 2024, Vol. 41
2024, Vol. 41扩展功能
文章信息
- 蔡锦程, 许子彦, 董振勇, 徐荣桥, 赵阳.
- CAI Jin-cheng, XU Zi-yan, DONG Zhen-yong, XU Rong-qiao, ZHAO Yang
- 基于机器学习的砂浆流变特性预测
- Predictive Analysis on Mortar Rheological Property Based on Machine Learning
- 公路交通科技, 2024, 41(6): 138-147
- Journal of Highway and Transportation Research and Denelopment, 2024, 41(6): 138-147
- 10.3969/j.issn.1002-0268.2024.06.015
-
文章历史
- 收稿日期: 2023-10-23

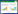



2. 浙江交工路桥建设有限公司, 浙江 杭州 310051;
3. 数智养护浙江省工程研究中心, 浙江 杭州 310051
2. ZCCC Road and Bridge Construction Co., Ltd., Hangzhou, Zhejiang 310051, China;
3. Zhejiang Provincial Engineering Research Center for Digital and Smart Maintenance of Highway, Hangzhou, Zhejiang 310051, China
随着复杂地质条件下建造的大型桥梁不断增多,具有更大承载能力的超大直径和超大桩长的钻孔灌注桩基础也在不断出现,导致灌注混凝土的方量、时间和质量控制难度都远超常规尺寸灌注桩基础,这对混凝土的施工性能提出了更高的要求。在桩基础灌注过程中,混凝土必须同时具有良好的流动性和足够的抗离析性,以防止灌注桩出现断桩等质量问题[1]。因此研究混凝土流变性随时间的变化是确保大直径钻孔灌注桩混凝土施工性能的重要内容。
混凝土的流变性是由砂浆级配、混合料尺寸和温度等因素决定的,所以在适当的条件下,可以通过砂浆的流变性能来反映混凝土的流变特性[2-5]。如今,随着环保意识的增强,天然河砂的开采逐渐减少,机制砂在工程中得到了越来越多的使用,因此有必要对机制砂配制的混凝土流变性进行研究[6]。
砂浆的流变特性十分复杂,它随其微观结构、水泥水化、自由水含量、温度、混合物之间的相互作用而发生变化。传统的统计方法试图建立分析方程,以预测砂浆的流变性能[2]。然而,这些分析方程仅在有限的材料成分范围内有效,对于时间、温度乃至添加剂都十分敏感。此外,对于施工方来说,需要进行大量的砂浆黏度试验以获得砂浆的流变性能,这将消耗大量的时间和成本,并不适用于建筑工地的实际条件[7]。
机器学习(machine learning,ML)作为一种现代数据处理的方法,从所提供的数据中自动的归纳逻辑或规则,并根据这个归纳的结果与新数据进行预测或者分类[8]。该方法擅长理解材料属性之间的复杂关系,为复杂材料特性建模提供了一种可行且优越的替代传统统计的方法[9]。因此,机器学习越来越多地被应用于解决混凝土领域的复杂问题。
本研究以砂浆的流变性能为研究对象,采用ML整合砂浆的数据信息进行建模,预测其屈服应力与塑性黏度。提取砂浆的配合比以及物理参数作为影响因素,将其作为训练样本送入回归模型中,形成砂浆流变性预测模型。本研究使用了多种机器学习模型,如随机森林回归(Random Forest Regressor, RFR)[10]模型、支持向量回归(Support Vector Regression, SVR)[11]模型、K-近邻回归(K-Nearest Neighbor, KNN)[12]模型,并对训练后的每个ML模型的性能进行了评估并作对比分析。使用回归模型进行参数分析,以研究每个主要输入特征的影响程度,并探讨机器学习的建模效果和预测精度。
1 模型介绍 1.1 宾汉姆模型常见的非牛顿流体可以分为时变性非牛顿流体和非时变性牛顿流体,其中非时变性牛顿流体的塑性黏度只和剪切应变有关,这类流体主要由宾汉姆流体、胀塑性流体以及假塑性流体组成。宾汉姆模型(Bingham Model)在工业中广泛应用,对一些高浓度的悬浮液,如淤泥、新拌水泥砂浆、新拌混凝土等,在适当的条件下可表现出宾汉姆流体的行为特点。本研究采用宾汉姆流体描述砂浆的流变性能,其宾汉姆流变方程为[13-14]:
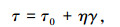
|
(1) |
式中,τ为剪切应力;τ0为屈服应力;η为塑性黏度;γ (1/s)为剪切速率。
1.2 机器学习模型 1.2.1 随机森林回归模型随机森林回归(RFR)是一种基于决策树的算法,其中决策树也称为回归树,是由Breiman等[10]首先提出的分类与回归的方法。随机森林是利用重抽样(Bootstrap)方法从数据集中抽取样本,并在随机采样的子样本上进行训练。
由于RFR[15]采用重抽样和随机特征抽样技术,所以模型一般不会受到输入特征之间多重共线性的影响,能够处理较高维度的数据,并且不用做特征选择。而对于非线性关系的数据,具有较强的拟合能力[16]。
1.2.2 支持向量机回归模型支持向量机回归是建立在结构风险最小化原理的机器学习方法,广泛应用于超平面分类器的分类问题和回归分析。支持向量机最初由Cortes & Vapnik[11]开发用于解决分类问题,拓展后可解决回归问题。
本质上,SVR[17]是一种将输入数据映射到更高维空间的技术。各种核函数,例如多项式函数、径向基函数,可用于将原始输入变换到不同的高维空间,所以该模型对高维数据具有较好的拟合效果。
1.2.3 K-邻近回归模型K-近邻回归(KNN)算法[12],是一个将样本置入特征空间中,通过特征空间最邻近来实现分类和回归的机器学习算法。样本空间中数据点的距离表示数据点的相似程度,模型会从训练数据集中选择离该数据点最近的k个数据点,并把y值取均值,将该均值作为新数据点的预测值。
该模型最大的优势是通过邻近样本进行学习,无需做复杂的训练,就能处理非线性问题。但当样本数较少时,对高维数据的处理效果精度会下降。
2 流变参数试验 2.1 材料配比水泥采用P·O 42.5普通硅酸盐水泥,其3 d和28 d抗压强度分别为18 MPa和42.8 MPa;砂为0~4.75 mm机制砂,细度模数为2.6;粉煤灰为F类Ⅱ级粉煤灰,28 d活性指数为85%;矿粉为S95石灰石矿粉,流动度比为98%,28 d活性指数为96%;减水剂采用液态聚羧酸高性能减水剂;水为纯净自来水。
为了对比不同配合比砂浆的流变性能,根据不同材料掺量的变化共设计了30组砂浆配合比见表 1。其中,砂浆的水灰比为0.4,0.45,0.5,0.54和0.57。骨胶比分别为0.6,0.8,1.0,1.1和1.2。矿粉和粉煤灰的掺量分别为5%,7.5%,10%,15%和20%。减水剂为0.1%,0.15%,0.2%,0.3%,0.4%,0.45%。
| 序号 | 水灰比 | 骨胶比 | 矿粉/% | 粉煤灰 | 减水剂/% | 序号 | 水灰比 | 骨胶比 | 矿粉/% | 粉煤灰 | 减水剂/% | |
| 1 | 0.40 | 0.8 | 0 | 0 | 0 | 16 | 0.50 | 1.00 | 15 | 0 | 0 | |
| 2 | 0.45 | 0.8 | 0 | 0 | 0 | 17 | 0.57 | 1.00 | 20 | 0 | 0 | |
| 3 | 0.50 | 0.8 | 0 | 0 | 0 | 18 | 0.54 | 1.00 | 0 | 10 | 0 | |
| 4 | 0.40 | 1.2 | 0 | 0 | 0.3 | 19 | 0.50 | 1.00 | 0 | 15 | 0 | |
| 5 | 0.40 | 1.2 | 0 | 0 | 0.15 | 20 | 0.57 | 1.00 | 0 | 20 | 0 | |
| 6 | 0.40 | 1 | 0 | 0 | 0 | 21 | 0.50 | 1.00 | 5 | 5 | 0 | |
| 7 | 0.40 | 0.6 | 0 | 0 | 0 | 22 | 0.50 | 1.20 | 7.5 | 7.5 | 0.1 | |
| 8 | 0.40 | 1.2 | 0 | 0 | 0.45 | 23 | 0.50 | 1.20 | 10 | 10 | 0.1 | |
| 9 | 0.45 | 1.2 | 10 | 0 | 0.2 | 24 | 0.50 | 1.20 | 10 | 5 | 0.2 | |
| 10 | 0.45 | 1.2 | 15 | 0 | 0.2 | 25 | 0.50 | 1.20 | 5 | 10 | 0.2 | |
| 11 | 0.45 | 1.2 | 20 | 0 | 0.2 | 26 | 0.50 | 1.20 | 10 | 0 | 0.1 | |
| 12 | 0.45 | 1.2 | 0 | 10 | 0.2 | 27 | 0.50 | 1.20 | 0 | 10 | 0.1 | |
| 13 | 0.45 | 1.2 | 0 | 15 | 0.2 | 28 | 0.54 | 1.10 | 5 | 5 | 0.1 | |
| 14 | 0.45 | 1.2 | 0 | 20 | 0.2 | 29 | 0.54 | 1.10 | 5 | 5 | 0.15 | |
| 15 | 0.54 | 1.0 | 10 | 0 | 0 | 30 | 0.54 | 1.10 | 5 | 5 | 0.2 |
2.2 试验方法
目前,测量砂浆流变性能的方法,主要分为间接测量和直接测量两种方式。间接测量的方法主要是采用坍落度法、L型箱试验法和V型漏斗法间接测量出砂浆的流变特性。直接测量法主要通过流变仪,将扭矩T和转速N转换成剪切应力τ和剪切速率γ,绘制出该材料的流变曲线图,通过流变模型直接获取材料的流变特性[18]。
屈服应力和黏性常数可分别由式(2)和式(3)表达。
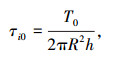
|
(2) |
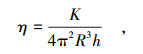
|
(3) |
式中,τi0为界面屈服应力;η为黏性常数;T0为转矩的初始值;R和h分别为圆柱体的半径和高度;K为线性系数。
本研究共设计了30组砂浆配合比,考虑到时间对砂浆流变性能的影响,每组砂浆浆体搅拌后间隔0.5 h测试一次流变性能,即对砂浆搅拌后的0,0.5 h,1 h和1.5 h进行测试,30组砂浆将得到120条流变数据。因为砂浆流变性可能受到搅拌步骤和设备的影响,且需要获得可重复的试验结果,所以每组砂浆将使用相同的搅拌机和相同的集料搅拌顺序。同一组砂浆搅拌后将分为4个样品,分别对应4个不同的时段[19]。完成流变试验后废弃已剪切的样品,以确保重复试验样品之间具有相同的剪切历史。
水泥砂浆的流变性能采用MARS iQ Air型流变仪测定。流变试验的转子速度如图 1所示。首先剪切速率由0~20 s,对砂浆进行预剪切,随后降为0。在这之后剪切速度随时间梯度变化,并开始记录砂浆的流变性能,剪切速率从5 s逐步增加到40 s,然后剪切速率从40 s逐步降低到5 s。每一梯度剪切时间均保持10 s,以达到平衡状态。为了避免搅拌过程中的热量损失或增加,用于搅拌和测试的所有设备都保持在相同温度下。流变试验结束后,检查圆筒中的砂浆,观察砂浆是否有明显的沉降。

|
| 图 1 转子剪切速率 Fig. 1 Rotor shear rate |
| |
3 研究方法 3.1 机器学习训练过程
本研究将通过3个机器学习模型对数据进行训练,训练过程包括训练测试数据集分割、特征缩放、以及通过交叉验证进行超参数的优化调整。模型的训练和评估遵循图 2所示的程序,本节将详细说明整个程序的组成部分,分为数据集划分、特征缩放以及超参数优化3个部分进行讨论。

|
| 图 2 机器学习仿真流程 Fig. 2 Simulation process of machine learning |
| |
试验在MatlabR2021b软件平台上完成,试验PC的系统为Windows11,处理器为IntelCorei5-1135G7,内存为32 GB,显卡为RTX3060Ti独立显卡。
3.2 砂浆流变性能数据集为了构建机器学习模型,以研究砂浆混合料成分与屈服应力和塑性黏度这两个变量的关系。通过流变仪对砂浆进行流变性能检测,采用宾汉姆模型计算流变参数,改变砂浆成分以及时间来研究其对流变参数的影响。
使用的数据库总共包含120条砂浆流变性数据。图 3显示了每个原始特征(水泥含量、机制砂、粉煤灰、石灰石矿粉、减水剂、水和砂浆混合后时间)和屈服应力之间的统计分布。图 4显示了每个原始特征和塑性黏度之间的统计分布。

|
| 图 3 原始特征与屈服应力的统计分布 Fig. 3 Statistics on primitive features and yield stress |
| |

|
| 图 4 原始特征和塑性黏度的统计分布 Fig. 4 Statistics on primitive features and plastic viscosity |
| |
就砂浆流变性能而言,其屈服应力主要在50~200 Pa的范围内,而塑性黏度主要在2~15 Pa·s。
为了进一步提供更多可能有助于机器学习模型训练的信息,故引用了可能与砂浆流变特性相关的3个二次特征(水灰比、骨胶比以及水胶比),3个二次特征对于砂浆塑性黏度与屈服应力的统计分布如图 5和图 6所示。

|
| 图 5 二次特征和屈服应力的统计分布 Fig. 5 Statistics on secondary feature and yield stress |
| |

|
| 图 6 二次特征和塑性黏度的统计分布 Fig. 6 Statistics on secondary feature and plastic viscosity |
| |
3.3 特征缩放
为了训练和验证预测模型,将120个样本组成数据集分为训练集和测试集,第1部训练集有96个数据,占总数据的80%;第2部分为测试集,有24个数据,占总数据的20%。由于不同的输入特征可能具有不同的尺度,并且不同特征的变化范围也不一样,因此在机器学习算法中,对所有输入特征的范围进行标准化以使每个特征的贡献近似成比例通常是有益的。故将收集到的数据集通过Z-score进行标准化。
散点图说明了影响变量(水泥含量、机制砂、粉煤灰、石灰石矿粉、减水剂、水、砂浆混合后时间、水灰比、骨胶比以及水胶比)与屈服应力和塑性黏度的模型变量之间的相关性,正如在这些散点图中可以观察到的那样,每对影响变量和输出之间存在弱的线性相关性。对于单个输入特征的统计分析是有助于解释之后章节中训练的机器学习模型,通过二次特征的引入,也将数据集中更深层的信息表达出来,表 2总结了数据集中变量的基本特征。
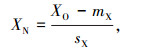
|
(4) |
| 成分 | 最小值 | 最大值 | 标准差 | 平均值 | 偏度 |
| 水泥 | 488.37 | 866.67 | 116.06 | 598.80 | 0.98 |
| 砂 | 520.00 | 840.00 | 68.42 | 701.25 | ―0.18 |
| 粉煤灰 | 0.00 | 162.79 | 54.00 | 38.45 | 0.97 |
| 矿粉 | 0.00 | 162.79 | 54.00 | 38.45 | 0.97 |
| 减水剂 | 0.00 | 5.47 | 2.05 | 1.78 | 0.52 |
| 水 | 220.00 | 400.00 | 42.69 | 278.51 | 1.11 |
| 混合时间 | 0.00 | 1.50 | 0.56 | 0.75 | 0.00 |
| 水灰比 | 0.40 | 0.57 | 0.05 | 0.47 | 0.22 |
| 骨胶比 | 0.60 | 1.20 | 0.16 | 1.05 | ―1.08 |
| 水胶比 | 0.36 | 0.50 | 0.03 | 0.41 | 0.76 |
式中,XN和XO分别为归一化变量和原始变量;mX为原始变量的均值;sX为原始变量的标准差。
在本研究中,由于每个特征都不遵循特定的分布,故所有的特征都会被缩放到一个统一的范围内,以便后续数据的研究。
3.4 超参数优化策略机器学习中,超参数是在开始学习过程之前设置值的参数,它是控制学习过程的关键。所以必须对它进行调整,以便模型能够最优地解决问题。超参数优化即找到一个超参数元组,该元组产生一个最优模型,该模型可使数据集上的预定义损失函数最小化。
本研究采用两步超参数优化策略。首先,对于每个超参数(数值或分类)选择更宽范围的取值,为超参数组合创造了很大的空间。通过网格搜索方法进行随机搜索,在每一个可能的超参数组合上拟合模型并记录模型的性能,找到具有最佳超参数的学习模型。
而为了估计模型的泛化性能,本研究使用了5倍交叉验证,砂浆数据集被拆分为5个数据组。抽取4个数据组作为训练集,剩余1个数据组用作验证集。为了保证每个数据组的数据分布具有一致性,采用分层抽样法进行数据组划分,最后得到5个不同的训练集和验证集。使用同一超参数机器学习模型对数据进行训练,得到5个独立模型,并对模型结果进行平均处理,得到模型的最终性能。所获得的3个机器学习模型的优化超参数值列于表 3中。
| 模型 | 超参数 |
| SVR | Gamma=0.4, C=20, kernel function=’rbf’ |
| RFR | n_estimators=150, max_depth = 40, min_sample_split=6, min_sample_leaf = 4, max_features=’auto’ |
| KNN | K=4, best_weights=uniform, algorithm=auto, n_jobs=―1 |
4 模型性能评估 4.1 性能指标
本研究采用了4种常用的性能指标,来评估机器学习模型的性能,即均方根误差(RMSE)、平均绝对百分比误差(MAPE)、平均绝对误差(MAE) 和决定系数(R2)[20]。而在回归模型中由于对数据集进行随机打乱,导致训练出的回归模型会有一定差异,因此重复交叉验证步骤20次,用平均值来评价回归模型性能。RMSE,MAPE,MAE和R2具体计算方法如下。
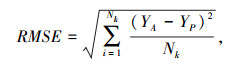
|
(5) |
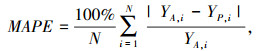
|
(6) |
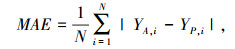
|
(7) |
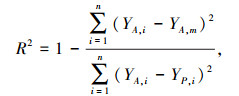
|
(8) |
式中,N为数据样本的数量;YA, i和YP, i为第i个数据样本的实际和预测输出; YA, m为真实观测值的平均值。
4.2 模型比较为了更好比较模型之间的差异,如图 7绘制了预测砂浆屈服应力和相应试验获得屈服应力之间的对应关系。图中做出了y=x的最佳拟合线,以及y=1.2x和y=0.8x的±20%误差区间。训练样本越接近最佳拟合线,预测就越准确,而训练样本在误差区间内越多,则代表模型拟合效果越好。

|
| 图 7 屈服应力预测数据与实际数据对比 Fig. 7 Comparison between predicted data and experimental data of yield stress |
| |
图 8绘制了预测砂浆塑性黏度和相应试验获得屈服应力之间的对应关系。SVR模型在测试数据集中±20%误差范围内有最高的稳定性,所以3个机器模型SVR模型的性能优于RFR和KNN模型。

|
| 图 8 塑性黏度预测数据与实际数据对比 Fig. 8 Comparison between predicted data and experimental data of plastic viscosity |
| |
从性能指标来看,就平均绝对百分比误差而言,机器学习模型的值均低于15%,机器学习模型对砂浆的流变性能有较好的预测效果。在3个模型中,SVR模型的整体性能优于RFR和KNN模型,SVR的4个指标都有较大的优势,预测R2均超过了92%且MAPE均低于10%,相较于KNN与RFR的性能有较大的优势。
4.3 特征重要程度砂浆的流变性能会随着砂浆不同特征的变化而发生改变[21],但每一个特征对砂浆的流变性能影响并不一致,因此可以通过机器学习的特征选择对砂浆每一个特征的重要性进行排序。
对于每个训练的机器学习模型,使用排列特征重要性的方法计算单个特征的重要性值。特征的排列重要性被定义为当特征被随机打乱时,模型性能(本研究中的R2)降低的程度。通过打乱特征,特征和目标之间的关系被打破,因此模型得分的下降表明了特征的重要性。
对于模型评估,当一个模型R2高于92%且MAPE低于15%时,通常认为该模型具有良好的准确性。对比随机森林回归、支持向量回归算法和K-近邻回归算的预测能力,每个模型的性能都通过上诉提到的指标进行了评估。模型指标列于表 4。
| 数据集 | 评估指标 | 屈服应力 | 塑性黏度 | |||||
| RFR Mean | SVR Mean | KNN Mean | RFR Mean | SVR Mean | KNN Mean | |||
| 训练集 | RMSE | 16.37 | 5.61 | 13.96 | 0.75 | 0.61 | 0.69 | |
| MAPE | 13.37 | 9.63 | 11.01 | 12.12 | 6.24 | 9.67 | ||
| MAE | 8.36 | 3.62 | 7.31 | 0.31 | 0.15 | 0.20 | ||
| R2 | 0.88 | 0.94 | 0.90 | 0.90 | 0.93 | 0.91 | ||
| 验证集 | RMSE | 20.28 | 9.64 | 15.34 | 1.15 | 0.60 | 0.66 | |
| MAPE | 14.72 | 6.72 | 12.85 | 11.21 | 4.95 | 7.32 | ||
| MAE | 8.10 | 4.13 | 7.21 | 0.28 | 0.10 | 0.16 | ||
| R2 | 0.85 | 0.92 | 0.88 | 0.85 | 0.92 | 0.90 | ||
综合了每个自变量在各个节点对于结果流变性能的重要程度,所有10个特征(7个原始特征和3个二次特征)的重要性如图 9所示,随着时间的发展,减水剂含量对于砂浆流变性能的影响最为显著,水泥、砂和水的含量对流变性能有着重要影响。

|
| 图 9 特征重要性排序 Fig. 9 Feature importance ranking |
| |
通过本研究所提出的机器学习方法以及试验的模拟数据,建立不同配比砂浆的试验数据库,即可对混凝土的流变性能进行预测。由于混凝土的流变性能可以由砂浆进行模拟,故所提出的方法可提高混凝土配合比的设计效率,节省配合比试验时间和成本。
4.4 参数研究机器学习模型可以被理解为将输入变量映射到输出变量的目标函数。尽管模型中的输入和输出并不像数学公式中那样明确,但可以通过参数研究来解释输入与输出的关系。在本研究中,使用机器学习模型对具有较大特征重要性的输入特征(水泥、机制砂以及减水剂)进行单一特征研究,绘制变量对砂浆流变性能的预测曲线,并与试验值进行比对,通过机器学习的方法解释其物理性能。
4.4.1 水泥含量对砂浆的流变性能影响通过只改变砂浆的水泥含量,如图 10(a)所示,随着砂浆中水泥含量的增大,其水灰比也随之减小,纯水泥砂浆的塑性黏度和屈服应力逐渐增大(当砂浆的水灰比从0.5降至0.4时,砂浆的屈服应力从27.1 Pa上升至144.5 Pa,塑性黏度从0.69 Pa·s上升至4.31 Pa·s)。这是因为砂浆所含的游离水减少,使得浆体变稠,砂浆各组分颗粒间的摩擦阻力增大,因此其流变参数增大。

|
| 图 10 砂浆流变性能影响预测曲线 Fig. 10 Predictive curves for influence on mortar rheological properties |
| |
4.4.2 砂含量对砂浆的流变性能影响
通过只改变砂浆的砂含量,如图 10(b)所示,随着砂浆中水泥含量的增加,骨胶比增大,纯水泥砂浆的塑性黏度和屈服应力均增长(当砂浆的骨胶比从0.6上升至1.0时,砂浆的屈服应力从114.1 Pa上升至226.3 Pa,塑性黏度从2.55 Pa·s上升至6.38 Pa·s),流动度减小。这是因为在水泥砂浆中水泥用量不变的情况下,含砂量增大,其砂浆的游离水减少,包裹砂粒表面的水泥浆体减少,颗粒间的摩擦力增大,故其流变参数增大。
4.4.3 减水剂含量对砂浆的流变性能影响通过只改变砂浆的减水剂含量,如图 10(c)所示,随着减水剂掺量的增加,砂浆的屈服应力和塑性黏度均降低(当砂浆的减水剂掺量从0上升至0.2%时,砂浆的屈服应力160 Pa下降至20.51 Pa,塑性黏度从8.05 Pa·s下降至1.21 Pa·s)。这是因为减水剂掺入砂浆后可吸附在水泥颗粒的表面,由于减水剂的分散作用和润滑作用,砂浆中的絮凝结构被破坏,释放出被包裹的水,因而能够降低砂浆的屈服应力和塑性黏度,使其流变参数减小。
5 结论(1) 本研究提出了一种基于机器学习的方法来预测砂浆的屈服应力和塑性黏度。将砂浆拌和时间作为数据的指标,通过机器学习获得不同时间段下砂浆的流动性能,有效提升了砂浆流变性能早期预测的效率和可靠性。
(2) 采用3种机器学习回归模型(RFR,SVR,KNN)进行学习,结果表明,SVR模型对砂浆流变参数的预测值具有较高的精度。
(3) 基于机器学习的结果得到了砂浆集配中不同材料对于砂浆流变性的重要度排名,其中减水剂、水泥、砂、水对于砂浆的流变性能影响比较显著,粉煤灰和石灰石矿粉的影响则相对较小。
(4) 机器学习模型对砂浆流变特性预测的精度具有较高的水平,但当输入特征处于训练数据稀缺的范围内时,其解释和应用还需谨慎。本研究现阶段试验样本数据仍较有限,实际影响砂浆流变特性的因素还包括砂浆的拌和温度以及集料的微观结构等诸多因素,且部分材料具有较明显的地域特性,故将该方法应用于更广泛的区域还需要建立样本更加丰富、全面的数据集。
| [1] |
YE Q D, WANG J J, WANG C J. Application and Development of the Super-large Diameter Column Foundation of Bridge[J].
IOP Conference Series: Materials Science and Engineering, 2020, 758(1): 12021.
DOI:10.1088/1757-899X/758/1/012021 |
| [2] |
PETIT J, WIRQUIN E, VANHOVE Y, et al. Yield Stress and Viscosity Equations for Mortars and Self-consolidating Concrete[J].
Cement and Concrete Research, 2007, 37(5): 655-670.
DOI:10.1016/j.cemconres.2007.02.009 |
| [3] |
PETIT J, WIRQUIN E, KHAYAT K H. Effect of Temperature on the Rheology of Flowable Mortars[J].
Cement and Concrete Composites, 2010, 32(1): 43-53.
DOI:10.1016/j.cemconcomp.2009.10.003 |
| [4] |
杨钱荣, 赵宗志, 张庆钊, 等. 若干因素对水泥砂浆流变性能的影响[J]. 建筑材料学报, 2019, 22(4): 506-515. YANG Qian-rong, ZHAO Zong-zhi, ZHANG Qing-zhao, et al. Influence of Several Factors on Rehelogiacl Properties of Cement Mortar[J]. Journal of Building Materials, 2019, 22(4): 506-515. DOI:10.3969/j.issn.1007-9629.2019.04.002 |
| [5] |
GONCALVES J P, TAVARES L M, TOLEDO FILHO R D, et al. Comparison of Natural and Manufactured Fine Aggregates in Cement Mortars[J].
Cement and Concrete Research, 2007, 37(6): 924-932.
DOI:10.1016/j.cemconres.2007.03.009 |
| [6] |
缪昌文, 穆松. 混凝土技术的发展与展望[J]. 硅酸盐通报, 2020, 39(1): 1-10. MIAO Chang-wen, MU Song. Development and Prospect of Concrete Technology[J]. Bulletin of The Chinese Ceramic Society, 2020, 39(1): 1-10. |
| [7] |
GOLASZEWSKI J, KOSTRZANOWSKA-SIEDLARZ A, CYGAN G, et al. Mortar as a Model to Predict Self-compacting Concrete Rheological Properties as a Function of Time and Temperature[J].
Construction and Building Materials, 2016, 124: 1100-1108.
DOI:10.1016/j.conbuildmat.2016.08.136 |
| [8] |
何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014, 27(4): 328-336. HE Qing, LI Ning, LUO Wen-juan, et al. A Survey of Machine Learning Algorithms for Big Data[J]. PR&AI, 2014, 27(4): 328-336. |
| [9] |
郭赵元, 张慧, 郑俊秋, 等. 考虑不确定性的现场沥青混合料低温抗裂性能预测[J]. 公路交通科技, 2023, 40(5): 9-17, 43. GUO Zhao-yuan, ZHANG Hui, ZHENG Jun-qiu, et al. Prediction of Low-temperature Cracking Resistance of In-situ Asphalt Mixture Considering Uncertainty[J]. Journal of Highway and Transportation Research and Development, 2023, 40(5): 9-17, 43. DOI:10.3969/j.issn.1002-0268.2023.05.002 |
| [10] |
LEO B. Bagging Predictors[J].
Machine Learning, 1996, 24: 123-140.
|
| [11] |
CORINNA C, VLADIMIR V. Support-vector Networks[J].
Machine Learning, 1995, 20: 273-297.
|
| [12] |
PENROSE M D. Central Limit Theorems for K-nearest Neighbor Distances[J].
Stochastic Processes and Their Applications, 2000, 85(2): 295-320.
DOI:10.1016/S0304-4149(99)00080-0 |
| [13] |
高小建, 杨英姿. 混凝土早期性能与评价方法[M]. 哈尔滨: 哈尔滨工业大学出版社, 2021. GAO Xiao-jian, YANG Ying-zi. Performances and Evaluation Methods of Early Age Concrete[M]. Harbin: Harbin Institute of Technology Press, 2021. |
| [14] |
BANFILL P F G, TATTERSALL G H. The Rheology of Fresh Concrete[M].
Boston: Pitman Advanced Pub. Program, 1983.
|
| [15] |
LEO B. Random Forests[J].
Machine Learning, 2001, 45: 5-32.
DOI:10.1023/A:1010933404324 |
| [16] |
余婷, 裴莉莉, 李伟, 等. 基于随机森林算法的路面状况指数预测[J]. 公路交通科技, 2021, 38(10): 16-23. YU Ting, PEI Li-li, LI Wei, et al. Prediction of Pavement Surface Condition Index Based on Random Forest Algorithm[J]. Journal of Highway and Transportation Research and Development, 2021, 38(10): 16-23. DOI:10.3969/j.issn.1002-0268.2021.10.003 |
| [17] |
何昊, 贺福强, 谢丹, 等. 基于SVM和改进区域生长法的桥梁裂缝分割算法[J]. 公路交通科技, 2022, 39(11): 115-123. HE Hao, HE Fu-qiang, XIE Dan, et al. A Bridge Crack Segmentation Algorithm Based on SVM and Improved Region Growing Method[J]. Journal of Highway and Transportation Research and Development, 2022, 39(11): 115-123. DOI:10.3969/j.issn.1002-0268.2022.11.015 |
| [18] |
刘豫, 史才军, 焦登武, 等. 新拌水泥基材料的流变特性、模型和测试研究进展[J]. 硅酸盐学报, 2017, 45(5): 708-716. LIU Yu, SHI Cai-jun, JIAO Deng-wu, et al. Rheological Properties, Models and Measurements for Fresh Cementitious Materials- A Short Review[J]. Journal of the Chinese Ceramic Society, 2017, 45(5): 708-716. |
| [19] |
CAO G, ZHANG H, TAN Y, et al. Study on the Effect of Coarse Aggregate Volume Fraction on the Flow Behavior of Fresh Concrete via DEM[J].
Procedia Engineering, 2015, 102: 1820-1826.
|
| [20] |
WANG C, CHAN T. Machine Learning (ML) Based Models for Predicting the Ultimate Strength of Rectangular Concrete-filled Steel Tube (CFST) Columns Under Eccentric Loading[J].
Engineering Structures, 2023, 276: 115392.
|
| [21] |
WESTERHOLM M, LAGERLAD B, SILFWERBRAND J, et al. Influence of Fine Aggregate Characteristics on the Rheological Properties of Mortars[J].
Cement and Concrete Composites, 2008, 30(4): 274-282.
|