 2023, Vol. 40
2023, Vol. 40扩展功能
文章信息
- 谭云峰, 刘昆, 莫洪柳, 胡靖, 王振.
- TAN Yun-feng, LIU Kun, MO Hong-liu, HU Jing, WANG Zhen
- 基于优化U-Net的路面裂缝分割及其影响因素研究
- Study on Pavement Crack Segmentation and Its Influencing Factors Based on Optimized U-Net
- 公路交通科技, 2023, 40(12): 17-25
- Journal of Highway and Transportation Research and Denelopment, 2023, 40(12): 17-25
- 10.3969/j.issn.1002-0268.2023.12.003
-
文章历史
- 收稿日期: 2021-11-25




 ,
, 2. 江西九江长江公路大桥有限公司, 江西 九江 332105;
3. 青海省交通工程技术服务中心, 青海 西宁 810001
2. Jiangxi Jiujiang Yangtze River Expressway Bridge Co., Ltd., Jiujiang Jiangxi 332105, China;
3. Qinghai Provincial Transportation Engineering Technology Service Center, Xining Qinghai, 810001
在道路工程行业,道路智能化检测的效率及精度一直是热门的研究问题,高精度裂缝分割是开展路面病害评估的基础。道路结构的裂缝发展程度反映了其安全性和耐久性,针对裂缝病害的高效、准确检测和评估是确保道路结构服役质量的关键。传统的人工检测方法存在检测效率低、精度差、主观性强等问题,而以往裂缝图像分割的方法,如阈值法[1]、区域生长算法[2]、边缘检测算法[3]、遗传算法[4]和聚类法[5]虽表现出一定的自动化分割功能,但在复杂背景下,此类方法存在精度不够高的缺陷。深度学习随着计算机技术的发展而逐步在工程领域得到应用,其具备在复杂场景下实现有效检测与分割的功能,因此在道路病害的智能化检测中得到广泛应用。
裂缝病害的检测和分割是道路质量评估的首要任务。针对裂缝检测,现阶段常见的检测方法包含YOLO[6]、SSD[7]以及两阶段检测方法Faster-RCNN[8],通过实际测试均表现出较为优异的检测精度。而针对裂缝的分割,虽然典型算法如FCN[9],Mask-RCNN[10],SegNet[11],U-Net[12]等均表现出一定的分割功能,但由于裂缝像素与图像背景像素存在严重的正负样本不均衡问题,导致裂缝病害、尤其是微细裂缝的分割精度存在较大制约。针对小目标对象及正负样本不均衡的问题,Lin等[13]提出了焦点损失函数(Focal Loss),其以标准交叉熵为基础减少易分类样本的权重,促使模型更加注重于难样本的分类。章世祥等[14]提出了利用平衡二值化交叉熵计算Loss函数数值,并对裂缝像素的错误分类设置更高的惩罚值,有效缓解了裂缝像素和背景像素数量上失衡导致的召回率下降;Salehi等[15]提出了Tversky loss解决数据的不平衡问题,确保3D全卷积神经网络训练精度与召回率达到最佳平衡。Zhu等[16]针对小目标对象的分割,提出了一种包括骰子损失和焦点损失(Dice Loss and Focal Loss)的混合损伤函数,有效提高了模型训练的精度。Wong等[17]提出了一种指数对数损失函数,根据目标的大小和分割难度平衡目标样本,提升了模型拟合的速率。综上可知,现阶段路面裂缝分割领域所建立的损失函数对小目标图像的分割具有一定的效果,但仍然存在分割精度与效率难以协调的难点。
本研究以U-Net网络模型为基础,通过在卷积层中添加残差模块(Residual Block)减少网络传播的误差,形成优化后U-Net-R网络分割模型。同时,测试了焦点损失函数、带权交叉熵损失函数、软骰子-交叉熵复合损失函数与焦点-骰子复合损失函数对裂缝分割精度的影响。通过本研究建立了焦点-骰子复合损失函数的U-Net-R分割模型,有效地减少了裂缝分割正负样本不均衡来的误差,在保证分割效率的同时提升了分割精度。
1 路面裂缝分割模型 1.1 基于优化U-Net的路面分割模型目标的分割是指根据灰度、彩色、空间纹理、几何形状等特征将图像划分成若干个互不相交的区域,使得同一区域内表现出特征一致性或相似性,而在不同区域间表现出明显的不同。随着深度学习不断发展,编码器-解码器模型、递归神经网络模型及对抗性训练模型等得到逐步应用,而其中编码器-解码器模型在图像分割方面表现出显著优势[18]。
编码器-解码器模型属于端到端模型,其学习通过两级网络将数据点从输入域映射到输出域:由编码函数z=gφ(x)编码器将输入压缩为潜在空间表示;解码器y=fφ(x),旨在预测潜在空间表示的输出。模型所涉及的潜在表示本质上是指一种特征(向量),其能够捕获对预测输出有用的输入底层语义信息。编码器-解码器模型的框图如图 1所示,通过最小化重构损失函数训练模型,该重构损失函数衡量地面真值输出和后续重构之间的差异,通常而言,输出可以经过优化后的图像或分割图。本研究中所用U-Net模型属于编码器-解码器模型,如图 2所示。

|
| 图 1 解码器-编码器模型 Fig. 1 Decoder-encoder model |
| |

U-Net是由Ronneberger等[12]提出的一种采用编码-解码结构的深度学习网络,其凭借多尺度特征融合在图像分割中得到广泛应用。U-Net是完全对称的结构,其体系包括两个部分,即用于捕获上下文的收缩路径和用于实现精确定位的对称扩展路径。下采样或收缩部分具有类似FCN的体系结构,利用3×3的卷积层可提取特征。上采样或者扩展部分使用向上卷积,在增加特征图尺寸的同时减少特征图的数量。U-Net将网络下采样部分的特征图复制到上采样部分,以避免丢失模式信息。最后利用1×1的卷积核处理特征映射以生成分割映射,该分割映射可实现对输入图像的每个像素进行分割。
由于道路裂缝分割具备小目标的特征,因此所提取的深度特征也较为细微。随着深层次的网络逐步增加与收敛,分割精度达到饱和,同时网络也出现退化现象。造成退化的原因并非过度拟合,而是过多的网络层积累的训练误差所致,从而影响裂缝分割的精度。针对U-Net小目标分割出现的网络退化现象,本研究选取了残差模块[19]替代了U-Net结构中两次卷积模块,利用残差块解决网络中存在的网络退化的问题,同时实现更好提取目标的特征,提升模型训练效率和分割能力,本研究所建立的残差模块U-Net-R具体结构如图 3所示。

|
| 图 3 U-Net-R结构图 Fig. 3 U-Net-R structure diagram |
| |
如图 3所示,Max-pooling代表 2×2的池化操作,Up-sample代表 2×2的向上采样操作,conv代表 1×1的卷积层,残差模块输入和输出关系如下所示:
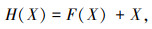
|
(1) |
式中,X为输入;F(X)为卷积层输出;H(X)为残差模块输出。
U-Net-R网络模型收缩路径中有4次下采样,每次下采样之前布置一个残差模块,包含2次卷积核为3×3的卷积操作,在卷积操作前首先进行批量标准化(Batch Normalization,BN)提高训练速度,并使用线形整流(Rectified Linear Unit, ReLU)函数作为激活函数。U-Net-R扩展路径包含了2×2的采样操作以及与收缩路径相同的残差模块,首先开展4次上采样,其后通过Sigmoid激活函数的1×1卷积层将特征向量映射到裂缝所代表的概率体上。
1.2 模型损失函数优化由于裂缝像素在整体图像中占比极小,极容易出现正负样本不均衡的状况。大量样本为负样本无法提供有用的学习目标,导致训练效率低下、训练效果不理想。现阶段,二分类任务中表现优异的损失函数如下主要包括交叉熵损失(Cross-entropy Loss)函数、焦点损失(Focal Loss)函数、骰子损失(Dice Loss)、软骰子系数(Soft Dice-coefficient, Loss)损失、交并比损失(IoU Loss)以及组合损失函数。本研究拟在二分类任务中选取表现优异损失函数,通过调参优化,明确最适合于裂缝识别分割模型的损失函数。
(1) 焦点损失(Focal Loss)函数[13]
焦点损失函数在二元交叉熵损失函数的基础上增加了权重系数,通过调整参数提高模型对正样本的注意力,从而减低正负样本不均衡的影响。焦点损失函数如下所示:
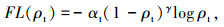
|
(2) |
其中,ρt定义为:
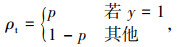
|
(3) |
式中,y为真值类别;p∈[0, 1]是标签为y=1时模型的估计概率;(1-ρt)γ是调和因子,可调焦的参数γ≥0;αt为加权因子,通过负样本频率来设置,或是作为超参数通过交叉验证进行设置。αt的作用是给不同类别的样本损失值加权重,如正样本少,就加大正样本损失值的权重;而γ的作用是当样本预测值ρt较大时,减小γ数值,使得易分样本的loss显著减小,模型更关注难分样本loss的优化。
(2) 带权交叉熵损失(Pixel-wise Cross-entropy Loss)函数[20]
带权交叉熵损失函数源于交叉熵损失函数,该函数通过带权的方式消除正负像素不均衡,即目标像素远小于背景像素时,此时y=0的数量远大于y=1的数量,损失函数中y=0的像素会成为主导因素,使得模型严重偏向于背景像素而不利于分割效果。通过不断调节权重参数,使得裂缝像素成为模型关注的重点,其具体公式如下:
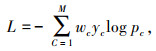
|
(4) |
式中,M为模型的类别数,本研究中取2,表示裂缝和背景。yc∈{0, 1},当该样本与样本的类别相同则取1,否则取0。pc为预测样本属于c的概率。wc的计算公式为:
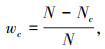
|
(5) |
式中,N为图像整体像素的个数;Nc为整个类别c的像素个数。
(3) 软骰子-交叉熵复合损失(Soft Dice-coefficient Loss+ Pixel-wise Cross-entropy Loss)函数[21]
Dice系数是计算机视觉广泛使用的度量标准,用于评估两个图像间的相似度。Dice损失函数广泛用于图像分割领域,而一般情况下使用Dice Loss会导致反向传播不利的影响,使得训练不稳定。该损失函数结合了包括像素交叉熵损失函数和软骰子系数损失函数,具体表现两方面优势:既缓解了裂缝像素不均衡的问题,也消除了反向传播的不利影响,其公式如下所示。
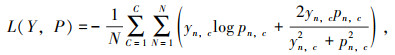
|
(6) |
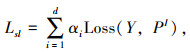
|
(7) |
式中,pn, c和yn, c分别为在批次中c类和N个像素的目标标签和预测的概率;N为一个批次中像素的数量;d为解码器的索引。在本研究中将αi赋值为1,即给每个损失都赋予了相同的权值。
(4) 焦点-骰子复合损失(Focal Loss+Dice Loss)函数[16]
焦点损失函数有助于模型更好地学习数据分类不良的问题,而骰子损失则有效缓解不平衡像素的影响。两类损失函数的结合将更有利于小目标的分割问题,同时避免了Dice loss单独训练时反向传播不稳定的现象,其公式如下所示:
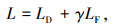
|
(8) |
式中,LD为骰子损失函数;LF为焦点损失函数;γ为焦点损坏和骰子损失的权重系数,可设置为0.1,0.5或1。本研究基于优化U-Net-R模型,将二元交叉熵损失函数、焦点损失函数、带权交叉熵损失函数、软骰子-交叉熵复合损失函数和采用焦点-骰子复合损失函数分别定义为L0,L1,L2,L3和L4,探索在5种不同的损失函数下模型训练收敛的状态以及裂缝的分割情况。
2 路面裂缝数据集构建与模型训练为了训练与测试识别模型,采集了不同分辨率的路面裂缝图像总计1 290张,其中横向与纵向裂缝1 128张,网状裂缝162张。随机选取1 144张病害图像作为训练集,146张病害图像作为测试集,训练集中水泥路面与沥青路面裂缝病害图像分别为778张与366张。为便于计算,压缩不同路面裂缝图像至统一分辨率768×1 024。由于图像的分割实质上是对每一个像素进行分类,因此对于监督学习来说需要对目标图像进行像素级的标记。
传统像素级的标记需要人工逐像素标记,一方面耗费极大的工作量,另一方面人工标记存在准确率的不稳定性。为了降低人工标记的不稳定性和工作量,提升标记的准确率,本研究采用结合数字图像处理的半人工标注方法:首先对输入的图像分别进行高通滤波去噪与二值化处理,然后通过自适应阈值对图像进行初步分割,获取包含部分噪点的裂缝图像,最后再将数字图像处理后的图像进行人工逐像素标记,从而得到满足训练要求的标记图像,具体标注流程如图 4所示。

|
| 图 4 训练集标注方法 Fig. 4 Labeling method for training set |
| |
将标注后的裂缝图像按照9∶1的比例分为训练集和测试集,并且采用翻转、对称与随机调整亮度, 对比度实现训练集数据增强及数据集大小的扩充。使训练的模型具有更好的泛化能力和鲁棒性,典型训练图像数据如图 5所示。

|
| 图 5 U-Net-R模型训练集 Fig. 5 U-Net-R model training set |
| |
训练集输入的图像数据分辨率为768×1 024,batchsize设置为1,选用SGD随机梯度下降法,学习率为0.01,动量设置为0.9。为了使损失函数Loss更好收敛,使用指数衰减让学习率随着学习进度降低以达到更好的训练目的。在设置损失函数时,分别采用二元交叉熵损失函数L0、焦点损失函数L1、带权交叉熵损失函数L2、软骰子-交叉熵复合损失函数L3和焦点-骰子复合损失函数L4,并重点对L2和L4中的参数进行测试调整以期达到最佳识别效果。识别模型的构建以pytorch 1.3.1版本在ubuntu20.04系统部署了建模环境,并使用i9-9900k和RTX3090计算机设备进行模型的训练和测试。
识别模型的性能采用P, R, IoU和F1-score指标对模型像素样本分类的准确能力和实例分割的能力进行详细的性能评估。其中联合交集(IoU)是语义分割中最常用的度量指标,其被定义为预测分割图和地面真值之间的相交面积除以预测分割图和地面真值之间的并集面积:
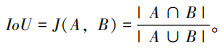
|
(9) |
精度(Precision)、召回率(Recall)及调和均值(F1-score)是评价图像分割模型准确性的常用指标。精度和召回率可以为每个类别以及在聚合级别定义,如下所示:
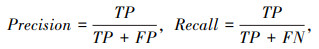
|
(10) |
式中,TP为真阳性指数;FP为假阳性指数;FN为假阴性指数。通常而言,精确率和召回率的组合更为有效,经典的组合指标为调和均值(F1-score),其定义为精确度和召回率的调和平均值:
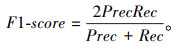
|
(11) |
本模型训练轮次为200轮,每轮迭代650次,累计训练130 000轮。每轮结束时会显示训练集和验证集的损失函数,本研究对5种不同的损失函数L0,L1,L2,L3和L4进行统计,开展训练拟合效果和效率评价以评估不同loss函数对U-Net-R的影响。5种不同的损失函数L0,L1,L2,L3和L4随迭代次数的变化如图 6所示。

|
| 图 6 不同损失函数Loss值变化规律 Fig. 6 Variation rule of Loss values of different loss functions |
| |
由图 6可以看出,若以L0为基准,L1,L2前期拟合稍慢于原函数,但最终能够获得相同的拟合效果。其中L3在训练过程中拟合速度与原函数接近,但最终的拟合效果优于原函数。而L4在训练过程中表现最为优异,不仅在前期拟合速度较快,在训练100轮的时候就已经达到了L0,L1,L2训练的效果,并且在后期也能获得最优的误差损失。
为了更形象地表明不同损失函数的影响,模型测试的实际效果图如图 7所示。

|
| 图 7 不同损失函数下病害图像分割效果 Fig. 7 Effects of disease image segmentation with different loss functions |
| |
如图 7所示,L4模型在裂缝的分割上有较高的精度。且在原损失函数和第1、第2类损失函数的模型下识别的图像存在裂缝局部缺失断裂或是将背景识别为裂缝的现象。而3、4类损失函数的模型下识别的裂缝显然更未完整,背景的误识别现象也有所优化。
综上所述,L3函数能够提高模型对目标裂缝的识别分割精度,但是在训练阶段的拟合效率仍保持不变。而选用L4函数作为U-Net-R训练裂缝的损失函数在训练拟合的效率上和目标裂缝的测试精度上均为最佳。
3.2 识别效果对比为了体现优化后U-Net-R的分割性能,选取原始的U-Net和Seg-Net进行对比测试。测试集的试验结果图及模型评价指标如图 8所示。

|
| 图 8 裂缝病害识别效果对比图 Fig. 8 Comparison chart of crack disease recognition effects |
| |
由图 7~8所示,当模型为U-Net-R时,选取了以5种不同的损失函数训练的模型,其中L3和L4识别的裂缝像素最为丰富,原函数L0识别的裂缝像素少于L3和L4识别裂缝像素。对于微细裂缝的分割,L0,L1,L2,L3均出现了裂缝断裂的现象,而L4损失函数裂缝断裂现象有所缓解,说明L4下训练的模型拟合更加充分,不仅识别率高,并且能够减少误识别的裂缝像素。当损失函数均为L0时,本研究U-Net-R模型识别效果最佳,U-Net出现了较为严重的裂缝断裂和漏识别的现象,而Seg-Net虽能够识别较多的裂缝像素,但是其中包含了较多的噪点。选用图像分割效果量化指标进行对比,具体指标如表 1所示。
| 分割模型 | 损失函数 | P | R | IOU | F1-score |
| U-Net-R | L1 | 0.536 | 0.877 | 0.471 | 0.614 |
| U-Net-R | L2 | 0.572 | 0.839 | 0.482 | 0.623 |
| U-Net-R | L3 | 0.577 | 0.846 | 0.489 | 0.633 |
| U-Net-R | L4 | 0.615 | 0.844 | 0.525 | 0.669 |
| U-Net-R | L0 | 0.544 | 0.821 | 0.499 | 0.654 |
| U-Net | L0 | 0.547 | 0.812 | 0.474 | 0.621 |
| Seg-Net | L0 | 0.457 | 0.741 | 0.420 | 0.565 |
由表 1可知,对于损失函数的差异影响,5种不同的损失函数中L1取得最好的召回率0.877,L4取得了最好的准确率0.615,然而单一的准确率和召回率并不能说明分割的优异性。对于IoU与F1-Score,采用L4的模型均取得了最优的指标。而对比U-Net-R、U-Net和Seg-Net不同的网络模型,显然优化过后的U-Net-R的4类指标均优于U-Net和Seg-Net。结合Seg-Net网络模型所示分割的图片和评价指标,其分割的特点是具有较高的召回率、较低的准确率。简而言之,在图中表现为裂缝的像素大部分能够精确地识别出来,但同样会分割过多的背景像素,导致图上出现大量噪点。而原始的U-Net网络和优化的U-Net-R+L1模型均提高了准确率,但较低的召回率使得分割出的裂缝常出现断裂或者缺失的特性。本研究中提出的模型U-Net-R+L4在兼顾准确率的同时,也保持着较高的召回率。分割出来的裂缝较为连续,能够保持裂缝原有的形态。
图 9为6组不同裂缝病害图像的F1-score指标对比图,对于不同的裂缝,F1-score值有所浮动,但在6张图中U-Net-R类模型显著优于Seg-Net网络的分割模型并且显著高于U-Net模型,其中以应用L4的U-Net-R模型识别的目标最优。综上,从分割效果图上体现了本研究模型在裂缝病害分割上体现更高的准确性,其IoU指标优于U-Net网络10.75%,F1-score指标优于U-Net模型7.73%。

|
| 图 9 六组不同裂缝病害F1-score对比图 Fig. 9 F1-score comparison chart of 6 groups of different crack diseases |
| |
4 结论
本研究针对路面结构常见的裂缝类病害评估,基于U-Net网络框架并增加了残差模块,优化了损失函数,实现了裂缝病害图像的分割,通过与U-Net网络和Seg-Net网络的预测分割成果对比,得到如下结论:
(1) 对于裂缝类小目标分割问题,在模型训练时,可以采用焦点-骰子复合损失函数。这不仅能够解决裂缝类目标正负样本不均衡所带来的训练不充分问题,提升裂缝类目标像素的召回率,还能够加速模型拟合的速率,对模型的效率和分割精度都有一定的提升。
(2) 基于U-Net骨干网络上增加残差模块也能够缓解裂缝目标像素在训练过程中训练误差的问题,提高模型拟合程度从而提高裂缝像素的召回率。
(3) 采用焦点-骰子复合损失函数的U-Net-R模型相较于传统U-Net网络能够提高裂缝分割的精度,评估指标表明,优化的U-Net-R模型在测试集上的IoU和F1-score能够分别优于原始U-Net模型10.75%和7.73%。
| [1] |
李海丰, 吴治龙, 聂晶晶, 等. 基于深度图像的机场道面裂缝自动检测算法[J]. 交通运输工程学报, 2021, 20(6): 250-260. LI Hai-feng, WU Zhi-long, NIE Jing-jing, et al. Automatic Crack Detection Algorithm for Airport Pavement Based on Depth Image[J]. Journal of Traffic and Transportation Engineering, 2021, 20(6): 250-260. |
| [2] |
WANG K L Q, GONG W G. Wavelet-based Pavement Distress Image Edge Detection with a Trous Algorithm[J].
Transportation Research Record, 2007, 2024: 73-81.
DOI:10.3141/2024-09 |
| [3] |
WEI T, SHEN H, LI X, et al. Research on Corridor Surface Crack Detection Technology Based on Image Processing[J].
Electronic Design Engineering, 2020, 28(5): 148-151, 156.
|
| [4] |
宰柯楠, 徐江峰. 基于遗传算法和简化PCNN的裂缝检测方法[J]. 计算机应用研究, 2017, 34(6): 1885-1888. ZAI Ke-nan, XU Jiang-feng. Method of Crack Detection Based on Genetic Algorithm and Simplified Pulse Coupled Neural Network[J]. Application Research of Computers, 2017, 34(6): 1885-1888. DOI:10.3969/j.issn.1001-3695.2017.06.065 |
| [5] |
张仙艳. 数字图像处理在裂缝识别与检测中的应用[D]. 西安: 长安大学, 2013. ZHANG Xian-yan. The Application of Digital Image Processing in the Identification and Detection of Cracks[D]. Xi'an: Chang'an University, 2013. |
| [6] |
CHITALE, PRANJAL A, SHENAI, et al. Pothole Detection and Dimension Estimation System Using Deep Learning (YOLO) and Image Processing[C]//202035th International Conference on Image and Vision Computing New Zealand (IVCNZ). Wellington: IEEE, 2020: 1-6.
|
| [7] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot Multibox Detector[C]//European Conference on Computer Vision. Cham: Springer International Publishing, 2016: 21-37.
|
| [8] |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 1137-1149.
|
| [9] |
YANG F, ZHANG L, YU S, et al. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection[J].
IEEE Transactions on Intelligent Transportation Systems, 2019, 21(4): 1525-1535.
|
| [10] |
HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 40(2): 386-397.
|
| [11] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. Segnet: A Deep Convolutional Encoder-decoder Architecture for Image Segmentation[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
DOI:10.1109/TPAMI.2016.2644615 |
| [12] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]//MICCAI 2015 Lecture Notes in Computer Science. Cham: Springer International Publishing, 2015: 234-241.
|
| [13] |
LIN T, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. Cham: Springer International Publishing, 2020: 318-327.
|
| [14] |
章世祥, 张汉成, 李西芝, 等. 基于机器视觉的路面裂缝病害多目标识别研究[J]. 公路交通科技, 2021, 38(3): 30-39. ZHANG Shi-xiang, ZHANG Han-cheng, LI Xi-zhi, et al. Study on Multi-objective Identification of Pavement Cracks Based on Machine Vision[J]. Journal of Highway and Transportation Research and Development, 2021, 38(3): 30-39. DOI:10.3969/j.issn.1002-0268.2021.03.005 |
| [15] |
SALEHI S S M, ERDOGMUS D, GHOLIPOUR A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks[C]//International Workshop on Machine Learning in Medical Imaging 2017. Cham: Springer International Publishing, 2017: 379-387.
|
| [16] |
ZHU W, HUANG Y, ZENG L, et al. AnatomyNet: Deep Learning for Fast and Fully Automated Whole-volume Segmentation of Head and Neck Anatomy[J].
Med Phys, 2019, 46(2): 576-589.
DOI:10.1002/mp.13300 |
| [17] |
WONG K C L, MORADI M, TANG H, et al. 3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes[C]//Medical Image Computing and Computer Assisted Intervention 2018. Cham: Springer International Publishing, 2018: 612-619.
|
| [18] |
MINAEE S, BOYKOV Y Y, PORIKLI F, et al. Image Segmentation Using Deep Learning: A Survey[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3523-3542.
|
| [19] |
HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 770-778.
|
| [20] |
XIE S, TU Z. Holistically-nested Edge Detection[C]//2016 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2016: 1395-1403.
|
| [21] |
ZHOU Z, SIDIQUEE M M R, TAJBAKHSH N, et al. UNet++: A Nested U-Net Architecture for Medical Image Segmentation[C]//International Workshop on Multimodal Learning for Clinical Decision Support. Granada: 2018: 3-11.
|