 2024, Vol. 41
2024, Vol. 41扩展功能
文章信息
- 陈娇娜, 陶伟俊, 靳引利.
- CHEN Jiao-na, TAO Wei-jun, JIN Yin-li
- 面向多模态数据的高速公路交通事故信息识别与评价
- Recognition and Evaluation on Expressway Traffic Accident Information Using Multimodal Data
- 公路交通科技, 2024, 41(4): 186-193, 213
- Journal of Highway and Transportation Research and Denelopment, 2024, 41(4): 186-193, 213
- 10.3969/j.issn.1002-0268.2024.04.019
-
文章历史
- 收稿日期: 2023-03-28



 ,
, 2. 长安大学 电子与控制工程学院, 陕西 西安 710061
2. School of Electronics and Control, Chang'an University, Shaanxi, Xi'an 710061, China
交通运输行业是社会生产活动和公众出行的重要保障,交通安全水平的重要作用也日趋显著。随着信息技术和管理水平的不断发展,更加丰富的交通事故信息被记录。交通事故信息是典型的多模态数据,从数据类型来看,既有人工录入的结构化字段和自然语言描述文本,又有系统自动记录的视频、音频等非结构化数据。从时间维度上看,随着事故演化或者处置推进,交通事故信息可能被多次记录,包含了从事故发现、响应、处置、恢复的各个阶段。
交通事故具有复杂性和随机性,难以被结构化字段完整表征。应急处置是影响交通事故持续时间、道路交通延误的关键环节,通常以自然语言形式被记录。自然语言处理技术在事故文本智能分析[1-3]中已经取得一定进展。Li等[4]回顾了深度学习技术在命名实体识别中的最新应用。王颖洁等[5]总结了中文命名实体识别研究中的关键问题,一些学者探讨了军事、航空等领域的命名实体识别效果[6-8],刘兴丽等[9]提出了适用于小样本命名实体识别的数据增强改进算法。张鹏翔[10]通过多维字符特征+BiLSTM+CRF模型实现了铁路设备事故报告中7类信息提取。韩广等[11]基于432条文本和十类铁路事故,建立了结合词向量和句向量双通道的WA-S-BiLSTM模型,王向前等[12]以239份煤矿事故案例文本为数据来源,构建了7种实体类型的ALBERT-Bi LSTM-CRF模型。刘婷等[13]通过1 000份报告设计了BERT-BiLSTM混合模型以识别8种水利工程事故原因。刘昭等[14]从微博平台爬取了近2 000条数据,采用XGBoost文本分类器识别交通突发事件。樊海玮等[15]采集了4 446条交通事故文本数据,构建了BERT-BiGRU-CRF模型提取地点、时间、原因、类型、交通方式、伤亡结果、道路类型7类信息。李昀轩等[16]对120 191条交通警情提取时间、地址和车牌信息,并提出了交通警情分类模型和语义分析方法。由此可知,由于实体类型、数据集规模、应用领域的异质性,事故文本实体识别尚未获得一致结论。同时,大多数研究重点分析了时间、地点、原因、类型等属性信息[17],对于处置阶段信息的提取尚未深入开展。在前期研究中验证了处置阶段信息对高速公路交通事故持续时间具有显著的调节效应[18]。因此,准确识别交通事故文本中的应急处置信息对应急响应效率和应急预案优化具有重要意义。
交通事故信息质量直接影响数据挖掘下游任务的效果。准确评估信息质量能够为应急处置、交通管制提供决策依据。在事故发现初期,完全掌握事故所有信息是不切实际的。随着事故演化,天气状况、道路条件等因素会发生变化,事故信息也可能在不同阶段被逐渐补充。同时,由于信息采集人员经验差异,可能产生属性划分的不准确、结构化数据与文本数据不一致等情况。针对交通事故信息所表现出的复杂、海量、多阶段等特性,有必要进行更深入的研究。目前应急信息质量评估理论尚待进一步完善,面向多模态交通事故数据的信息质量评价仍极具挑战性。朱益平等[19]建立政务微信公众号信息质量评价模型。徐文强等[20]从内容质量、描述质量和信息约束角度,构建大数据环境下的应急信息质量评估体系。GUO等[21]通过BiLSTM-CRF模型提取应急预案中信息发送、消息接收和常规任务3种类型,从响应层级关系、完整性、模糊性和冗余性对突发事件应急预案文本进行评价。
综上所述,交通事故命名实体识别研究中尚未深入涉及应急处置信息识别,且对于多模态的交通事故采集信息的质量评价,尚未形成有效结论。因此,建立一种基于预训练模型和深度学习网络的交通事故命名实体识别模型,同时,从两种模态数据的一致性和丰富性,提出交通事故信息内容评价指标,实现文本信息抽取结果与结构化数据的信息内容量化评价,是自然语言处理技术在交通应急安全领域的重要应用。研究成果可以定量评估运营管理中信息采集质量和有效性,进而为应急处置流程优化提供决策依据。
1 交通事故文本信息识别模型基于文本信息的交通事故命名实体识别模型由文本标注模块、预训练语言模块、双向长短时记忆(Bidirectional Long Short Term Memory,BiLSTM)模块和条件随机场(Conditional Random Field,CRF)模块构成。采用BIO标记法对交通事故文本进行标注;在预训练语言模块中使用双向Transformer编码结构实现文本序列的向量化表达,生成融合字向量、句向量以及位置向量的特征向量。将特征向量输入BiLSTM模型提取特征,运用CRF对BiLSTM输出的序列标注进行编码和制约,以最大概率的序列标注作为最终输出结果。
1.1 文本标注交通事故文本标注采用BIO标记法,其中B表示实体的开始,I表示实体的中间,O代表非实体。以表征动态演化和处置过程为业务需求,将实体分为事故位置、事故类型、事故描述和应急处置等方面,其中应急处置分为处置机构、处置设备、未处置、处置中、处置效果5个实体。通过BIO标记法分别定义各实体类别的标签,实体详细定义见表 1。
| 类型 | 序号 | 实体名称 | 实体开始标记 | 实体中间标记 | 文本示例 |
| 事故位置 | 1 | 城市 | B-CITY | I-CITY | 西安市,西安 |
| 2 | 高速公路 | B-FWAY | I-FWAY | 包茂高速,青银线,绕城 | |
| 3 | 收费站 | B-TS | I-TS | 六村堡,六村堡收费站 | |
| 4 | 服务区 | B-SA | I-SA | 秦岭,秦岭服务区 | |
| 5 | 桥梁 | B-BG | I-BG | 立交桥,大桥 | |
| 6 | 隧道 | B-TN | I-TN | 隧道 | |
| 7 | 匝道 | B-RM | I-RM | 匝道 | |
| 事故类型 | 8 | 主体类型 | B-TYPE1 | I-TYPE1 | 单方事故,多方事故 |
| 9 | 事故类型 | B-TYPE2 | I-TYPE2 | 剐蹭,擦挂 | |
| 事故描述 | 10 | 车辆类型 | B-VT | I-VT | 半挂,小车,危化品车 |
| 11 | 路产损失 | B-RL | I-RL | 有路损,路产待勘验 | |
| 12 | 伤亡人数 | B-IDR | I-IDR | 1人死亡1人受伤,驾驶人重伤 | |
| 13 | 影响车道数 | B-TD | I-TD | 占用应急车道,占用部分行车道 | |
| 环境交通分流 | 14 | 天气 | B-WT | I-WT | 小雨,大雨,雨 |
| 15 | 分流 | B-SP | B-SP | 分流 | |
| 应急处置 | 16 | 处置机构 | B-ROLE | I-ROLE | 高速交警,路政,养护部门 |
| 17 | 处置设备 | B-DVT | I-DVT | 吊车,拖车,救护车,清障车 | |
| 18 | 未处置 | B-MOTI | I-MOTI | 准备施救,待救援,正在赶往 | |
| 19 | 处置中 | B-MOTI2 | I-MOTI2 | 正在清理,临时管制 | |
| 20 | 处置效果 | B-EFF | I-EFF | 已清理,已拉走救治,已勘验完毕 | |
| 非实体 | 21 | 非实体 | O | O | — |
1.2 预训练语言模型
预训练语言模型显著提升了自然语言处理领域任务的当前最优结果(State of the Art,SOTA)表现,其中由谷歌在2017年提出的Transformer成为最主要的自然语言处理特征提取工具。BERT模型使用掩码语言模型(Masked Language Model,MLM)和下句预测(Next Sentence Prediction,NSP)实现文本字词特征的预训练。它将多个Transformer编码器堆叠提取特征,模型结构如图 1所示。在文本的开头和句子之间分别插入[CLS]和[SEP],采用字向量、句向量和位置向量的Embedding编码之和作为融合的特征向量。在文本序列的特征向量输入BERT模型之前,随机抽取15%的掩码词。对80%的样本用掩码标记[MASK]替换掩码词,对另外10%的样本不做任何替换,对最后10%的样本从模型词表中随机抽取单词来替换掩码词。利用大规模的语料数据进行自监督学习的训练,使得BERT模型能够正确预测这些被掩码词,以便获取输入文本数据中的语义信息。其中,[CLS]标签对应的输出向量记为C,其判断B句是否为A句的下一句。是,则输出1;否, 则输出0。TMask为预测的掩码词。

|
| 图 1 BERT模型结构 Fig. 1 Model structure of BERT |
| |
假设原始数据序列为 S ={S1, S2,…, Sn},n为样本字数。叠加并进行掩码操作后得到BERT模型输入为 E ={E1, E2,…, EN},N为组合后词向量维度。每个Transformer编码器由Self-attention层和前馈神经网络层组成。Self-attention是Transformer的核心机制。它将输入的词向量通过线性变换得到3组向量序列 Q,K,V。然后使用Softmax函数得到特征函数Attention(Q, K, V)。其计算过程如下:
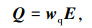
|
(1) |
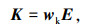
|
(2) |
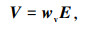
|
(3) |
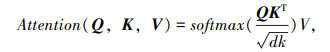
|
(4) |
式中,E为输入的词向量;wq,wk,wv分别为训练获得的权重矩阵;dk为词向量的维度。
重复多次相同的Transformer编码器后得到与 E ={E1, E2,…, EN}向量长度相同的输出向量 T ={T1, T2,…, TN},即为经过BERT模型预训练后的向量。
1.3 BiLSTM-CRF模型BiLSTM是自然语言处理领域应用较好的一种深度学习模型。采用BiLSTM模型对预训练后的文本向量T进行特征提取,采用CRF模型对网络输出结果进行条件约束,从而得到合理的实体类型预测结果。BiLSTM-CRF模型的结构如图 2所示。BiLSTM由前向LSTM层和后向LSTM层组成,获取输入信息在两个方向的上下文特征,然后使用Softmax函数给出每个词Ti对应每个预定义标签j的概率值pij。同时,在BiLSTM网络中加入了Dropout层避免过拟合现象。

|
| 图 2 BiLSTM-CRF模型结构 Fig. 2 Model structure of BiLSTM-CRF |
| |
LSTM设置3种门结构:遗忘门(Forget Gate)、输入门(Input Gate)与输出门(Output Gate),三者利用sigmoid激活函数(记为σ)的0-1门控特性对经过的信息进行筛选,通过有用的信息,阻挡无用的信息。LSTM通过记忆细胞状态Ct来构建长期依赖关系,通过隐含层状态ht来构建短期依赖关系。输入门It决定是否忽略输入数据,遗忘门Ft将值向0减少,输出门Ot决定是否使用隐含层状态。LSTM模型表示如下:
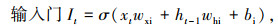
|
(5) |
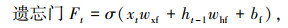
|
(6) |
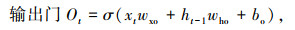
|
(7) |
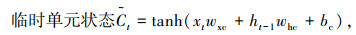
|
(8) |
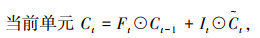
|
(9) |
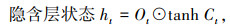
|
(10) |
式中,xt为当前输入;ht-1为前一时刻隐含层输出;wxi,whi,wxf,whf,wxo和who为权重;bi,bf,bo和bc为偏差;⊙为对应元素点乘;tanh函数的作用是保证值∈(― 1,1)。
最后将Bi LSTM层输出的隐藏层状态ht连接起来,形成特征向量 H。将 H作为Softmax函数的输入来预测标签。由于Softmax函数的输出值之间是相互独立的,可能存在不合理序列的情况。因此需要采用CRF模型,对BiLSTM的输出进行修正。CRF模型考虑了各个字标签之间的约束关系,通过各标签得分与标签之间的转移得分来计算不同标签的出现概率。选取出现概率最大的标签序列作为最优的预测结果。
令X={x1, x2,…, xn}为观测序列,y={y1, y2,…, yn}为与之相应的标记序列,则构建条件概率模型:
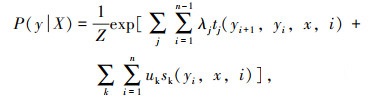
|
(11) |
式中,tj (yi+1, yi, x, i)为定义在观测序列的两个响铃标记位置上的转移特征函数,用于刻画相邻标记变量之间的相关关系以及观测序列对其影响;sk (yi, x, i)为定义在观测序列的标记位置i上的状态特征函数,用于刻画观测序列对标记变量的影响;λj和uk为参数;Z为规范化因子,用以确保式(11)是正确定义的概率。
1.4 模型评价指标对于第i个预定义的实体类别,采用准确率Pi、召回率Ri,F1i值作为模型的评价指标。准确率Pi描述正例预测准确程度,召回率Ri衡量模型识别真实正例的程度,F1值是准确率和召回率的调和平均值,F1∈ (0,1),越接近1模型效果越佳。计算式为:
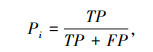
|
(12) |
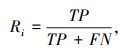
|
(13) |
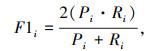
|
(14) |
式中,TP为真正例个数;FP为假正例个数;FN为假反例个数。
考虑各实体类别数量可能不均衡,采用加权的F1值作为模型的综合评价指标,计算式为:
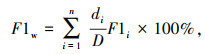
|
(15) |
式中,di为样本中第i类标签的数量;n为训练数据集中标签类别数;D为训练数据集中标签总数。
2 多模态交通事故信息内容评价 2.1 数据来源及预处理以陕西省高速公路2021年6月至2022年8月的交通事故数据集为数据来源,其中2021年6月至2022年5月为训练集,2022年6—8月为测试集。陕西省高速公路交通事故数据集中记录了交通事故的结构化属性,包括事故开始时刻、事故清除时刻、事故类型、受伤人数等,并保存了每次报送的自然语言文本。结合信息内容评价需求,根据数据集中属性的划分提取结构化字段如表 2所示。其中,交通事故持续时间定义为系统记录的事故开始时刻与事故清除时刻的时间差[17]。BIO标注后不同数据集规模如表 3所示。
| 类别 | 字段名称 | 数据类型 | 说明 |
| 持续时间 | duration | 定量 | 持续时间 |
| 事故基本信息 | vcType | 定类 | 事故类型,分为单方事故和多方事故两类 |
| Injured | 定量 | 受伤人数 | |
| Death | 定量 | 死亡人数 | |
| weather | 定类 | 天气,分为雾、雪、阴、雨、晴5类 | |
| loss | 定类 | 有路产损失,1;无路产损失,0 | |
| 交通分流 | diversion | 定类 | 采取分流,1;不采取分流,0 |
2.2 信息内容评价指标
信息内容是数据价值的体现,是数据质量评价的前提和关键性问题。以信息内容评价为目标,考虑应急信息质量的特点和需求,从多模态数据的一致性和信息描述的丰富性两个维度,对交通事故信息内容进行评价,指标定义见表 4。
| 一级指标 | 二级指标 | 计算来源 | 指标说明 |
| 一致性A | 一致性A1 | Data;Text | 数据库内逻辑的一致性以及不同模态数据间的一致性。 |
| 丰富性B | 应急处置占比B1 | Text | 应急处置实体类型在文本数据中占总体识别实体的比例。 |
| 变异性B2 | Text | 被识别出的各类命名实体数量的波动性。 |
令

|
表示结构化属性,Text={I1,…,Im}表示文本信息,式中,aij为第i条样本中第j个结构化属性;Ii为第i条样本的文本信息;n为属性个数;m为样本数。预定义的实体类别为K,交通事故实体识别结果为

|
式中,kij为第i条样本中第j个实体类型出现的频数。
(1) 一致性A1表征结构化数据与文本信息对相同内容要素记录的一致程度。计算式:
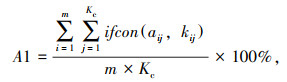
|
(16) |
式中,Kc为结构化数据记录的实体类型个数, Kc∈0, 1, 2,…, K;ifcon(aij, kij)为判断结构化数据aij与文本信息实体内容kij是否一致,若一致则为1,否则为0。若数据为空而导致无法比较时,记为0。
(2) 应急处置占比B1表征应急处置实体数量在样本实体数量的占比,计算式:
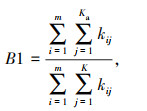
|
(17) |
式中Ka为实体类型中属于应急处置实体的个数。
(3) 变异性B2表示被识别的不同实体类型的分布情况,量化各要素在数据集中的波动程度。计算式为:
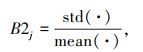
|
(18) |
式中,std(·)和mean(·)分别为各类型实体数量的均值和标准差。
3 实例分析 3.1 交通事故信息识别模型性能分析ALBERT和RoBERTa是两种BERT的改进模型。ALBERT模型是一种轻量级BERT,降低了内存和算力消耗,提高了训练速度。RoBERTa与BERT相比,在模型参数量、bacth size和训练数据上规模更大。采用相同的训练集和试验环境,比较BERT-BiLSTM-CRF,ALBERT-BiLSTM-CRF和RoBERTa-BiLSTM-CRF这3种深度学习模型的识别结果。以式(15)的加权F1值评价每个模型的性能,保存多次训练中性能较优的模型作为最终识别模型。
SET0表示原始的测试集,SET1~SET5表示相同样本量、有放回抽样的测试集。同时,以陕西交通微博为语料来源,采用网络爬虫随机获取2 000条文本信息作为袋外测试集,分析模型对“新”数据的识别效果,检验模型的鲁棒性。各深度学习模型的性能如表 5所示。
| 测试集编号 | 测试集 | 袋外测试集 | |||||
| BERT-BiLSTM-CRF | RoBERTa-BiLSTM-CRF | ALBERT-BiLSTM-CRF | BERT-BiLSTM-CRF | RoBERTa-BiLSTM-CRF | ALBERT-BiLSTM-CRF | ||
| SET 0 | 96.989 6 | 97.115 4 | 76.919 4 | 71.989 8 | 71.799 1 | 56.365 2 | |
| SET 1 | 96.797 8 | 96.917 8 | 77.008 7 | 65.991 1 | 65.980 6 | 54.982 5 | |
| SET 2 | 97.186 7 | 97.330 9 | 77.089 2 | 72.057 9 | 72.010 9 | 55.580 0 | |
| SET 3 | 96.885 6 | 97.180 4 | 77.512 9 | 66.601 1 | 66.504 5 | 52.867 9 | |
| SET 4 | 97.026 3 | 97.155 9 | 77.038 6 | 66.255 2 | 66.188 3 | 56.862 5 | |
| SET 5 | 97.290 6 | 97.339 0 | 76.874 6 | 72.038 0 | 71.873 0 | 56.870 2 | |
| 均值 | 97.029 4 | 97.173 2 | 77.073 9 | 69.155 5 | 69.059 4 | 55.588 0 | |
由表 5可知,测试集上RoBERTa-BiLSTM-CRF的识别效果最佳。同时,袋外测试集上BERT-BiLSTM-CRF效果最佳,说明其对不同数据的适应性最好。BERT,ALBERT和RoBERTa每次测试集训练时间约10,5和20 h。无论测试集还是袋外测试集上,采用BERT和RoBERTa预训练模型的效果极为接近,采用ALBERT的模型性能均最差。综合考虑模型精度和训练时长,BERT-BiLSTM-CRF是一个在识别准确度、学习效率和鲁棒性较优的深度学习模型,以此作为本研究的交通事故命名实体识别模型。
3.2 交通事故应急处置实体识别结果分析利用BERT-Bi LSTM-CRF模型对测试集进行交通事故信息识别,应急处置实体的识别结果示例见表 6。计算持续时间和处置机构、处置设备、未处置、处置中、处置效果的Spearman相关系数,依次为0.309,0.151,0.137,0.220和0.178。结果表明,应急处置实体数量与持续时间之间存在正相关性。
| 处置机构 | 处理设备 | 未处置 | 处置中 | 效果 |
| 分公司 | 消防 | 待救援 | 临时交通管制, 交通管制, 救援 | 正常通行, 已到现场 |
| 路政、高速交警 | 拖车 | — | 预计1 h处理完毕, 预计1 h, 等待 | 已到现场 |
| 分公司、交警、路产巡查员、巡查 | 吊车, 拖车 | — | 进行救援, 救援 | 已经到位 |
| 交警 | 救援车 | — | 预计1 h, 救援 | 暂时封闭 |
3.3 交通事故信息内容的评价结果与分析
以测试集6 916条样本为例,选取天气、路产损失、交通分流、事故类型和伤亡情况作为多模态数据一致性评价内容,评价指标计算结果如表 7所示。
| 一致性A1/% | 应急处置占比B1 | 变异性B2 | ||||||||
| 天气 | 路产损失 | 交通分流 | 事故类型 | 伤亡情况 | 平均值 | 标准差 | 平均值 | 标准差 | ||
| 7.06 | 45.79 | 1.59 | 67.65 | 47.59 | 0.360 | 0.233 | 1.305 | 0.292 | ||
由表 7可知,结构化数据和文本数据的一致性较低,且不同信息内容之间波动性较大,说明两种模态数据对同一交通事故的信息内容描述不一致问题显著,需要在运营管理中加强工作人员对外部环境和控制措施的记录质量,尤其是天气和交通分流的信息采集质量。同时,应急处置实体占比达到36%,说明该数据集中以自然语言记录的文本信息具有较高的内涵,是结构化数据的有效补充,对应急处置信息命名实体识别具有实际意义。综上可知,交通事故数据集中不同模态的信息一致性尚有较大提升空间,文本信息蕴含丰富的应急处置信息,规范信息记录质量标准具有重要作用。
4 结论建立了一种高速公路交通事故命名实体识别模型,是自然语言处理技术在交通事故文本信息抽取的新方法,弥补了现阶段应急处置信息识别的不足。比较了BERT-BiLSTM-CRF,ALBERT-Bi LSTM-CRF和RoBERTa-BiLSTM-CRF这3种深度学习模型,BERT和RoBERTa预训练模型的效果最佳,且BERT训练时间较RoBERTa短。结果表明,BERT-BiLSTM-CRF模型在识别效果、训练速度和鲁棒性方面具有明显优势。
从一致性和丰富性两个维度提出了交通事故信息内容的评价指标,提供了一种多模态的信息内容量化评价方法,为解决文本信息和结构化数据一致性提供了技术路径,并实证了文本信息的分析价值。研究成果可以量化评估多模态数据采集质量,进而提取真实完整的应急处置流程,为降低交通事故持续时间提供改进依据。
信息质量评估是提高信息资源管理效率的关键,有利于提高信息价值,促进应急安全管理的发展。本研究主要从多模态数据的一致性进行评价,后续需要从信息效用、传播过程等角度深入探讨交通应急处置中信息报送的质量和有效性。
| [1] |
JI K K, LI Z Z, CHEN J, et al. Freeway Accident Duration Prediction Based on Social Network Information[J].
Neural Network World, 2022, 32(2): 93-112.
DOI:10.14311/NNW.2022.32.006 |
| [2] |
RAKHMAWATIN N A, AWWAB Y, NAJIB A C, et al. Ontology-based Traffic Accident Information Extraction on Twitter in Indonesia[J].
Inteligencia Artificial, 2022, 25(70): 1-12.
DOI:10.4114/intartif.vol25iss70pp1-12 |
| [3] |
ZHANG L Y, ZHANG M, TANG J Z, et al. Analysis of Traffic Accident Based on Knowledge Graph[J].
Journal of Advanced Transportation, 2022, 3915467.
|
| [4] |
LI J, SUN A, HAN J, et al. A Survey on Deep Learning for Named Entity Recognition[J].
IEEE Transactions on Knowledge and Data Engineering, 2022, 34(1): 50-70.
DOI:10.1109/TKDE.2020.2981314 |
| [5] |
王颖洁, 张程烨, 白凤波, 等. 中文命名实体识别研究综述[J]. 计算机科学与探索, 2023, 17(2): 324-341. WANG Ying-jie, ZHANG Cheng-ye, BAI Feng-bo, et al. Review of Chinese Named Entity Recognition Research[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(2): 324-341. |
| [6] |
童昭, 王露笛, 朱小杰, 等. 基于预训练模型的军事领域命名实体识别研究[J]. 数据与计算发展前沿, 2022, 4(5): 120-128. TONG Zhao, WANG Lu-di, ZHU Xiao-jie, et al. Research on Military Domain Named Entity Recognition Based on Pre-training Model[J]. Frontiers of Data and Computing, 2022, 4(5): 120-128. |
| [7] |
孙安亮, 时宏伟, 王金策. 基于字符与单词嵌入的航空安全命名实体识别[J]. 计算机技术与发展, 2022, 32(9): 148-153. SUN An-liang, SHI Hong-wei, WANG Jin-ce. Named Entity Recognition Based on Character and Word Embedding in Aviation Safety[J]. Computer Technology and Development, 2022, 32(9): 148-153. |
| [8] |
CHANG J, HAN X H. Multi-level Context Features Extraction for Named Entity Recognition[J].
Computer Speech & Language, 2023, 77: 101412.
|
| [9] |
刘兴丽, 范俊杰, 马海群. 面向小样本命名实体识别的数据增强算法改进策略研究[J]. 数据分析与知识发现, 2022, 6(10): 128-141. LIU Xing-li, FAN Jun-jie, MA Hai-qun. Improvement of Data Augment Algorithm for Named Entity Recognition with Small Samples[J]. Data Analysis and Knowledge Discovery, 2022, 6(10): 128-141. |
| [10] |
张鹏翔. 多维字符特征表示的铁路设备事故信息抽取方法[J]. 中国安全科学学报, 2022, 32(6): 109-114. ZHANG Peng-xiang. Information Extraction Method for Railway Equipment Accidents Based on Multi-dimensional Character Feature Representation[J]. China Safety Science Journal, 2022, 32(6): 109-114. |
| [11] |
韩广, 卜桐, 王明明, 等. 基于双通道双向长短时记忆网络的铁路行车事故文本分类[J]. 铁道学报, 2021, 43(9): 71-79. HAN Guang, BU Tong, WANG Ming-ming, et al. Text Classification of Railway Traffic Accidents Based on Dual-channel Bidirectional Long Short Term Memory Network[J]. Journal of the China Railway Society, 2021, 43(9): 71-79. |
| [12] |
王向前, 李敏敏, 孟祥瑞. 基于ALBERT-BiLSTM-CRF的煤矿事故案例文本命名实体识别方法[J]. 阜阳师范大学学报(自然科学版), 2022, 39(3): 56-64. WANG Xiang-qian, LI Min-min, MENG Xiang-rui. Named Entity Recognition Method of Coal Mine Accident Case Text Based on ALBERT-BiLSTM-CRF[J]. Journal of Fuyang Normal University (Natural Science), 2022, 39(3): 56-64. |
| [13] |
刘婷, 张社荣, 王超, 等. 水利施工事故文本智能分析的BERT-BiLSTM混合模型[J]. 水力发电学报, 2022, 41(7): 1-12. LIU Ting, ZHANG She-rong, WANG Chao, et al. Text Intelligent Analysis for Hydraulic Construction Accidents Based on BERT-BiLSTM Hybrid Model[J]. Journal of Hydroelectric Engineering, 2022, 41(7): 1-12. |
| [14] |
刘昭, 何赏璐, 刘英舜. 基于社交网络数据的交通突发事件识别方法[J]. 交通信息与安全, 2021, 39(2): 53-60. LIU Zhao, HE Shang-lu, LIU Ying-shun. A Method to Identify Traffic Incidents Based on Social Network Data[J]. Journal of Transport Information and Safety, 2021, 39(2): 53-60. |
| [15] |
樊海玮, 秦佳杰, 孙欢, 等. 基于BERT与BiGRU-CRF的交通事故文本信息提取模型[J]. 计算机与现代化, 2022(5): 10-15. FAN Hai-wei, QIN Jia-jie, SUN Huan, et al. Traffic Accident Text Information Extraction Model Based on BERT and BIGRU-CRF Fusion[J]. Computer and Modernization, 2022(5): 10-15. |
| [16] |
李昀轩, 李萌, 陆建, 等. 基于多任务迁移学习的交通警情信息自动处理方法[J]. 中国公路学报, 2022, 35(9): 1-12. LI Yun-xuan, LI Meng, LU Jian, et al. An Auto-processing Method of Traffic Safety Information Based on a Multi-task Transfer Learning Algorithm[J]. China Journal of Highway and Transport, 2022, 35(9): 1-12. |
| [17] |
李硕, 马玉坤, 韩晖, 等. 山区高速公路货车事故严重度致因及随机参数分析[J]. 公路交通科技, 2023, 40(4): 228-236. LI Shou, MA Yu-kun, HAN Hui, et al. Analysis on Causes and Random Parameters of Truck Accident Severity in Mountainous Expressway[J]. Journal of Highway and Transportation Research and Development, 2023, 40(4): 228-236. DOI:10.3969/j.issn.1002-0268.2023.04.028 |
| [18] |
陈娇娜, 靳引利, 陶伟俊, 等. 处置阶段信息对高速公路交通事故持续时间的调节效应分析[J]. 安全与环境学报, 2023, 23(4): 1169-1177. CHEN Jiao-na, JIN Yin-li, TAO Wei-jun, et al. Moderating Effect Analysis of Information in the Processing Phase on Expressway Traffic Accident Duration[J]. Journal of Safety and Environment, 2023, 23(4): 1169-1177. |
| [19] |
朱益平, 杜海娇, 张佳, 等. 基于RS-BP神经网络的政务微信公众号信息质量评价模型研究[J]. 情报科学, 2021, 39(2): 54-61. ZHU Yi-ping, DU Hai-jiao, ZHANG Jia, et al. Information Quality Evaluation Model Research of Government Wechat Public Account Based on RS-BP Neural Networks[J]. Information Science, 2021, 39(2): 54-61. |
| [20] |
徐文强, 刘春年, 周涛. 大数据环境下应急信息质量评估体系研究[J]. 图书情报工作, 2020, 64(2): 50-58. XU Wen-qiang, LIU Chun-nian, ZHOU Tao. Research on Emergency Information Quality Evaluation System in Big Data Environment[J]. Library and Information Service, 2020, 64(2): 50-58. |
| [21] |
GUO W Y, ZENG Q T, DUAN H, et al. Text Quality Analysis of Emergency Response Plans[J].
IEEE Access, 2020, 8: 9441-9456.
|