms in Computer Vision: A Survey[J].
Computational Visual Media, 2022, 8(3): 331-368.
DOI:10.1007/s41095-022-0271-y |
| [27] |
MNIH V, HEESS N, GRAVES A. Recurrent Models of Visual Attention[J].
Advances in Neural Information Processing Systems, 2014, 27(2): 2204-2212.
|
| [28] |
HU J, SHEN L, SUN G. Squeeze-and-excitation Networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
|
| [29] |
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional Block Attention Module[C]//Proceedings of the European Conference on Computer Vision. Munich: ECCV, 2018: 3-19.
|
| [30] |
HOU Q, ZHOU D, FENG J. Coordinate Attention for Efficient Mobile Network Design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtu: IEEE, 2021: 13713-13722.
|
| [31] |
IOFFE S, SZEGEDY C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[C]//International Conference on Machine Learning. Lille: IMLS, 2015: 448-456.
|
| [32] |
DING X, ZHANG X, MA N, et al. Repvgg: Making Vgg-style Convnets Great Again[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Virtu: IEEE, 2021: 13733-13742.
|
| [33] |
LI C, LI L, GENG Y, et al. YOLOv6 v3.0: A Full-Scale Reloading[EB/OL]. [s. n. ](2022-9-7)[2023-7-15]. https://arxiv.org/abs/2209.02976.
|
| [34] |
VIOLA P, JONES M. Rapid Object Detection Using a Boosted Cascade of Simple Features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai: IEEE, 2001, 1: I-I.
|
| [35] |
CAI Z, VASCONCELOS N. Cascade R-cnn: Delving into High Quality Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6154-6162.
|
| [36] |
REN J, CHEN X, LIU J, et al. Accurate Single Stage Detector Using Recurrent Rolling Convolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 5420-5428.
|
| [37] |
谭云峰, 刘昆, 莫洪柳, 等. 基于优化U-Net的路面裂缝分割及其影响因素研究[J]. 公路交通科技, 2023, 40(12): 17-25. TAN Yun-feng, LIU Kun, MO Hong-liu, et al. Study on Pavement Crack Segmentation and Its Influencing Factors Based on Optimized U-Net[J]. Journal of Highway and Transportation Research and Development, 2023, 40(12): 17-25. DOI:10.3969/j.issn.1002-0268.2023.12.003 |
| [38] |
HE J, ERFANI S, MA X, et al. α-IoU: A Family of Power Intersection Over Union Losses for Bounding Box Regression[J].
Advances in Neural Information Processing Systems, 2021, 34: 20230-20242.
|
| [39] |
ZHAO Z Q, ZHENG P, XU S, et al. Object Detection with Deep Learning: A Review[J].
IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(11): 3212-3232.
DOI:10.1109/TNNLS.2018.2876865 |
| [40] |
SELVARAJU R R, COGSWELL M, Das A, et al. Grad-cam: Visual Explanations from Deep Networks Via Gradient-based Localization[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE 2017: 618-626.
|