 2023, Vol. 40
2023, Vol. 40扩展功能
文章信息
- 徐明, 康雅晶, 马斯斯, 张鹤.
- XU Ming, KANG Ya-jing, MA Si-si, ZHANG He
- 基于贝叶斯优化的XGBoost模型预测路基回弹模量
- Subgrade Resilient Modulus Prediction with XGBoost Model Based on Bayesian Optimization
- 公路交通科技, 2023, 40(11): 51-60
- Journal of Highway and Transportation Research and Denelopment, 2023, 40(11): 51-60
- 10.3969/j.issn.1002-0268.2023.11.007
-
文章历史
- 收稿日期: 2023-09-19





2. 北京市建壮咨询有限公司, 北京 100161;
3. 国网北京市电力公司, 北京 100051;
4. 北京市建设工程质量第三检测所有限责任公司, 北京 100037
2. Beijing Jian Zhuang Consulting Co., Ltd., Beijing 100161, China;
3. State Grid Beijing Electric Power Company, Beijing 100051, China;
4. Beijing Construction Engineering Quality Third Test Institute Co., Ltd., Beijing 100037, China
路基是路面结构重要组成成分之一,主要承担面层传递的荷载。其中,路基的回弹模量(Mr)是设计路基时不可或缺的参数之一,它能够表征路基抵抗变形的能力,对路面的服役年限有重要的影响[1-2]。通常,Mr可以由循环动三轴试验、共振柱试验、扭剪试验等现场试验或现场试验获得。然而,试验需要获取原状土土样,且岩土材料具有空间变异性特点,导致试验过程较为复杂,需要消耗大量人力物力[3]。因此,建立路基回弹模量的准确、高效的预测模型非常重要。
目前,已有学者通过对Mr影响因素进行分析,提出了大量与应力状态、施加载荷、岩土材料特性相关的预测经验模型[4-8]。如Kim[7]通过收集循环荷载下的三轴试验数据并进行统计分析,提出了基于2个回归参数的黏土(A-4,A-6型土)路基回弹模量预测模型;Carmichael等[8]通过调研大量文献提出了适合高液限黏土和高液限粉土的经验模型,基于已有的土体参数试验数据,建立与Mr的数学方程,通过最小二乘法拟合获得回归参数建立了这些模型。虽然经验模型形式较为简单,且在特定的数据集上能够获得较为准确的预测值,但是模型需要计算的参数较多,且泛化能力较差,对于不同类型土的路基,Mr预测效果通常不尽如人意,因此难以在实际工程中得到推广。
近年来,机器学习方法由于能够基于大量实测数据挖掘出内在的物理力学信息,已经成为解决岩土工程问题的有效手段。如赵楠等[9]基于长短期人工神经网络算法对监测数据进行预处理,并通过支持向量机智能算法建立了隧道围岩位移的预测模型;王才进等[10]分析了导热系数的影响因素,建立了人工神经网络(ANN)模型、自适应神经网络的模糊推理系统(ANFIS)模型和支持向量机(SVM)模型的预测模型,并通过与传统经验模型进行对比,验证了基于人工智能算法模型的准确性;闫浩等[11]采用SVM算法建立了煤岩体SC-CO2压裂效果预测模型,并通过蜻蜓算法和差分进化算法联合优化SVM的超参数。然而,所使用的神经网络预测精度取决于其架构设计,过深的网络会导致训练时间增加,同时其解释性较差。在样本量较少的情况下,SVM表现良好,但随着数据量的增加,其预测精度会下降。相比之下,XGBoost[12]是一种可扩展的极限梯度提升模型框架,采用并行化设计,比神经网络和SVM具有更高的计算效率。此外,XGBoost适用于增量式学习,可在不断增加数据量的情况下保持高精度,并且其弱分类器是决策树,拥有较好的解释性,能够对输入特征进行敏感性分析[13]。在XGBoost算法中,由于超参数较多,常使用网格搜索或群体优化算法来选择最佳的超参数组合,如遗传算法[14]、粒子群优化。然而,网格搜索需要枚举所有可能的参数组合,计算量大,可能会出现维度灾难问题。群体优化算法则需要大量的初始样本点,且优化效率较低。相比之下,贝叶斯优化(Bayesian Optimization,BO)算法[15]基于贝叶斯定理和高斯过程回归,能够利用先验知识和历史信息来引导搜索方向,从而快速收敛到最优解,具有更高的效率和准确性。
基于此,本研究基于2 813组回弹模量数据集,涵盖了12种压实路基类型,选取加权塑性指数(WPI)、干密度(γd)、剪应力(σc)、偏应力(σd)、含水量(w)、冻融循环循环次数(NFT)为输入变量,利用熵权法和归一化进行数据预处理,并采用BO-XGBoost模型对路基回弹模量进行预测。同时,分析了各特征的重要性,并与其他机器学习算法GA-ANN、SVM以及传统的经验模型进行比较,验证了本研究中模型的合理性与优越性。
1 贝叶斯优化和XGBoost算法原理 1.1 XGBoost算法XGBoost全称为eXtreme Gradient Boosting,是由Chen等[12]提出的一种Boosting算法,其思想是将多个弱分类器或回归器集成在一起,形成一个强分类器或回归器。XGBoost的核心在于它的优化目标函数,该函数同时考虑了预测误差和模型复杂度,通过不断迭代来优化模型,达到提高预测准确度和泛化能力的目的,具有高效、准确和灵活的特点。XGBoost算法在许多领域都有广泛应用,如航天航空、水利工程和岩土工程等。
XGBoost目前应用最为广泛的弱分类器或回归器是决策树模型,决策树模型在执行回归任务时,不断地对输入特征进行递归选择,找到回归输出与已知输出误差最小的切分方式。通常决策树回归需要将特征空间划分得较为详细,会导致过拟合的现象,而XGBoost模型则可以弥补这一不足。XGBoost通过集成思想,将多个决策树模型进行线性组合,上一颗决策树的拟合误差将作为下一颗树的拟合目标,通过不断迭代,建立误差最小的预测模型。XGBoost的目标函数的数学表达式为:
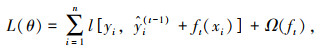
|
(1) |
式中,L(θ)为完成预测的目标函数;n为样本的数量;yi为第i个样本的真实值;t为决策树数量;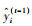
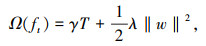
|
(2) |
式中,T为决策树中叶子节点的数量;γ为决策树中复杂度参数;λ为L2正则化系数;w为为叶子节点向量的模。
为了得到准确的预测模型,在实际应用中,需要对XGBoost的超参数进行选择。这些超参数包括决策树个数、学习率、决策树的最大深度、行采样率以及列采样率等。其中,决策树的个数用于控制模型的复杂度,学习率用于控制每个弱学习器对最终结果的影响程度,决策树的最大深度则用于防止过拟合。行采样率用于控制每个树的训练数据集采样率,而列采样率则用于控制每个树的特征采样率,也是为了防止过拟合。
1.2 贝叶斯优化算法在XGBoost中,超参数对于模型的性能至关重要,而传统的网格搜索和群体优化算法等方法存在计算复杂度高和效率低的问题。相比之下,贝叶斯优化算法能够更快地寻找最优解。
贝叶斯优化算法的基本思想是,在已知的先验信息和历史数据的基础上,通过不断选择新的超参数组合,逐步优化目标函数的值。在这个过程中,贝叶斯优化算法维护一个后验概率分布,表示目标函数在各个超参数组合下的可能取值,以此指导超参数的搜索方向。具体而言,假设目标函数为f(x),其中x是一个d维超参数向量,即x=(x1, x2,…, xd),研究目标是找到一个超参数向量 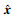
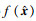
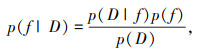
|
(3) |
式中,p(D|f) 为给定f的情况下,训练数据D出现的概率;p(f) 为f的先验概率;p(D) 为数据D出现的概率。
在每一次迭代中,需要选择一个新的超参数向量xn+1,为了选择最优的xn+1,需要计算出它对应的后验概率分布p(fn+1|D):
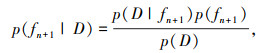
|
(4) |
式中,p(fn+1)为先验概率;p(D|fn+1)为训练数据D出现的概率,可以通过高斯过程回归的方法计算得到。在训练数据D上拟合一个高斯过程模型,然后利用该模型来预测新的超参数向量xn+1对应的目标函数值fn+1的后验分布。
在计算了后验概率分布p(fn+1|D)后,可以通过选择期望目标函数值最小的超参数向量xn+1来更新搜索方向。为了计算期望目标函数值,需要对后验概率分布p(fn+1|D)进行积分。由于高斯过程回归的后验概率分布p(fn+1|D)是一个高斯分布,因此可以通过求解高斯积分来计算期望值:
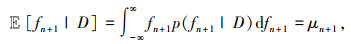
|
(5) |
式中μn+1为均值。因此,可以通过选择期望目标函数值最小的超参数向量xn+1来更新搜索方向,从而逐步优化目标函数的值,得到最优的超参数组合。
总之,贝叶斯优化算法利用高斯过程回归构建了后验概率分布,以此指导超参数的搜索方向,从而更快地寻找到最优解。该算法在XGBoost算法中的应用可以帮助更好地选择超参数,提高模型的性能。
2 路基回弹模量数据获取及特征分析为了保证数据的泛化能力,本研究收集了12种压实路基土壤的Mr试验数据[16],共2 813组,包含岩土体力学、土性参数、环境参数及Mr在内的多个特征分量,如塑性指数PI、通过#200筛子的粒径百分比(P200)、干密度(γd)、含水量(w)、剪应力(σc)等。在数据集中,2种取自于我国[17],5种取自于美国[18-19],5种取自于加拿大[20],数据分布占比如图 1所示。这12种压实路基土可以按照不同的土分类系统进行命名,其中USCS系统可以分为CL,CH,CL-ML;AASHTO系统可以分为A-4,A-6,A-7-6。根据《中国土壤分类与代码》(GB/T 17296—2009),可分为壤土和黏土。由图 1可以看出,数据分布范围很大,且来自于不同国家、不同类型的数据,表明所获取的数据集之间具有多样性,能够为相关问题提供参考。

|
| 图 1 数据分类百分比 Fig. 1 Percentage of data classification |
| |
本研究的数据集包括土的基本物理指标、无侧限抗压强度和动三轴试验结果。其中,回弹模量Mr是根据AASHTO T307-99三轴试验规范经过冻融和干湿循环处理后测得的。由于Mr受到多个因素的影响,例如应力状态、土的物理性质、压实特性和环境因素。具体而言,当围压σ3不变时,Mr会随着偏应力σd的增加而减小。同时,随着剪应力σc的增加,路基回弹模量也会相应地增加。此外,由于冻融循环(NFT)会导致路面表面开裂和剥落,以及春季融化后的过度沉降,因此NFT也需要被纳入特征选取的范畴。为了全面考虑这些因素对Mr的影响,本研究选取了加权塑性指数WPI(P200PI/100),γd,σc,σd,w,NFT作为输入特征,数据的统计特征如表 1所示。
| WPI | γd/(kN·m-3) | σc/kPa | σd/kPa | w/% | NFT | Mr/MPa | |
| 样本数量/个 | 2 813 | 2 813 | 2 813 | 2 813 | 2 813 | 2 813 | 2 813 |
| 平均值 | 13.88 | 17.73 | 27.17 | 45.64 | 18.36 | 4.13 | 33.81 |
| 标准差 | 6.43 | 1.56 | 11.85 | 17.34 | 4.52 | 3.93 | 26.62 |
| 最小值 | 5.82 | 15.50 | 0.00 | 13.80 | 12.30 | 0.00 | 3.00 |
| 中位数 | 13.16 | 17.77 | 27.60 | 41.40 | 17.30 | 3.00 | 25.50 |
| 最大值 | 31.08 | 20.40 | 41.40 | 68.90 | 41.54 | 20.00 | 217.00 |
图 2为各个变量的分布特征以及它们之间的线性关系。对角线显示了每个变量的分布情况,左侧则呈现了变量之间的线性关系。拟合曲线反映了相关性的强弱,曲线的斜率越高,则表示相关性越强。从图中可以看出,预测目标值Mr与输入变量w、NFT具有较强负相关性,而与γd具有一定的正相关性,并且与其他变量相关性较弱。

|
| 图 2 变量相关性 Fig. 2 Correlation of variables |
| |
实际上,路基回弹模量的大小由多种因素共同控制,这些因素相互作用形成了一个复杂的、动态的非线性系统。因此,单纯地依赖线性相关性无法完全揭示各变量对Mr的影响程度。为了更全面地评估变量之间的关系,需要引入非线性评价指标。这些指标能够更加准确地反映变量之间的关系,从而进一步说明它们对Mr的影响。
Spearman相关系数是一种基于秩的非参数统计方法,用于度量2个变量之间的相关性,适用于不满足正态分布假设的数据,并且可以检测出非线性关系。该方法将原始数据转换为它们的秩,然后计算秩之间的相关性来评估变量之间的相关性。其值的范围为-1到1,其中-1表示完全负相关,0表示无相关性,1表示完全正相关。与Pearson相关系数相比,Spearman相关系数对异常值更为鲁棒,因此在实际应用中被广泛采用。图 3展示了各个输入特征及回弹模量之间的Spearman相关系数值,可以看出Mr与w和NFT之间具有较强相关性。

|
| 图 3 由Spearman相关系数表达的变量间非线性相关性 Fig. 3 Nonlinear correlation among variables expressed by Spearman correlation coefficients |
| |
3 回弹模量预测与敏感性分析
预测模型求解流程如图 4所示,所有求解过程均通过Python语言进行编写。

|
| 图 4 基于贝叶斯优化XGBoost的Mr预测模型 Fig. 4 Mr prediction model based on BO-XGBoost |
| |
3.1 数据预处理
采用数据进行模型训练时,需要进行数据预处理。从表 1可以看出,输入参数数据量纲不同,影响模型收敛能力,最终导致算法的学习能力减弱,因此需要将选取数据进行归一化处理,其计算公式如下:
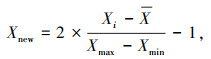
|
(6) |
式中,Xnew和Xi分别为转换后和转换前的数据;X为对应Xi的均值;Xmax和Xmin为Xi的最大值和最小值。将原始输入参数进行转换后,能够消除奇异样本数据导致的不良影响。
当进行多元数据的预测时,不同变量之间的权重可能不同,这可能会导致某些变量的贡献被低估或高估。因此,为了确保各变量的贡献能够被充分考虑,进行权重处理是非常必要的。传统的人工赋权方法容易受到主观因素的影响,而且不能够客观地反映结果对预测结果的贡献度。因此,本研究采用了一种名为熵权法的多准则决策方法[21]来进行样本数据的预处理。熵权法通过计算数据之间的相对熵值,度量数据间的不确定性程度,反映了对预测指标的传输信息,从而确定预测模型组合权重系数并提高模型预测精度。具体来说,熵权法的基本思想是利用信息熵和权重之间的关系来计算数据的权重。信息熵是度量随机变量不确定性的一种常用方法,可以衡量数据集中数据的分散程度而权重是表示每个数据对于决策的重要性。因此,熵权法可以将数据之间的不确定性程度转化为数据的相对权重,从而更加客观地反映数据对于模型预测的贡献度。采用熵权法进行数据预处理的优点在于它不仅可以解决传统人工赋权存在的主观性和不客观性问题,而且还可以有效地考虑多个因素之间的相互影响,从而提高模型的预测精度。因此本研究采用熵权法进行样本数据的预处理,其算法步骤如下:
步骤1,利用式(5)计算归一化输入数据的信息熵Ej:
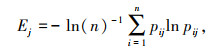
|
(7) |
式中 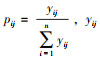
步骤2,计算信息熵冗余度:
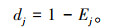
|
(8) |
步骤3,计算各项指标权值:
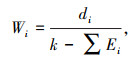
|
(9) |
式中k为输入特征的编号。经过上述步骤,所计算的输入特征WPI,γd,σc,σd,w,NFT的权重比例分别为0.205,0.164,0.064,0.109,0.182,0.276。数据预处理后的部分数据如表 2所示。
3.2 BO-XGBoost模型训练将原始数据集按80%和20%的比例被随机划分为训练集和测试集。其中,训练集用于进行5折交叉验证以及构建BO-XGBoost预测算法,测试集则作为全新数据集,用于测试优化后的模型性能。
| WPI | γd | σc | σd | w | NFT |
| 0.369 | 0.295 | 0.115 | 0.196 | 0.328 | 0.496 |
| 0.420 | 0.336 | 0.131 | 0.223 | 0.373 | 0.566 |
| 0.472 | 0.377 | 0.147 | 0.250 | 0.419 | 0.635 |
| … | … | … | … | … | … |
| 0.653 | 0.522 | 0.204 | 0.346 | 0.580 | 0.878 |
| 0.710 | 0.568 | 0.221 | 0.377 | 0.631 | 0.955 |
| 0.758 | 0.607 | 0.236 | 0.402 | 0.673 | 1.020 |
XGBoost模型有多个超参数,它们对模型的计算精度有着不同程度的影响。本研究的优化重点是XGBoost中对计算精度影响较大的超参数,包括决策树数量、学习率、最大树深度和最小叶子节点权重,其他超参数则使用默认值。超参数寻优范围及贝叶斯优化后的最终选定的超参数值如表 3所示。其中,分别使用Python中的XGBoost库和Bayesian-optimization库进行XGBoost模型训练和贝叶斯优化,迭代次数设置为100次,初始样本点设置为10个,以五折交叉验证的R2得分值为目标函数。其中R2定义为:
| 超参数名称 | 含义 | 范围 | 最终值 |
| n_estimators | 决策树数量 | [20, 100] | 76 |
| learning_rate | 学习率 | [0.01, 0.2] | 0.027 |
| max_depth | 最大树深度 | [2, 10] | 4 |
| min_child_weight | 最小叶子节点权重 | [0, 10] | 3 |
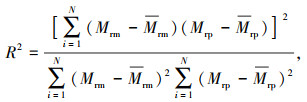
|
(10) |
式中,Mrm和Mrp分别为第i个输出路基回弹模量的真实值和预测值;Mrm和Mrp为所有真实值和预测值的平均数;N为样本数量。R2越接近1时,表示拟合得越好,而数值小于0或者等于0时则表示完全不拟合。图 5为贝叶斯算法在进行超参数寻优时,迭代步数与目标函数关系,其中最优得分值为0.997。

|
| 图 5 贝叶斯优化算法中迭代步数与目标函数关系 Fig. 5 Relationship between iteration steps and objective function in Bayesian optimization algorithm |
| |
3.3 BO-XGBoost模型评价
为了评价所选取模型的准确性和泛化能力,采用相关系数R2和均方根误差RMSE检验模型的性能。RMSE表示模型预测值与真实值的平方误差,值越小则表示模型性能越好,其计算公式如下:
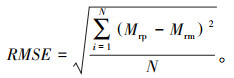
|
(11) |
图 6(a)和(b)为BO-XGBoost对训练集及测试集的预测结果,参考线表示最理想的情况,即预测值与真实值完全相等。因此,预测结果离参考线越近,表示预测效果越好,反之则越差。可以看出,无论是在训练集或测试集中,XGBoost模型预测结果的R2都在0.99以上,RMSE均在1.6以下,且预测数值基本分布在参考线附近,表明XGBoost模型具有很好的学习能力和预测能力。同时模型预测的鲁棒性好且没有出现过拟合现象,这一结论也可以从图 6(c)中得到证实,在测试集中,模型预测值与真实值吻合,绝对误差较小。因此,BO-XGBoost模型是一种可靠的建模方法,可以为压实路基的回弹特性预测提供有力支持。

|
| 图 6 BO-XGBoost对数据集的预测结果 Fig. 6 Prediction results with BO-XGBoost on data sets |
| |
同时,为了进一步证明本研究所建立的BO-XGBoost的训练效果,将BO-XGBoost模型与其他机器学习模型(即基于网格搜索进行超参数优化的XGBoost、GA-ANN[22]和SVR[23])与传统的预测路基弹性模量的经验模型LGP[4]和Kim[7]进行了对比。其中,GA-ANN模型是一种融合了遗传算法和人工神经网络的模型,通过遗传算法优化ANN中的权重和偏差参数,提高模型预测准确性和泛化能力。SVR是一种支持向量回归(Support Vector Regression)模型,是支持向量机SVM的回归形式。SVR通过将数据映射到高维空间,利用支持向量机的原理寻找一个最优的超平面,从而实现回归预测。
LGP模型是由Sadrossadat等提出的[4],通过线性遗传规划方法,计算了影响变量的回归系数,构建了如下经验模型:
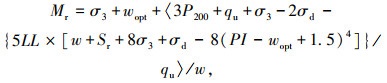
|
(12) |
式中,Sr为饱和度;wopt为最优含水量;LL为液限指数;qu为无侧限抗压强度。
Kim模型[7]是对3种不同土样的试验数据进行分析,通过数据拟合,得到的求解路基回弹模量经验模型。一般而言,相较于其他模型, Kim模型被认为有更为准确的拟合结果,计算公式如下:
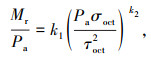
|
(13) |
式中,Pa为大气压强;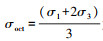
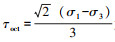
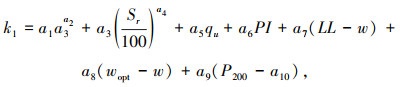
|
(14) |
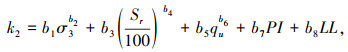
|
(15) |
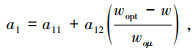
|
(16) |
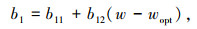
|
(17) |
式中a1-a12和b1-b12是Kim模型中的常数,对于A-4,A-6,A-7-6黏土类型的参数取值可参考文献[14]。值得说明的是,在2个经验模型中,计算Mr所需的参数均收集在数据集中。
表 4为所有预测模型在测试集上评价指标得分值。可以看出,采用机器学习建立路基回弹模量预测模型高于经验模型,相比于网格搜索的XGBoost算法,本研究所采用的BO-XGBoost的得分值更高。就计算效率而言,BO-XGBoost优化时间为30.2 s,而网格搜索的XGBoost优化时间为60.2 s,表明BO-XGBoost具有更高的计算精度和计算效率。此外,与其他机器学习算法相比,BO-XGBoost得分最高,表现出最好的预测效果,这证明BO-XGBoost在路基回弹模量预测任务中是一种有效且高效的机器学习方法。
| 模型代号 | R2 | RMSE/MPa |
| GA-ANN | 0.954 | 5.87 |
| SVR | 0.905 | 7.52 |
| XGBoost | 0.965 | 4.83 |
| LGP | 0.12 | 96.81 |
| Kim | 0.32 | 56.78 |
3.4 BO-XGBoost敏感性分析
可以通过计算特征在决策树中被用于分裂的次数或被分裂后减少的加权损失来计算XGBoost每个特征的重要性,从而进行特征敏感性分析。特征的重要性可以用来识别对模型影响最大的特征,可以帮助理解模型的预测过程。此外,XGBoost的特征重要性排名具有可解释性,可以帮助确定哪些特征是最相关的,以及哪些特征可以忽略,从而优化特征选择和模型构建。
图 7为BO-XGBoost模型特征重要性排名,可以看出干密度(γd)对预测模型起到绝对控制作用,而σd和σc影响较小,表明对于BO-XGBoost模型而言,力学参数对路基回弹模量预测敏感性较弱。值得说明的是,由于本研究的数据集容量有限,因此建议在后续研究中收集更多的数据,以更新和改进模型,以获得更全面、准确的参数相对重要性。这样可以提高模型的准确性和可靠性,为后续的路基回弹模量预测研究提供更为稳定的基础。

|
| 图 7 敏感性分析结果 Fig. 7 Result of sensitivity analysis |
| |
4 结论
本研究考虑了土的基本物理性质、力学参数、环境参数作为输入变量,提出了基于贝叶斯优化的XGBoost模型预测路基回弹模量,得出的主要结论如下:
(1) 采用了贝叶斯优化算法优化XGBoost模型,用于预测路基回弹模量。经过模型的检验,结果显示BO-XGBoost模型预测精度优于GA-ANN、SVR模型以及传统的LGP和Kim预测模型。相比基于网格搜索的XGBoost算法,BO-XGBoost模型具备更高的计算精度和计算效率。
(2) 对输入参数进行敏感性分析发现,在BO-XGBoost预测模型中,干密度γd对回弹模量预测效果起到绝对控制作用,NFT的相对重要度仅次于γd,而力学参数敏感性较弱。
| [1] |
陈开圣, 沙爱民. 压实黄土回弹模量试验研究[J]. 岩土力学, 2010, 31(3): 748-752, 759. CHEN Kai-sheng, SHA Ai-min. Research on Resilient Modulus Test of Compacted Loess[J]. Rock and Soil Mechanics, 2010, 31(3): 748-752, 759. DOI:10.3969/j.issn.1000-7598.2010.03.014 |
| [2] |
刘维正, 曾奕珺, 姚永胜, 等. 含水率变化下压实路基土动态回弹模量试验研究与预估模型[J]. 岩土工程学报, 2019, 41(1): 175-183. LIU Wei-zheng, ZENG Yi-jun, YAO Yong-sheng, et al. Experimental Study and Prediction Model of Dynamic Resilient Modulus of Compacted Subgrade Soils Subjected to Moisture Variation[J]. Chinese Journal of Geotechnical Engineering, 2019, 41(1): 175-183. |
| [3] |
赵腾远, 宋超, 何欢. 小样本条件下江苏软土路基回弹模量的贝叶斯估计—基于静力触探数据与高斯过程回归的建模分析[J]. 岩土工程学报, 2021, 43(增2): 137-141. ZHAO Teng-yuan, SONG Chao, HE Huan. Bayesian Estimation of Resilient Modulus of Jiangsu Soft Soils from Sparse Data-Gaussian Process Regression and Cone Penetration Test Data-based Modelling and Analysis[J]. Chinese Journal of Geotechnical Engineering, 2021, 43(S2): 137-141. DOI:10.11779/CJGE2021S2033 |
| [4] |
EHSAN S, ALI H, BEHNAM G. Towards Application of Linear Genetic Programming for Indirect Estimation of the Resilient Modulus of Pavements Subgrade Soils[J].
Road Materials and Pavement Design, 2016, 19(1): 139-153.
|
| [5] |
NGUYEN B T, MOHAJERANI A. Resilient Modulus of Fine-grained Soil and a Simple Testing and Calculation Method for Determining an Average Resilient Modulus Value for Pavement Design[J].
Transportation Geotechnics, 2016, 7: 59-70.
DOI:10.1016/j.trgeo.2016.05.001 |
| [6] |
PINCUS H J, PEZO R, HUDSON W R. Prediction Models of Resilient Modulus for Nongranular Materials[J].
Geotechnical Testing Journal, 1994, 17(3): 349-355.
DOI:10.1520/GTJ10109J |
| [7] |
KIM D G. Development of a Constitutive Model for Resilient Modulus of Cohesive Soils[D]. Columbus: The Ohio State University, 2004.
|
| [8] |
CARMICHAEL Ⅲ R F, STUART E. Predicting Resilient Modulus: A Study to Determine the Mechanical Properties of Subgrade Soils (Abridgment)[J].
Transportation Research Record, 1985, 145-148.
|
| [9] |
赵楠, 李洁. 基于LSTM-SVM的隧道围岩位移预测[J]. 公路, 2021, 66(6): 404-407. ZHAO Nan, LI Hao. LSTM-SVM Based Tunnel Envelope Displacement Prediction[J]. Highway, 2021, 66(6): 404-407. |
| [10] |
王才进, 蔡国军, 武猛, 等. 基于人工智能算法预测土体导热系数[J]. 岩土工程学报, 2022, 44(10): 1899-1907. WANG Cai-jin, CAI Guo-jun, WU Meng, et al. Prediction of Thermal Conductivity of Soil Based on Artificial Intelligence Algorithm[J]. Chinese Journal of Geotechnical Engineering, 2022, 44(10): 1899-1907. |
| [11] |
闫浩, 张吉雄, 周楠, 等. 基于DA-DE-SVM智能模型的煤岩体SC-CO2压裂效果预测[J]. 岩土工程学报, 2023, 45(2): 362-368. YAN Hao, ZHANG Ji-xiong, ZHOU Nan, et al. SC-CO2 Fracturing Effect Prediction of Coal and Rock Mass Based on Da-De-Svm Intelligent Model[J]. Chinese Journal of Geotechnical Engineering, 2023, 45(2): 362-368. |
| [12] |
CHEN T, GUESTRIN C. XGBoost: A Scalable Tree Boosting System[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016.
|
| [13] |
丁昌伟, 王新, 陈同俊, 等. 贝叶斯优化的XGBoost在小断层地震解释中的应用[J]. 煤炭学报, 2023, 48(6): 2530-2539. DING Chang-wei, WANG Xin, CHEN Tong-jun, et al. Application of Bayesian Optimized XGBoost in Seismic Interpretation of Small-scale Faults[J]. Journal of China Coal Society, 2023, 48(6): 2530-2539. |
| [14] |
HANITTINAN W. Resilient Modulus Prediction Using Neural Network Algorithm[D]. Columbus: The Ohio State University, 2007.
|
| [15] |
JONES D R, SCHONLAU M, WELCH W J. Efficient Global Optimization of Expensive Black-box Functions[J].
Journal of Global Optimization, 1998, 13(4): 455-492.
|
| [16] |
ZOU W L, HAN Z, DING L Q, et al. Predicting Resilient Modulus of Compacted Subgrade Soils under Influences of Freeze-thaw Cycles and Moisture Using Gene Expression Programming and Artificial Neural Network Approaches[J].
Transportation Geotechnics, 2021, 28: 100520.
|
| [17] |
DING L Q, HAN Z, ZOU W L, et al. Characterizing Hydro-mechanical Behaviours of Compacted Subgrade Soils Considering Effects of Freeze-thaw Cycles[J].
Transportation Geotechnics, 2020, 24(1): 100392.
|
| [18] |
RAHMAN T. Evaluation of Moisture, Suction Effects and Durability Performance of Lime Stabilized Clayey Subgrade Soils[D]. Albuquerque: The University of New Mexico, 2013.
|
| [19] |
SOLANKI P, ZAMAN M, KHALIFE R. Effect of Freeze-thaw Cycles on Performance of Stabilized Subgrade [C]//Geo-Congress. San Diego: ASCE, 2013.
|
| [20] |
REN J, VANAPALLI S K, HAN Z, et al. The Resilient Moduli of Five Canadian Soils under Wetting and Freeze-thaw Conditions and Their Estimation by Using an Artificial Neural Network Model[J].
Cold Regions Science and Technology, 2019, 168: 102894.
|
| [21] |
吴波, 陈辉浩, 黄惟. 基于模糊-熵权理论的铁路瓦斯隧道施工安全风险评估[J]. 安全与环境学报, 2021, 21(6): 2386-2393. WU Bo, CHEN Hui-hao, HUANG Wei. Safety Risk Assessment for the Railway Gas Tunnel Construction Based on the Fuzzy-entropy Method[J]. Journal of Safety and Environment, 2021, 21(6): 2386-2393. |
| [22] |
孟繁宇, 潘晓东. 基于神经网络-遗传算法的功能性沥青路面材料优选[J]. 吉林大学学报(工学版), 2013, 43(增1): 535-538. MENG Fan-yu, PAN Xiao-dong. Optimization of Functional Asphalt Pavement Based on GA-ANN[J]. Journal of Jilin University (Engineering and Technology Edition), 2013, 43(S1): 535-538. |
| [23] |
AZAM A, BARDHAN A, KALOOP M R, et al. Modeling Resilient Modulus of Subgrade Soils Using LSSVM Optimized with Swarm Intelligence Algorithms[J].
Scientific Reports, 2022, 12(1): 14454.
|