 2023, Vol. 40
2023, Vol. 40扩展功能
文章信息
- 梁铭, 彭浩, 宋冠先, 朱孟龙, 解威威.
- LIANG Ming, PENG Hao, SONG Guan-xian, ZHU Meng-long, XIE Wei-wei
- 基于优化集成算法的隧道超前钻探定量解译
- Quantitative Interpretation of Tunnel Advance Drilling Based on Optimized Integrated Algorithm
- 公路交通科技, 2023, 40(8): 136-145
- Journal of Highway and Transportation Research and Denelopment, 2023, 40(8): 136-145
- 10.3969/j.issn.1002-0268.2023.08.019
-
文章历史
- 收稿日期: 2021-07-02




 ,
, 2. 广西大学 土木与建筑工程学院, 广西 南宁 530004
2. School of Civil Engineering and Architecture, Guangxi University, Nanning Guangxi 530004, China
进入21世纪以来,随着我国交通运输行业的高速发展,公路隧道的建设规模也日益庞大。根据数据统计[1],截至2020年底,全国共有特长隧道共1 175处,累计512.75万m,已成为目前世界上公路隧道规模最大、数量最多、发展速度最快的国家。在隧道整体建设逐渐向大埋深、长洞线方向转变的过程中,选址远、高应力、强岩溶、高水压、构造复杂等特点也逐步凸显[2],各类不良地质体造成当前隧道在施工阶段面临较高的安全风险。
超前地质预报作为探明隧道地质条件、确保隧道施工安全的重要技术手段,一直是隧道建设发展过程中的研究重点。但在隧道超前不良地质体的探测方面,常规的物探方法如地质雷达、TSP、红外探水等均存在一定的局限性[3-4],而超前钻探法通过对掌子面前方围岩进行钻进,能最直观地反映掌子面前方的真实地质信息。目前,钻探数据解译工作主要依赖技术人员结合现场实际钻探情况进行,虽然钻机搭载的随钻测量系统可实时记录并提供各项钻探参数,但只是作为解译参考,并未被充分利用[5]。该种解译方式未脱离经验判断的范畴,较为粗糙,是一种“伪定量”解译。
随着大数据、计算机技术等信息化技术的发展,机器学习的理念已逐步渗入各个领域,为数据分析提供了全新思路及有利工具[6]。近些年开始有研究者将机器学习的方法引入隧道超前地质预报中以用于定量解译,并已分别在地质雷达[7]、TSP[8]中取得了一定的成果。在超前钻探方面,由于其在有效探明隧道超前不良地质体的同时,可提供大量与之相对应的数字钻探参数,如推进速度、推进力、扭矩、旋转速度等,这为机器学习在超前钻探地质预报中的应用提供了重要的数据基础。因此,基于上述钻探参数的超前钻探定量解译受到越来越多学者的重视。房昱纬等[9]对复杂地层隧道施工提出了一种基于神经网络的钻探测试数据智能分析和地层识别方法,对不同地层的识别准确率达到90%以上。邱道宏等[10]、Wang等[11]基于数字钻进技术,分别利用量子遗传-径向基函数神经网络与支持向量机对Ⅲ~Ⅴ级围岩超前分类进行研究,实际工程应用显示分类效果良好。王飞等[12]、刘诗洋等[13]分别基于XGBoost模型和卷积神经网络对TBM钻进过程中钻探参数与围岩质量之间的关系进行研究,为TBM的超前地质预警创造了有利条件。在工程应用方面,基于超前钻探参数的智能围岩质量评价在郑万铁路的多条隧道得到了成功应用[14]。可以预见,基于钻探数据定量解译的钻孔精细超前探测技术是未来隧道钻探预报领域的重要发展趋势[15]。
但以上研究普遍存在两个问题:一是大多以围岩等级或地层属性为预测结果,这种预测无法明确指出掌子面前方存在的不良地质体类型,对隧道施工的指导意义作用有限;二是基本以断面为单位进行预测,以“面”概“段”,极易受地质情况突变及钻机自身数据噪点的影响,不能真实反映预测断面附近一定范围内围岩的整体真实情况。
为解决上述两个问题,在已积累的大量超前钻探地质预报数据的基础上,提出一套与超前钻探数据定量解译相对应的数据预处理措施,并构建RS-XGBoost机器学习模型,针对广西地区灰岩隧道广泛存在的破碎围岩、软弱夹层与泥质填充溶洞这3类不良地质体展开定量解译研究。
1 钻探数据来源及分析 1.1 数据来源广西某隧道设计为分离式隧道,隧道由北至南先后穿越南北向的沟谷和东西向的岩溶石峰,长度约为1 600 m。隧道地质工程条件较为复杂,围岩等级主要为Ⅳ~Ⅴ级,属中风化~强风化灰岩夹泥岩。据地勘资料及已开挖情况显示,隧道围岩强度较低、完整程度较差,隧道沿线溶洞发育且多为泥质填充。
为保障隧道施工安全,现场使用C6-2型多功能履带式钻机进行超前钻探地质预报工作。根据前期积累的超前钻探地质预报数据,共收集原始钻探数据8 893条,数据涵盖的隧道长度累计约160 m。所收集的原始钻探数据除涉及条件较好的完整岩体外,还包括破碎围岩、软弱夹层及泥质填充溶洞这3类不良地质体的数据。
1.2 原始钻探数据结构分析在钻探作业过程中,系统随进尺变化进行随机高密度采样,每米采集数据约50条,每条采样数据包括5项定量指标,分别为深度、钻进速度、推进力、扭矩与旋转速度,其中深度仅记录掌子面距离,与不良地质体的解译无关,本研究不做考虑。通过对其余4项原始钻探数据进行结构分析,其主要具备以下特点。
(1) 采样阶段性:采样过程整体具有较强的连续性,同时呈现出明显阶段划分,即钻探开始的上升段及钻探过程中的稳定段。上升段通常集中在0~0.5 m的进尺范围内,该范围主要涉及空钻及初喷混凝土钻探,对不良地质体的定量解译无参考意义。
(2) 数据不完整性:在随钻测量系统对原始钻探数据进行采样的过程中,有时会因为机手操作及钻机机械原因导致个别指标的数据少量缺失,降低了整体数据的完整性。
(3) 数据非线性:各定量指标之间呈现较为明显的非线性相关,4项指标数据随深度的取值变化趋势缺乏统一性与规律性,从而增加了定量解译的难度。
(4) 离散程度大:钻进速度、扭矩与旋转速度指标的具体采样参数都表现出较大的离散性,具体离散程度与不同不良地质体的钻探密切相关。
1.3 特征相关性分析为了提高原始钻探数据质量,降低数据分析维度,加快机器学习模型收敛速度,通常需要对所用数据集指标进行特征相关性分析[16]。通过运用Scikit-learn中的pandas及matplotlib库对钻进速度、推进力、扭矩与旋转速度进行相关性分析,结果如图 1所示(该图数值无量纲)。

|
| 图 1 钻探定量指标相关性热力图 Fig. 1 Correlation heat map of drilling quantitative indicators |
| |
由图 1可以看出,原始钻探数据4项指标之间相关性较低,最大相关度仅为钻进速度与扭矩之间的0.53,说明4项指标对所选取的不良地质体而言都具备较为独立的解译价值。这一结论也符合已有相关研究中所使用的钻探指标情况。
2 原始钻探数据预处理原始钻探数据受机手操作及钻机自身机械因素影响,难以避免出现噪点数据。这些数据不仅不具备解译价值,还会降低数据集质量及后续模型预测性能,需要进行原始钻探数据的降噪处理。
同时,为避免原始钻探数据的高离散型性造成模型预测效果不佳,且用隧道某断面解译结果判定该断面一定区间范围内围岩质量的研究现状,本研究采用数据等距分割方式将降噪后的数据分割为若干段落,并以分割好的段落为单位进行2级指标的挖掘、计算与筛选,最终形成供机器学习模型训练学习的高质量数据集。
2.1 数据集标签设置及编码为实现对隧道破碎围岩、软弱夹层与泥质填充溶洞这3类不良地质体的定量解译,在进行原始钻探数据收集整理时,将标签设置为“较完整~较破碎”、“破碎~极破碎”与“软泥填充”,其中通过“较完整~较破碎”、“破碎~极破碎”2种完整程度标签实现对破碎围岩的解译预报,通过模型输出的“软泥填充”分布范围实现对软弱夹层与泥质填充溶洞的定量解译(单独分布为软弱夹层,连续分布为泥质填充溶洞)。若模型可对所设置的3类标签实现高准确率预测,即可对3类隧道不良地质体实现高准确率解译。
同时,为使机器学习模型在训练时可识别数据集标签,按照“较完整~较破碎”、“破碎~极破碎”与“软泥填充”的顺序将标签依次编码为“0”,“1”,“2”。
2.2 原始钻探数据降噪根据1.2节中对原始钻探数据结构的分析结论,制订相应的数据降噪措施,共包括以下两个步骤。
(1) 剔除上升段数据:将原始钻探数据中的上升段(0~0.5 m)数据剔除,消除上升段无解译价值数据对后续模型训练的影响。
(2) 缺失值填充:为保障数据的完整性,采用Scikit-learn中的impute.SimpleImputer模块进行缺失值的填充,具体选取参数为在“strategy”中输入“mean”,即采用原始钻探数据中该指标数据的均值进行填充。由于本研究所用数据量较大,采用均值填充可最大限度地降低数据填充带来的不确定性。
上述步骤实现了对原始钻探数据的降噪处理。随机选取某段原始钻探数据中0~10 m的钻进速度举例说明,降噪效果如图 2所示。

|
| 图 2 原始钻探数据降噪效果 Fig. 2 De-noising effect of original drilling data |
| |
2.3 等距分割及2级指标计算
在完成原始钻探数据的降噪处理后,进行原始钻探数据的等距分割。本研究数据分割间距d定为0.5 m,原因如下。
(1) 根据已积累的广西地区灰岩隧道超前钻探数据与实际开挖情况,软弱夹层的厚度大多小于0.5 m,泥质填充溶洞纵向分布规模大多在1 m及以上。因此,选择0.5 m便于在最大程度上对2种不良地质体进行分类,并使解译结果具备合理性。
(2) 当分割间距d < 0.5 m时,分割间距过小,钻机在作业过程中,由于机手操作及钻机机械等客观原因,会导致采样数据比实际数据偏高或偏低,且无法通过降噪进行剔除。分割间距过小会增加对这些异常数据的考虑权重,导致预测结果与实际不符。
(3) 当分割间距d > 0.5 m时,过大的分割间距会降低该分割间距内占比低于50%的不良地质体权重,如前述软弱层夹杂在岩层中间时其厚度通常不大于0.5 m,分割间距过大极易造成机器学习模型产生漏判或错判。
在完成数据分割后,为避免原始钻探数据的高离散性造成模型预测效果不佳,同时深度挖掘钻探数据对应各类不良地质体的数据规律,对4项指标各自分割段落内的原始钻探数据进行二次计算,形成对机器学习模型更具解译价值的2级指标。
本研究确定2级指标为4项1级指标的均值x及其方差sn2,具体理由如下。
(1) 均值x:虽然原始钻探数据离散度较高,但不同隧道不良地质体下的1级指标数据都存在一定的取值范围,均值是该取值范围的重要体现。此外,通过取均值的方式可降低分割间距内异常数据对整体真实数据状态的影响,有助于提高后续模型训练及预测的效果。
均值x如式(1)所示:
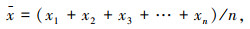
|
(1) |
式中n为样本数量。
(2) 方差sn2:原始钻探数据的离散性除受钻机自身机械因素影响外,更受围岩质量的影响。若完整围岩采样数据的离散程度较小,破碎围岩的采样数据相较于完整围岩离散程度大,通过取方差的方式可较为科学与合理地反映各类不良地质体对应原始钻探数据的离散程度,从而提高模型预测结果的真实性与有效性。
方差sn2如式(2)所示:
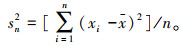
|
(2) |
经过数据等距分割及2级指标计算,共产生钻进速度均值、推进力均值、扭矩均值、旋转速度均值、钻进速度方差、推进力方差、扭矩方差与旋转速度方差共8项2级指标。
为降低特征维度,验证0.5 m作为等距分割间距的合理性,选取完成上述预处理措施的钻探数据,经标准化后绘制散点图进行分析,结果如图 3所示。

|
| 图 3 训练集指标均值与方差分布散点图 Fig. 3 Scattergrams of training set indicator mean and variance distribution 注:指标的采集以液压油缸的压力单位bar为单位,1 bar = 1.0×106 Pa, 下同。 |
| |
由图 3可以看出,3类标签的钻进速度均值、推进力均值、扭矩均值、旋转速度均值、钻进速度方差与扭矩方差的数值均表现出不同程度的差异性,其中推进力均值及扭矩均值最为明显,说明通过0.5 m等距分割并计算均值与方差后形成的这6项2级指标可有效地对3类标签进行区分,这种差异性有助于后续模型的学习与训练从而提高预测效果。但同时也发现,推进力方差与旋转速度方差数据取值的范围基本重叠,因此将推进力方差与旋转速度方差2项2级指标剔除。
经过上述针对超前钻探原始钻探数据的预处理流程,最终构成的超前钻探定量解译数据集的特征(即指标体系)包括钻进速度均值、推进力均值、扭矩均值、旋转速度均值、钻进速度方差、扭矩方差共6项。所收集的8 893条原始钻探采集数据最终形成的数据集共有数据324条,其中“较完整~较破碎”有116条,占比35.80%,“破碎~极破碎”有107条,占比33.03%,“软泥填充”有101条,占比31.17%。3类标签各自占比基本均衡。部分数据如表 1所示。
| 序号 | 钻进速度均值/(m·h-1) | 推进力均值/bar | 扭矩均值/(kN·m) | 旋转速度均值/(r·min-1) | 钻进速度方差 | 旋转速度方差 | 标签 |
| 1 | 39.068 3 | 101.693 3 | 59.743 9 | 129.074 0 | 62.985 8 | 138.592 2 | 0 |
| 2 | 34.631 8 | 101.617 5 | 56.872 0 | 114.995 4 | 19.851 2 | 39.071 3 | 0 |
| 3 | 34.829 8 | 101.601 3 | 52.438 2 | 108.724 3 | 5.820 7 | 11.426 9 | 0 |
| 4 | 33.539 2 | 100.886 0 | 50.222 9 | 106.100 1 | 37.103 0 | 38.542 5 | 0 |
| 5 | 30.829 1 | 101.710 8 | 51.527 9 | 115.021 4 | 4.654 3 | 38.187 3 | 0 |
| … | … | … | … | … | … | … | … |
| 117 | 30.089 2 | 97.880 7 | 47.550 7 | 106.041 1 | 253.141 1 | 16.08 | 1 |
| 118 | 73.976 7 | 97.829 7 | 52.876 8 | 104.712 6 | 1 572.859 6 | 70.094 4 | 1 |
| 119 | 66.740 9 | 97.803 | 54.587 6 | 102.77 | 1 730.251 3 | 36.17 | 1 |
| 120 | 97.653 1 | 97.874 1 | 51.803 8 | 104.721 4 | 2 793.577 7 | 51.970 9 | 1 |
| 121 | 72.293 2 | 97.821 6 | 50.301 1 | 106.569 1 | 1 313.697 5 | 60.472 8 | 1 |
| … | … | … | … | … | … | … | … |
| 320 | 156.516 1 | 103.073 7 | 93.729 5 | 60.490 3 | 96.242 3 | 59.630 9 | 2 |
| 321 | 161.952 9 | 103.150 7 | 89.664 4 | 61.547 2 | 8.687 3 | 49.720 1 | 2 |
| 322 | 157.903 5 | 102.881 4 | 99.107 2 | 66.034 7 | 23.604 0 | 85.130 1 | 2 |
| 323 | 132.428 5 | 102.983 0 | 111.460 9 | 66.414 6 | 1 036.321 6 | 314.229 0 | 2 |
| 324 | 124.524 7 | 102.695 9 | 118.411 5 | 83.705 9 | 27.290 1 | 11.156 9 | 2 |
3 相关模型及算法理论 3.1 XGBoost模型
极限梯度提升算法模型(Extreme Gradient Boosting,XGBoost)由Chen于2016年提出[17],可以有效地构建多线程运行的树模型,因此该模型具备计算复杂度低、运行速度快、准确度高等特点。
其中目标函数Obj(t)是衡量XGBoost模型好坏的重要的指标,其最小值越小,就认为该模型的表现越好。目标函数如式(3)所示[18]:
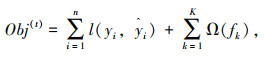
|
(3) |
式中,n为树模型的总数目;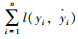
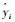
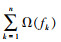
为了求解目标函数,可以使用泰勒展开对式(3)进行运算,结果为:
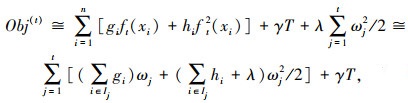
|
(4) |
式中,γ和λ分别为模型复杂度的系数;T为模型决策树叶子节点个数;gi和hi分别为样本xi的一阶导数和二阶导数;j为每个叶子节点的索引;ωj为第j个叶子节点上的样本权重;Ij为第j个叶子节点的样本子集。
将树的结构代入损失函数,即对ωj求导并令导函数等于0,可求得目标函数的最小值Objmin。Objmin是衡量模型好坏的重要指标,其最小值越小,就认为该模型的表现越好。计算如式(5)~(6)所示:
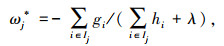
|
(5) |
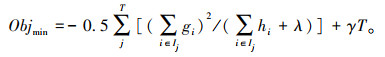
|
(6) |
调节模型超参数取值以提高模型性能是机器学习建模中极为重要的一环。目前,常用的调参方法分为手动调参与网格搜索(GridSearchCV,GS)自动调参。在超参数数量过多及参数精度过细时,前者调参难度极大,后者基于遍历原理,随着寻参数量的增加其寻参效率呈指数倍下降。
随机游走(RandomizedSearchCV,RS)是在GS的基础上进行寻参过程优化,与GS只可根据划定的网格空间及精度进行遍历参数寻优不同,RS可随机在参数空间采样,且对于有连续变量的参数会将其当作一个分布进行采样[19],从而高效解决了超参数过多情况下的模型调参问题。
3.3 机器学习模型分类性能评估在机器学习的分类问题中,模型评价指标主要根据预测结果的混淆矩阵情况进行计算,一个混淆矩阵由4个指标组成:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN),如图 4所示。

|
| 图 4 机器学习分类问题混淆矩阵 Fig. 4 Confusion matrix for machine learning classification problem |
| |
根据上述指标,可以计算常用的4项分类模型性能评价指标,即准确率(Accuracy, A)、精确率(Precision, P)、召回率(Recall, R)及精确率和召回率的调和平均分数(F1分数)。
具体计算式为:
(1) 准确率
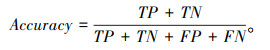
|
(7) |
准确率表示分类正确的样本占总样本的个数, 是分类问题中最简单最直观的评价指标,但在样本不平衡时存在明显的缺陷。
(2) 精确率
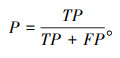
|
(8) |
精准率表示预测为正的样本中实际也为正的样本占被预测正样本的比例。
(3) 召回率
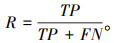
|
(9) |
召回率表示实际为正的样本中预测也为正的样本占实际正样本的比例。
(4) F1分数
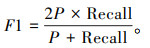
|
(10) |
因为精确率和召回率是1对相互矛盾的量,所以为综合评价分类器的性能,一般使用F1分数作为评价标准来衡量分类器的综合性能。
4 RS-XGBoost模型训练及评估如前文所示,在数据预处理方面通过对原始钻探数据进行分析,制定了与之相匹配的数据预处理措施。在解译模型方面选择XGBoost作为解决多分类问题的机器学习模型,并针对其过多超参数导致的调参困难搭配RS算法进行自动化寻优,最终形成RS-XGBoost超前钻探定量解译模型。具体模型参数寻优、训练及评估如下。
4.1 超参数寻优如3.1节所述,求解Obj(t)的最小值是XGBoost模型的最终目标。在此过程中需对模型超参数进行设置。根据已有研究成果[20],对XGBoost模型影响程度较大的超参数主要有n_estimators,max_depth,learning_rate,min_child_weight,subsample与colsample_ bytree。
首先根据RS的规则,结合XGBoost算法特点划定网格搜索空间,针对上述超参数所构建的网格搜索空间依次为(10,100,1),(5,10,1),(0.1,1,0.1),(0.1,1,0.1)与(0.1,1,0.1),其中括号内前2个值为超参数的搜索范围,第3个值为搜索精度。在超参数寻优过程中,以准确率为寻优效果评价分数,并设置5折交叉验证以确保所选取超参数组合的真实性和有效性。最终RS超参数寻优结果如表 2所示。
| 算法 | 超参数取值 | 时间/s | 分数 |
| 默认 | (10,6,1,1,1) | 2 | 91.32 |
| GS | (70,5,0.4,0.6,0.2) | 5 347 | 95.10 |
| RS | (68,7,0.7,0.3,0.5) | 6 | 97.96 |
由表 2可知,RS-XGBoost模型的寻优评价分数最高,为97.96,此时超参数n_estimators,max_depth,learning_rate,min_child_weight与subsample的取值依次为(68,7,0.7,0.3,0.5);GS-XGBoost的分数与之较为接近,为95.10%;在XGBoost模型默认超参数取值情况下分数最低,仅为91.32%。在运行时间方面,GS-XGBoost运行时间高达5 347 s,远大于其他2种模型。综合寻优评价分数与模型寻优运行时间,采用RS算法对XGBoost模型进行调参优化的效果最佳。
4.2 模型综合性能评估在完成模型调参后,将该超参数组合下的XGBoost模型设置为最优性能模型,并应用于完成数据预处理的超前钻探不良地质解译数据集,数据集划分为70%训练集与30%预测集,最终模型预测效果如图 5所示。

|
| 图 5 预测集预测标签分布 Fig. 5 Distribution of prediction set prediction labels |
| |
由图 5可知,在所有的98例预测样本中,出现错判3例,总体预测准确率为96.94%,与参数寻优时5折交叉验证的准确率较接近,说明模型未出现过拟合现象。3例错判样本中,2例将“较完整~较破碎”预测为“破碎~极破碎”,可以看出该模型预测结果偏向保守,这种趋向安全的错判趋势在隧道超前地质预报中是可以被接受的。
同时,为进一步探究前文原始钻探数据预处理措施对数据解译的影响,将未经预处理的原始钻探数据导入模型进行更为具体的模型性能评价,结果如图 6所示。

|
| 图 6 数据预处理影响 Fig. 6 Influence of data preprocessing |
| |
由图 6可以看出,对比未进行数据预处理的原始钻探数据,模型预测性能得到较大幅度的提升,4项评价指标的平均提升幅度为17.08%。验证了本研究数据预处理措施的合理性与有效性。
5 工程实例应用为使用所构建的RS-XGBoost隧道超前钻探定量解译模型在实际隧道工程中对破碎围岩、软弱夹层及泥质填充溶洞这3类不良地质体的解译效果进行检验,选取隧道YK73+491—YK73+516段共15 m的钻探数据进行解译。该里程段的钻探图像如图 7所示。

|
| 图 7 YK73+491—YK73+516钻探数据 Fig. 7 Drilling data of YK73+491—YK73+516 section |
| |
该段在超前钻探地质预报报告中的解译结果为:5~6 m软泥充填型溶洞,6~14 m岩体较完整~较破碎,14~20 m软泥充填型溶洞。提取其原始钻探数据,经数据预处理后导入所构建模型,解译结果输出如表 3所示。
| 序号 | 深度/m | 解译标签 | 解译结果 |
| 1 | 5~5.5 | 2 | 软弱夹层 |
| 2 | 5.5~6 | 1 | 破碎~极破碎 |
| 3 | 6~13 | 0 | 较完整~较破碎 |
| 4 | 13~13.5 | 1 | 破碎~极破碎 |
| 5 | 13.5~14 | 2 | 软弱夹层 |
| 6 | 14~16.5 | 1 | 破碎~极破碎 |
| 7 | 16.5~20 | 2 | 泥质填充溶洞 |
为方便展示,表 3已对连续相同的解译标签进行了合并处理。可以看出,RS-XGBoost模型的解译结果首先与钻探报告保持了较高的一致性,同时也在细节方面存在区别,具体表现在报告将14~16.5 m区间解译为软泥填充溶洞,模型将该段解译为14~16.5 m范围内为破碎~较破碎围岩,其中13.5~14 m左右存在1处软弱夹层,16.5 m之后解译为疑似软泥填充溶洞。由图 7钻探数据图可以判断,13.5~14 m存在1处软弱夹层是较为合理的解译,且14~16.5 m虽然钻进速度增加,但数据离散程度较大,相比软泥填充溶洞,解译为较软的破碎围岩更为合理。
后经现场实际开挖,验证了模型解译的准确性。现场开挖至YK73+505(对应钻探图中14 m)附近发现厚度约0.2 m的夹泥层,但直至开挖到YK73+508(对应钻探图中17 m)附近发生掌子面突泥,后经探测判定前方为泥质填充溶洞。
目前,所研究的超前钻探定量解译模型作为辅助技术,已应用于数条广西灰岩隧道的超前钻探地质预报过程中,可提供详细的解译结果(0.5 m间距),且预报准确率满足现场预报需求,有效检验了所构建RS-XGBoost隧道超前钻探定量解译模型的工程可用性。
6 结论(1) 针对隧道超前钻探数据的定量解译问题,通过对原始钻探数据进行定性与定量分析,制定了包括数据降噪、等距分割、二级指标计算及筛选在内的标准化数据预处理流程,形成了针对破碎围岩、软弱夹层及泥质填充溶洞解译的高质量数据集。
(2) 构建了RS-XGBoost超前钻探定量解译模型。为检验模型性能,并说明所采取预处理措施的有效性,选取准确率、精准率、召回率及F1分数4项评估指标对模型进行综合评估。结果显示,在优化算法方面,对于综合模型运行时间及准确率,RS算法表现最优;与未进行预处理的原始钻探数据相比,RS-XGBoost模型性能平均提升幅度为17.08%。
(3) 将RS-XGBoost模型应用于实际隧道工程的超前钻探地质预报中。解译结果表明,该模型可较精准地对破碎围岩、软弱夹层及泥质填充溶洞进行预报,满足超前钻探预报的使用需求。同时,这与所提供超前钻探数据的真实性密切相关,且该方法确定的是一种机器预测的理论性结果,可为隧道超前钻探地质预报解译提供参考。
| [1] |
交通运输部. 2020年公路水运交通运输行业发展统计公报[R]. 北京: 交通运输部, 2021. Ministry of Transport. Statistical Bulletin on Development of Highway and Water Transport Industry in 2020[R]. Beijing: Ministry of Transport, 2021. |
| [2] |
李术才, 王康, 李利平, 等. 岩溶隧道突水灾害形成机理及发展趋势[J]. 力学学报, 2017, 49(1): 22-30. LI Shu-cai, WANG Kang, LI Li-ping, et al. Mechanical Mechanism and Development Trend of Water-inrush Disasters in Karst Tunnels[J]. Chinese Journal of Theoretical and Applied Mechanics, 2017, 49(1): 22-30. |
| [3] |
李术才, 刘斌, 孙怀凤, 等. 隧道施工超前地质预报研究现状及发展趋势[J]. 岩石力学与工程学报, 2014, 33(6): 1090-1113. LI Shu-cai, LIU Bin, SUN Huai-feng, et al. State of Art and Trends of Advanced Geological Prediction in Tunnel Construction[J]. Chinese Journal of Rock Mechanics and Engineering, 2014, 33(6): 1090-1113. |
| [4] |
周轮, 李术才, 许振浩, 等. 隧道综合超前地质预报技术及其工程应用[J]. 山东大学学报(工学版), 2017, 47(2): 55-62. ZHOU Lun, LI Shu-cai, XU Zhen-hao, et al. Integrated Advanced Geological Prediction Technology of Tunnel and Its Engineering Application[J]. Journal of Shandong University (Engineering Science), 2017, 47(2): 55-62. |
| [5] |
韦建昌, 邵羽, 梁铭. 超前水平钻探在岩溶隧道地质预报中的应用研究[J]. 中外公路, 2020, 40(3): 220-226. WEI Jian-chang, SHAO Yu, LIANG Ming. Research on Application of Advanced Horizontal Drilling in Geological Forecast of Karst Tunnel[J]. Journal of China & Foreign Highway, 2020, 40(3): 220-226. |
| [6] |
何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014, 27(4): 327-336. HE Qing, LI Ning, LUO Wen-juan, et al. A Survey of Machine Learning Algorithms for Big Data[J]. Pattern Recognition and Artificial Intelligence, 2014, 27(4): 327-336. DOI:10.3969/j.issn.1003-6059.2014.04.007 |
| [7] |
温世儒, 杨晓华, 郭元术. 基于频谱能量分析的地质雷达探测图像判读[J]. 工程科学与技术, 2020, 52(6): 120-130. WEN Shi-ru, YANG Xiao-hua, GUO Yuan-shu. Interpretation Based on Frequency Spectrum Energy Analysis of Ground Penetrating Radar Detection Image[J]. Advanced Engineering Sciences, 2020, 52(6): 120-130. |
| [8] |
吕擎峰, 赵本海, 潘松杰, 等. 基于TSP和PCA-Bayes法的隧道围岩分级[J]. 地下空间与工程学报, 2020, 16(1): 80-86. LÜ Qing-feng, ZHAO Ben-hai, PAN Song-jie. Classification of Tunnel Surrounding Rock Based on TSP System and PCA-Bayes Discriminant Method[J]. Chinese Journal of Underground Space and Engineering, 2020, 16(1): 80-86. |
| [9] |
房昱纬, 吴振君, 盛谦, 等. 基于超前钻探测试的隧道地层智能识别方法[J]. 岩土力学, 2020, 41(7): 2494-2503. FANG Yu-wei, WU Zhen-jun, SHENG Qian, et al. Intelligent Recognition of Tunnel Stratum Based on Advanced Drilling Tests[J]. Rock and Soil Mechanics, 2020, 41(7): 2494-2503. |
| [10] |
邱道宏, 李术才, 薛翊国, 等. 基于数字钻进技术和量子遗传-径向基函数神经网络的围岩类别超前识别技术研究[J]. 岩土力学, 2014, 35(7): 2013-2018. QIU Dao-hong, LI Shu-cai, XUE Yi-guo, et al. Advanced Prediction of Surrounding Rock Classification Based on Digital Drilling Technology and QGA-RBF Neural Network[J]. Rock and Soil Mechanics, 2014, 35(7): 2013-2018. |
| [11] |
WANG M, ZHAO S, TONG J, et al. Intelligent Classification Model of Surrounding Rock of Tunnel Using Drilling and Blasting Method[J].
Underground Space, 2021, 6(5): 539-550.
|
| [12] |
王飞, 龚国芳, 段理文, 等. 基于XGBoost的隧道掘进机操作参数智能决策系统设计[J]. 浙江大学学报(工学版), 2020, 54(4): 633-641. WANG Fei, GONG Guo-fang, DUAN Li-wen, et al. XGBoost Based Intelligent Determination System Design of Tunnel Boring Machine Operation Parameters[J]. Journal of Zhejiang University (Engineering Science), 2020, 54(4): 633-641. |
| [13] |
刘诗洋, 陈祖煜, 张云旆, 等. 基于卷积神经网络对TBM塌方段的反演分析[J]. 固体力学学报, 2021, 42(3): 287-301. LIU Shi-yang, CHEN Zu-yu, ZHANG Yun-pei, et al. Back Analysis of the TBM Collapse Section Based on Convolutional Neural Networks[J]. Chinese Journal of Solid Mechanics, 2021, 42(3): 287-301. |
| [14] |
王志坚. 郑万高铁隧道智能化建造技术研究及展望[J]. 隧道建设, 2021, 41(11): 1877-1890. WANG Zhi-jian. Status and Prospect of Intelligent Construction Technology of Tunnel in Zhengzhou-Wanzhou High-speed Railway[J]. Tunnel Construction, 2021, 41(11): 1877-1890. |
| [15] |
杜宇本, 蒋良文, 陈明浩, 等. 中国铁路隧道勘察技术的发展与展望[J]. 隧道建设, 2021, 41(11): 1943-1952. DU Yu-ben, JIANG Liang-wen, CHEN Ming-hao, et al. Development and Prospect of Geological Surveying Technology for Railway Tunnels in China[J]. Tunnel Construction, 2021, 41(11): 1943-1952. |
| [16] |
刘军, 翁贤杰, 张龙生, 等. 基于GA-BP神经网络的隧道围岩力学参数反演[J]. 公路交通科技, 2020, 37(7): 90-96. LIU Jun, WENG Xian-jie, ZHANG Long-sheng, et al. Inversion of Mechanical Parameters of Tunnel Surrounding Rock Based on GA-BP Neural Network[J]. Journal of Highway and Transportation Research and Development, 2020, 37(7): 90-96. |
| [17] |
CHEN T, GUESTRIN C. XGBoost: A Scalable Tree Boosting System[C]//22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: Association for Computing Machinery, 2016.
|
| [18] |
王燕, 郭元凯. 改进的XGBoost模型在股票预测中的应用[J]. 计算机工程与应用, 2019, 55(20): 202-207. WANG Yan, GUO Yuan-kai. Application of Improved XGBoost Model in Stock Forecasting[J]. Computer Engineering and Applications, 2019, 55(20): 202-207. |
| [19] |
BERGSTRA J, BENGIO Y. Random Search for Hyper-parameter Optimization[J].
Journal of Machine Learning Research, 2012, 13(1): 281-305.
|
| [20] |
张春富, 王松, 吴亚东, 等. 基于GA_Xgboost模型的糖尿病风险预测[J]. 计算机工程, 2020, 46(3): 315-320. ZHANG Chun-fu, WANG Song, WU Ya-dong, et al. Diabetes Risk Prediction Based on GA_Xgboost Model[J]. Computer Engineering, 2020, 46(3): 315-320. |