 2024, Vol. 41
2024, Vol. 41扩展功能
文章信息
- 何宇超, 段中兴, 高静.
- HE Yu-chao, DUAN Zhong-xing, GAO Jing
- 基于多尺度空洞卷积结构的路面裂缝分割方法
- A Method for Pavement Crack Segmentation Based on Multi-scale Cavity Convolution Structure
- 公路交通科技, 2024, 41(1): 1-9, 17
- Journal of Highway and Transportation Research and Denelopment, 2024, 41(1): 1-9, 17
- 10.3969/j.issn.1002-0268.2024.01.001
-
文章历史
- 收稿日期: 2021-11-25

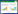


 ,
, 路面裂缝的自动检测与修复已成为制约公路养护策略的主要瓶颈。传统的路面裂缝检测以人工视觉检测为主,成本高且效率低。随着图像处理技术的迅速发展,研究者们提出了基于图论与图像处理的裂缝自动检测方法,如最小生成树[1]、最小代价路径搜索[2]、直方图[3]、裂缝融合[4]等,提高了裂缝的识别性能,但当照明条件多样,裂缝拓扑结构复杂时,检测性能波动较大。
随着深度学习的广泛应用,相关学者尝试将其应用于路面裂缝的检测中。Zhang等[5]提出了基于卷积神经网络(CNN)的检测方法,能够确保像素精度,弱化复杂环境对检测性能的影响。Yang等[6]提出了特征金字塔与分层提升网络(FPHBN),将上下文信息集成于裂缝检测的浅层特征中,通过嵌套样本重新加权来平衡易样本与难样本对损失的贡献,对背景复杂的裂缝图像有较好的检测效果。Huyan等[7]提出了一种像素级裂缝检测方法(CrackU-Net),基于UNet,结合局部与全局信息,显著提高了裂缝特征提取性能。郎洪等[8]通过将三维图像划分为背景面元与裂缝面元,提取裂缝面元内裂缝的完整轮廓与像素级邻域特征,使用卷积神经网络对裂缝进行检测,为裂缝检测提供了新思路。
图像分割相较图像分类更为复杂,需要同时实现像素块的分类与目标定位,以原图像作为输入,输出带有标签的图像。段明义等[9]针对桥梁裂缝分割识别问题,结合K-means和高斯混合模型,运用数据挖掘的方法获得精度更高、稳定性更好的分割结果。雷斯达等[10]对传统K-means算法结合统计学原理和形态学方法进行改进,实现了对复杂场景下混凝土图像裂缝骨架提取。章世祥等[11]采用Mask R-CNN为主干框架,融合特征金字塔网络建立了针对裂缝病害识别的基础网络体系,实现了复杂背景下裂缝病害的识别。张世宽等[12]提出了结合语义分割与目标检测的焊缝图像检测方法,在语义分割分支中,添加并行下采样模块及缩减卷积核数量,对模型进行优化,共享两分支的特征提取部分权重,以获取较为理想的检测效果。近年来,不少学者以图像为整体对路面裂缝图像进行分割研究。Wang等[13]采用预训练的DenseNet121进行路面特征提取,使用金字塔注意力模块融合不同金字塔尺度下的特征,获取精确的像素注意力,提升分割性能。Han等[14]提出了使用跳跃级往返采样块构造全新的像素级语义分割网络Crack-Net,获取更丰富的特征,使得裂缝中断分割不精准的问题得到了改善。
现有裂缝分割方法难以解决由于拓扑结构复杂与背景干扰导致误分割问题,UNet网络具有可进行小样本训练与分割准确等优点[15],而在UNet中嵌入注意力机制能够有效监督模型分割[16]。针对现有分割方法的不足,本研究基于UNet设计了全新的裂缝分割结构,首先在编码器和解码器中使用串并联结合的多尺度空洞卷积结构,提升了网络对复杂信息的获取能力,然后使用高效金字塔注意力分割模块取代编、解码器之间的跳跃连接,充分保留浅层特征图的空间信息,最后构建交叉注意力机制,引导多尺度信息更有效融合到解码器中,使模型在恢复裂缝时,有效减少了噪声干扰,定位更加准确,细节更加丰富。经过试验验证,本研究方法对裂缝分割主体完整,细节清晰,能有效完成复杂背景下的道路裂缝检测任务。
1 本研究方法 1.1 多尺度空洞卷积细节特征的保留对分割效果至关重要,为了应对裂缝拓扑结构杂乱带来的挑战,本研究构建多尺度空洞卷积来增大卷积核的感受野,提高网络对细节特征的捕获能力。如图 1所示,该结构可以看作是串并联结合的多尺度空洞卷积结构,每条支路的感受野均不同,同一支路采用连续孔洞率相同尺寸大小的空洞卷积,边路卷积尺寸大小为1×1,最后将多支路不同感受野大小的特征图进行融合,丰富特征图信息,提升对裂缝特征的提取与解码效果。

|
| 图 1 多尺度空洞卷积结构 Fig. 1 Structure of multi-scale cavity convolution |
| |
空洞卷积可以扩大网络的感受野,但是相同大小的空洞率会导致特征图出现网格效应[17]。因此,本设计采用[1, 2, 3, 4]的梯度扩张率[18]来构建空洞卷积,扩张卷积核和感受野的大小计算如式(1)、(2)所示:
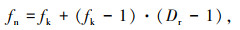
|
(1) |
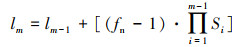
|
(2) |
式中,fk为原始卷积核的尺寸;fn为扩张卷积核的尺寸;Dr为扩张率;lm-1为第m-1层感受野的尺寸;lm为经过扩张卷积后第m层感受野尺寸;Si为第i层步幅大小。
1.2 交叉注意力机制UNet编码器中的浅层特征图包含丰富的位置信息,但缺乏分类信息,解码器中的深层特征图包含丰富的分类信息,但缺乏位置信息,跳跃连接可以将浅层特征图传递至解码器弥补位置细节信息不足的缺陷,然而编、解码器之间存在语义鸿沟,直接拼接容易引起特征混淆,因此构建交叉注意力机制来获取更有效的拼接特征图,如图 2所示。交叉注意力机制由高效金字塔注意力分割模块(EPSA)[19]与CAM注意力机制构成,使用EPSA替换encoder和decoder之间的跳跃连接,通过增强浅层特征图的位置信息来减少裂缝分割的假阳性预测,在上采样中使用CAM注意力,在恢复裂纹时,定位更加准确,细节也更加丰富。

|
| 图 2 交叉注意力机制 Fig. 2 Cross-attention mechanism |
| |
如图 3所示,EPSA由2个1×1卷积与金字塔分割注意力(Pyramid Split Attention, PSA)模块残差连接构成,提取多尺度空间信息的同时,实现通道间通信。

|
| 图 3 PSA模块 Fig. 3 PSA modules |
| |
PSA模块首先通过SPC模块(Split And Concat)得到一个多尺度特征图,然后采用SE(Squeeze-and-Excitation)[20]获取多尺度特征图中不同尺度的注意力权重,再使用Softmax对特征图权重向量进行重新校准,最后对校准后权重和特征图进行乘积操作,输出加权后的特征图。该特征图具有更强的特征表征能力。SPC模块中,假设输入为X,首先将其拆分为S个单一通道[X0,X1,…,XS-1],对其提取不同尺度的特征后,将所提取的多尺度特征通过Concat融合方法进行拼接。如式(3)~(5)所示:
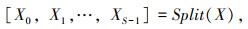
|
(3) |
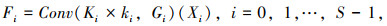
|
(4) |
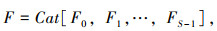
|
(5) |
式中,Split为通道分离函数; S为通道数个数,S=4;K为卷积核的尺寸大小; G为分离组的个数。
在上述基础上,对不同部分特征提取注意力权值,如式(6)所示:
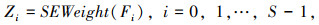
|
(6) |
式中,SEWeight为SENet中的权重模块,用来获得空间注意力的参数权重。
为了更好地实现注意力信息交互并融合跨维度信息,将上述所得注意力向量进行拼接,对所得注意力权值进行归一化,如式(7)所示:
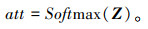
|
(7) |
最后可得到修正后的特征如式(8)所示:
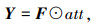
|
(8) |
式中⊙为两个矩阵对应位置进行点乘。
输入一个深层特征图F∈RH×W×C至CAM,首先进行空间上的平均池化和最大池化,得到两个1×1×C的通道描述M,然后将其输入至两个1×1卷积层,激活函数为ReLU,将两个输出特征相加,经过一个Sigmoid激活函数得到权重图H,最后将该权重图H与原特征图F相乘后,得到加权后的特征图F′,与浅层特征图G经过金字塔注意力机制生成的特征图G′做拼接,得到最终的特征图。
1.3 模型结构基于UNet设计的MAC-UNet(Multi-scale Atrous Convolution-UNet)道路裂缝语义分割模型如图 4所示。首先对512×512×3尺寸大小的输入图像进行一次卷积操作,将得到的特征图输入至由多尺度空洞卷积结构与残差结构构成的编码器,残差卷积尺寸均为1×1,输入输出通道数分别为[3, 64],[64, 128],[128, 256],[256, 512],每层编码器后均有2×2大小的最大池化层,将特征图大小缩小一半,瓶颈结构不改变通道数;然后将特征图输入至解码器,使用双线性插值与CAM作为Upsampling,多尺度空洞卷积的尺寸大小均为3×3,输入输出通道数分别为[512, 256],[256, 128],[128, 64],[64, 64],跳跃连接采用EPSA,其中EPSA与CAM组成交叉注意力机制,最后经过一个1×1大小的卷积层,得到512×512×2的裂缝二值图像。计算流程如式(9)所示。
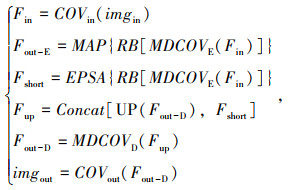
|
(9) |

|
| 图 4 MAC-UNet结构 Fig. 4 Structure of MAC-UNet |
| |
式中,imgin为裂缝样本图像;Fin为输入特征图;COVin为输入层卷积;Fout-E为解码器输出特征图;MAP为最大池化层;RB为Relu激活函数和BN归一化;MDCOVE为编码器多尺度空洞卷积结构;Fshort为跳跃连接的特征图;Fup为双线性插值上采样特征图;Concat[, ]为拼接操作;Fout-D为解码器输出特征图;MDCOVD为解码器多尺度空洞卷积结构;BCE-Loss=-1×[yl×log(yi)]+(1-yl)×log(1-yi)为输出层卷积;BCE-Loss=-1×(yl×log(yi))+(1-yl)×log(1-yi)为裂缝分割图像。
2 试验设置与评价指标 2.1 试验环境与参数设置为了更加客观地评估所提方法的有效性,所有试验均在paddlepaddle2.1.2+python3.7环境下训练和测试,使用显存为32 G的Tesla V100显卡搭配CUDA10.1作为GPU环境。使用相同超参数设置,学习率lr=0.01,训练迭代次数iter=10 000,批次大小batchsize=2,优化器为学习率自适应优化器RMSProp,权重衰减weight_decay=4.0e-5,损失函数选择二值交叉熵损失函数BCE-Loss,每2 000次迭代保存一次模型,将Dice Loss损失函数和学习率动态调整作为优化试验参数设置。
2.2 数据集与数据预处理考虑到道路裂缝强度的不均衡性,试验采用了CFD[21],GAPS384[22]两个道路裂缝数据集来验证不同网络的性能。CFD裂缝数据集由118幅480×320像素大小的路面裂缝原图像与裂缝标注图像;GAP数据集为德国沥青路面破损数据集[23],由1 969幅1 920×1 080像素大小的灰度图像构成,包括各种类型的损坏,如裂缝、坑洞、镶嵌修补等,无像素级标注,为了将其应用在分割算法中,对其中384幅只包含裂纹的图像进行像素级标注,训练和验证以及测试样本比例为8∶1∶1,在训练前将图像大小调整为512×512×3,再进行归一化操作,并通过水平翻转、垂直翻转、HSV颜色空间调整、增加高斯噪声等数据增强操作,提升了数据样本的泛化性,避免了因数据样本过少产生的过拟合问题。
2.3 损失函数和学习率优化 2.3.1 损失函数(1) 二值交叉熵
二值交叉熵损失函数BCE-Loss(binary_cross_entropy-Loss)被广泛用于二值像素分割任务,其表达式如式(10)所示。
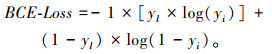
|
(10) |
(2) Dice Loss
Dice Loss[24]来自dice coefficient,Dice系数是一种用于评估样本相似性的度量函数,取值范围为0到1,值越大表示越相似,如式(11)所示:
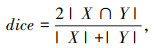
|
(11) |
式中,|X∩Y|为X和Y之间的交集;|X|和|Y|分别为X和Y的元素个数,在图像分割中,X为真实标注图像;Y为预测分割图像。
因此,dice loss可以表示为式(12):
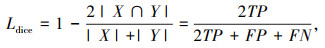
|
(12) |
式中,TP为真阳性,正类预测为正类;FP为真阴性,负类预测为负类;FN为假阴性,负类预测为正类。
2.3.2 学习率优化策略在进行模型训练时,递减的学习率有利于网络最佳参数的获得,阶梯式下降的学习率会导致训练波动。因此,选择PolynomialDecay的学习率优化策略动态调整学习率,实现自适应的学习率衰减,如式(13)所示。
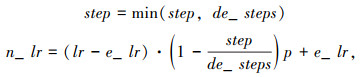
|
(13) |
式中,step为当前迭代步数;de_steps为衰减步长,决定衰减到最终学习率的速率;lr为初始学习率;e_lr为最终学习率;n_lr为更新学习率;p为多项式的幂值,本研究设置为1。
2.4 评价指标为了更全面地评价模型性能,选择平均交并比(Mean Intersection over Union, MIoU)与Kappa系数来衡量模型的分割效果。
(1) 平均交并比MIoU
MIoU为计算真实值(Ground Truth)和预测值(Predicted Segmentation)的交集和并集之比,对道路图像的背景与裂缝计算器(Intersection over Union, IoU),取其均值,如式(14)所示:
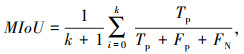
|
(14) |
式中,k+1为类数;Tp,Fp,FN分别为裂缝分割正确的像素点、裂缝分割错误的像素点以及背景分割错误的像素点。
(2) Kappa系数
由于裂缝分割中细小裂缝被忽略,模型容易出现“偏向性”,出现偏向背景而忽略裂缝的情况,因此需要Kappa系数这一指标来衡量分割是否平衡,表示背景分割与裂缝分割的均衡性。Kappa值越低表示分割的平衡性越差,在混淆矩阵的基础上计算,取值范围为(-1, 1),通常大于0。由式(15)可计算得到:

|
(15) |
式中,p0为accuracy,pe为所有类别分别对应的“实际与预测数量的乘积”的和除以“样本总数的平方”。
(3) 常用评价指标recall、precision、F1分数
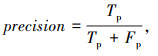
|
(16) |
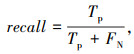
|
(17) |
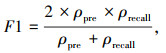
|
(18) |
式中,Tp,Fp,FN分别为裂缝分割正确的像素点、裂缝分割错误的像素点以及背景分割错误的像素点。
3 试验结果与分析 3.1 算法有效性验证为验证提出算法的有效性,选取FCN[25],ANN[26],DANET[27],PSPNET[28],UNET[29]与本研究模型MAC-UNET在CFD与GAPS384两个公开数据集上进行对比试验,CFD测试结果如图 5所示,GAPS384测试结果如图 6所示。

|
| 图 5 不同网络在CFD数据集测试结果 Fig. 5 Test results of different networks on CFD data set |
| |

|
| 图 6 不同网络在GAPS384数据集测试结果 Fig. 6 Test results of different networks on GAPS384 data set |
| |
原图圈出区域显示了不同模型之间分割差异较大的裂缝细节,当裂缝形态复杂但纹路较少时,图中第1,4行,FCN,ANN以及DANET会丢失部分裂缝,而PSPNET与UNET会引入一些外部噪点,而本研究方法能够将裂缝的细小纹路连续分割呈现,并且裂缝边缘分割得更加平滑,说明在编、解码器中使用多尺度空洞卷积能够提取更丰富的裂缝特征;当裂缝形态复杂且包含大量细小裂缝时,图中第2,3,5行,FCN和ANN仅分割出了主要裂缝,损失较大,DANET、PSPNET以及UNET也出现了少量裂缝丢失,而本研究方法的分割效果总体最佳,裂缝分割最为完整与清晰,基本接近真实标注。6种模型在CFD数据集中的测试结果如表 1所示。由表中对比结果可以看出,本研究模型在各项指标上均优于对比方法,在关键指标MIOU和Kappa系数上,相较UNET分别提升了8.4%和8.52%,与结果图分析一致,且本研究模型体积最小为30.79 M,推理时间相对较短,能够满足在移动端部署的要求。
| CFD数据集 | MIOU | Kappa | 模型大小/MB | 推理时间/s |
| FCN | 0.706 3 | 0.615 3 | 36.89 | 0.158 |
| ANN | 0.727 4 | 0.629 2 | 185.56 | 0.070 |
| DANET | 0.726 7 | 0.627 7 | 181.25 | 0.069 |
| PSPNET | 0.704 6 | 0.585 1 | 259.03 | 0.075 |
| UNET | 0.746 2 | 0.662 9 | 51.13 | 0.040 |
| MAC-UNET | 0.830 2 | 0.748 1 | 30.79 | 0.078 |
图 6为各模型在GAPS384上的部分测试结果,GAPS384样本中含有阴影等干扰,对模型的性能要求更高。对于简单裂缝,如图中第2,5行,ANN与DANET出现了较大程度的裂纹丢失,FCN、PSPNET与UNET则将路面修补误分割为裂缝,产生了多余噪声,而本研究方法几乎没有丢失裂纹,对于路面修补也进行了正确分割。对于拓扑结构复杂的裂缝,如图中1,3,4行,FCN、PSPNET与UNET整体表现较差,均存在较大的噪声与损失,ANN、DANET对于裂缝纹路分割出现了不同程度的断裂现象,本研究方法几乎保留了全部纹理特征,且裂缝纹路清晰连续。表 2为6种模型在GAPS384数据集上的定量指标对比结果,本研究方法在除推理时间外的所有指标上均表现最佳,这是因为模型使用了串并结合的多尺度空洞卷积,串联的多卷积结构会增加一定的计算负担,相较UNET的MIOU和Kappa系数分别提升了6.84%和8.23%,并且本研究模型大小减少20 M,说明多尺度空洞卷积结构能够在有效提取特征信息的同时缩减模型参数量。
| GAPS384 | MIOU | Kappa | Recall | Precision | F1 | 模型大小/MB | 推理时间/s |
| FCN | 0.678 7 | 0.534 3 | 0.708 9 | 0.700 9 | 0.704 5 | 36.89 | 0.165 |
| ANN | 0.662 0 | 0.502 9 | 0.701 0 | 0.706 0 | 0.703 5 | 185.56 | 0.079 |
| DANET | 0.668 1 | 0.510 3 | 0.718 2 | 0.698 2 | 0.708 0 | 181.25 | 0.075 |
| PSPNET | 0.670 9 | 0.517 2 | 0.795 1 | 0.798 8 | 0.796 9 | 259.03 | 0.081 |
| UNET | 0.689 8 | 0.556 3 | 0.808 5 | 0.822 3 | 0.817 0 | 51.13 | 0.044 |
| MAC-UNET | 0.758 2 | 0.638 6 | 0.908 6 | 0.887 3 | 0.897 8 | 30.79 | 0.069 |
综合两个数据集的测试结果可知,MAC-UNET对于简单裂缝和辅助裂缝均能取得较好分割结果,且对于如背景干扰、光线不均衡等问题,也能较好应对,对裂缝拓扑结构保留完整,分割细节清晰,同时能够满足小体积与速度快的要求。
3.2 消融试验为进一步验证多尺度空洞卷积结构与交叉注意力机制的有效性,进行消融试验,将组合不同模块的模型在CFD数据集上进行训练,测试结果如表 3所示。相较UNET,使用了串并联相结合的多尺度空洞卷积结构的UNET模型UNET+MAC,MIOU提升了2.76%,Kappa系数提升了2.3%,模型体积缩减了48.58%,说明该结构能够以较少的参数量获取多尺度信息,使模型能够兼顾小体积与高精度的要求;对比UNET+MAC模型,UNET+MAC+EPSA的MIOU和Kappa系数进一步得到了提升,说明在跳跃连接中增加EPSA丰富了浅层特征图的特征数量,使得分割效果更好;而UNET+MAC+CAM的MIOU和Kappa系数提升不大,因为仅在编码中使用CAM获得的深层特征有效性较差,因此改进性能提升不明显。基于此,本研究将EPSA与CAM结合构成交叉注意力机制,结合MAC结构,分割性能明显提升,相较UNET,MIOU提高了8.4%,Kappa系数提高了8.52%,可以看出使用空洞卷积结构提高特征的提取性能,增加网络对复杂背景的抗干扰与边缘细小裂缝的捕获能力,使用交叉注意力机制能够更好地融合浅层和深层特征图,提升网络对裂缝细节的保留和复原能力,使模型在复杂裂缝的分割上表现更好。
| CFD数据集 | MIOU | Kappa | 模型大小/MB | 推理时间/s |
| UNET | 0.746 2 | 0.662 9 | 51.13 | 0.040 |
| UNET+MAC | 0.773 8 | 0.685 9 | 26.29 | 0.068 |
| UNET+MAC+CAM | 0.787 4 | 0.697 3 | 28.66 | 0.062 |
| UNET+MAC+EPSA | 0.793 6 | 0.702 4 | 29.47 | 0.075 |
| MAC-UNET | 0.830 2 | 0.748 1 | 30.79 | 0.078 |
4 结论
本研究针对路面裂缝的自动检测问题,基于UNet提出多尺度空洞卷积结构的U形图像语义分割网络MAC-UNET,首先构建多尺度空洞卷积结构,融合多尺度特征信息,使网络能够更好地应对复杂拓扑裂纹分割不连续的问题;然后构建由EPSA于CAM构成的交叉注意力机制,应用于在跳跃连接处,有效地获取多尺度空间信息,建立更长距离的通道依赖关系,在裂缝的恢复过程中,对于裂缝的定位更准确,分割细节表现更佳。试验结果表明,本研究提出的模块提高了模型的检测效果,与以往方法相比,在CFD数据集上,MIOU和Kappa系数分别提升了8.4%和8.52%。在GAPS384数据集上,分别提升了6.84%和8.23%,裂缝分割细节更加清晰与完整,同时本研究模型的体积与推理速度均较好地满足小而精准与快速的要求,在后续研究中可以对网络参数继续进行优化,使其更好地部署于移动端,并且进一步从分割图像分析裂缝特征信息,增加对裂缝形态方面的研究,增强模型的工程应用性。
| [1] |
邹勤, 李清泉, 毛庆洲, 等. 利用目标点最小生成树的路面裂缝检测[J]. 武汉大学学报(信息科学版), 2011, 36(1): 71-75. ZOU Qin, LI Qing-quan, MAO Qing-zhou, et al. Target-points MST for Pavement Crack Detection[J]. Geomatics and Infomaction Science of Wuhan University, 2011, 36(1): 71-75. |
| [2] |
李清泉, 邹勤, 毛庆洲. 基于最小代价路径搜索的路面裂缝检测[J]. 中国公路学报, 2010, 23(6): 28-33. LI Qing-quan, ZOU Qin, MAO Qing-zhou. Pavement Crack Detection Based on Minimum Cost Path Searching[J]. China Journal of Highway and Transport, 2010, 23(6): 28-33. |
| [3] |
LI Q, LIU X. Novel Approach to Pavement Image Segmentation Based on Neigh Boring Difference Histogram Method[C]// Congress on Image and Signal Processing. Sanya: IEEE, 2008, 2: 792-796.
|
| [4] |
彭博, 蒋阳升, 陈成, 等. 基于1 mm精度路面三维图像的裂缝自动并行识别算法[J]. 东南大学学报: 自然科学版, 2015, 45(6): 1190-1196. PENG Bo, JIANG Yang-sheng, CHEN Cheng, et al. Automatic Parallel Cracking Detection Algorithm Based on 1 mm Resolution 3D Pavement Images[J]. Journal of Southeast University (Natural Science Edition), 2015, 45(6): 1190-1196. |
| [5] |
ZHANG A, WANG K C P, LI B, et al. Automated Pixel-level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-learning Network[J].
Computer-aided Civil and Infrastructure Engineering, 2017, 32(10): 805-819.
DOI:10.1111/mice.12297 |
| [6] |
YANG F, ZHANG L, YU S, et al. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection[J].
IEEE Transactions on Intelligent Transportation Systems, 2019, 21(4): 1525-1535.
|
| [7] |
HUYAN J, LI W, TIGHE S, et al. CrackU-net: A Novel Deep Convolutional Neural Network for Pixelwise Pavement Crack Detection[J].
Structural Control and Health Monitoring, 2020, 27(8): e2551.
|
| [8] |
郎洪, 温添, 陆键, 等. 基于深度学习的三维路面裂缝类病害检测方法[J]. 东南大学学报(自然科学版), 2021, 51(1): 53-60. LANG Hong, WEN Tian, LU Jian, et al. 3D Pavement Crack Detection Methond Based on Deep Learning[J]. Journal of Southeast University (Natural Science Edition), 2021, 51(1): 53-60. |
| [9] |
段明义, 卢印举, 李祖照, 等. 一种改进的桥梁裂缝图像分割方法[J]. 公路交通科技, 2020, 37(11): 63-70. DUAN Ming-yi, LU Yin-ju, LI Zu-zhao, et al. An Improved Bridge Crack Image Segmentation Method[J]. Journal of Highway and Transportation Research and Development, 2020, 37(11): 63-70. DOI:10.3969/j.issn.1002-0268.2020.11.009 |
| [10] |
雷斯达, 曹鸿猷, 康俊涛. 基于深度学习的复杂场景下混凝土表面裂缝识别研究[J]. 公路交通科技, 2020, 37(12): 80-88. LEI Si-da, CAO Hong-you, KANG Jun-tao. Study on Concrete Surface Crack Recognition in Complex Scenario Based on Deep Learning[J]. Journal of Highway and Transportation Research and Development, 2020, 37(12): 80-88. DOI:10.3969/j.issn.1002-0268.2020.12.011 |
| [11] |
章世祥, 张汉成, 李西芝, 等. 基于机器视觉的路面裂缝病害多目标识别研究[J]. 公路交通科技, 2021, 38(3): 30-39. ZHANG Shi-xiang, ZHANG Han-cheng, LI Xi-zhi, et al. Study on Multi-objective Identification of Pavement Cracks Based on Machine Vision[J]. Journal of Highway and Transportation Research and Development, 2021, 38(3): 30-39. DOI:10.3969/j.issn.1002-0268.2021.03.005 |
| [12] |
张世宽, 吴清潇, 林智远. 焊缝图像中结构光条纹的检测与分割[J]. 光学学报, 2021, 41(5): 88-96. ZHANG Shi-kuan, WU Qing-xiao, LIN Zhi-yuan. Detection and Segmentation of Structured Light Stripe in Weld Image[J]. Acta Optica Sinica, 2021, 41(5): 88-96. |
| [13] |
WANG W, SU C. Convolutional Neural Network-based Pavement Crack Segmentation Using Pyramid Attention Network[J].
IEEE Access, 2020, 8: 206548-206558.
DOI:10.1109/ACCESS.2020.3037667 |
| [14] |
HAN C J, MA T, HUYAN J, et al. CrackW-Net: A Novel Pavement Crack Image Segmentation Convolutional Neural Network[J].
IEEE Transactions on Intelligent Transportation Systems, 2022, 23(1): 22135-22144.
|
| [15] |
ZHANG Y, REN H, YANG W, et al. The Strong Substructure and Feature Attention Mechanism for Image Semantic Segmentation[J].
Concurrency and Computation: Practice and Experience, 2020, e5920.
|
| [16] |
HUANG G, ZHU J, LI J, et al. Channel-attention U-Net: Channel Attention Mechanism for Semantic Segmentation of Esophagus and Esophageal Cancer[J].
IEEE Access, 2020, 8: 122798-122810.
DOI:10.1109/ACCESS.2020.3007719 |
| [17] |
YU F, KOLTUN V, FUNKHOUSER T. Dilated Residual Networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2017: 472-480.
|
| [18] |
WANG P, CHEN P, YUAN Y, et al. Understanding Convolution for Semantic Segmentation[C]// IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe: IEEE, 2018: 1451-1460.
|
| [19] |
ZHANG H, ZU K, LU J, et al. Epsanet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network[D]. Ithaca: Cornell University, 2021.
|
| [20] |
HU J, SHEN L, SUN G. Squeeze-and-excitation Networks[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
|
| [21] |
SHI Y, CUI L, QI Z, et al. Automatic Road Crack Detection Using Random Structured Forests[J].
IEEE Transactions on Intelligent Transportation Systems, 2016, 17(12): 3434-3445.
DOI:10.1109/TITS.2016.2552248 |
| [22] |
YANG F, ZHANG L, YU S, et al. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection[J].
IEEE Transactions on Intelligent Transportation Systems, 2019, 21(4): 1525-1535.
|
| [23] |
EISENBACH M, STRICKER R, SEICHTER D, et al. How to get Pavement Distress Detection Ready for Deep Learning? A Systematic Approach[C]// International Joint Conference on Neural Networks (IJCNN). Anchorage: IEEE, 2017: 2039-2047.
|
| [24] |
MILLETARI F, NAVAB N, AHMADI S A. V-net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation[C]// 4h International Conference on 3D Vision. Stanford: IEEE, 2016: 565-571.
|
| [25] |
LONG J, SHELHAMER E, DARRELL T. Fully Convolutional Networks for Semantic Segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431-3440.
|
| [26] |
ZHU Z, XU M, BAI S, et al. Asymmetric Non-local Neural Networks for Semantic Segmentation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 593-602.
|
| [27] |
FU J, LIU J, TIAN H, et al. Dual Attention Network for Scene Segmentation[C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3146-3154.
|
| [28] |
ZHAO H, SHI J, QI X, et al. Pyramid Scene Parsing Network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2881-2890.
|
| [29] |
RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional Networks for Biomedical Image Segmentation[C]// International Conference on Medical Image Computing and Computer-assisted Intervention. Munich: Springer International Publishing, 2015: 234-241.
|