 2023, Vol. 40
2023, Vol. 40扩展功能
文章信息
- 肖赟, 刘洋, 裴爱晖, 梁子君, 张蒙
- XIAO Yun, LIU Yang, PEI Ai-hui, LIANG Zi-jun, ZHANG Meng
- 城市配送需求预测方法研究
- Study on Prediction Method of Urban Distribution Demand
- 公路交通科技, 2023, 40(3): 254-262
- Journal of Highway and Transportation Research and Denelopment, 2023, 40(3): 254-262
- 10.3969/j.issn.1002-0268.2023.03.030
-
文章历史
- 收稿日期: 2021-06-24




 ,
, 2. 安徽省智慧交通大数据分析与应用工程实验室,安徽 合肥 230601;
3. 长安大学 运输工程学院,陕西 西安 710064;
4. 交通运输部公路科学研究院,北京 100088
2. Anhui Province Laboratory of Intelligent Transport Big Data Analysis and Application Engineering of Anhui Province, Hefei Anhui 230601, China;
3. School of Transportation Engineering, Chang'an University, Xi'an Shaanxi 710064, China;
4. Research Institute of Highway, Ministry of Transport, Beijing 100088, China
城市配送是指服务于城区及市近郊的货物配送活动,是城市物流的重要组成部分。随着我国城镇化进程不断加快,城市内部的货物流通需求日益增加,2019年我国同城货运的交易量达到496亿元,同比增长21.9%[1]。我国同城货运市场规模不断扩大的同时,城市配送在配送模式、配送运营、物流资源整合及管理等方面还存在部分问题。2022年初,交通运输部、公安部、商务部提出各城市应加快推动城市货运配送体系绿色低碳发展[2],并发布《第三批城市绿色货运配送示范工程申报工作的通知》,文件中明确到“需预测城市配送需求量”。由此,如何降低城市配送成本、提高配送效率,有效预测城市配送需求量引导城市物流可持续发展成为社会研究的热点问题。
许多学者在研究城市配送模式[3-4]、配送路径优化[5-6]、配送中心选址[7]等方面具有显著成果。精准预测城市配送需求能够有效引导城市配送平台合理调整运力结构、科学配置运力资源及调控车辆配送路径,是合理规划城市物流的重要支撑,也是研究上述问题的基础。此外,掌握城市配送的需求规律有利于交通管理者掌握未来城市配送需求量的情况及活跃货运车辆数,以便及时制订相应的管理措施和疏导方案,提高交通管理与控制的成效。
在城市配送需求预测方面,郑欢欢等[8]以长春市为例,收集相关指标建立回归分析模型预测了未来年的城市配送需求总量,但该模型在数据有限时预测精度较差,难以匹配城市配送的动态性变化,且预测以年为单位,未具体到日或月,无法提供有效的数据支撑。Fang等[9]基于Pearson相关分析提取了城市配送的相关影响因素,通过T-S模糊推理系统预测了武汉市的城市配送需求量,该方法需要借助其他算法标定模型参数,复杂度较高,应用性存疑。此外,部分学者应用灰色预测模型、BP神经网络及支持向量机回归等方法开展了城市物流需求预测的研究[10-12],其中灰色预测模型适合于近似指数增长的预测,面向动态化的交通量预测准确性较差。BP神经网络虽适用于非线性系统的预测,但其收敛速度慢,在面对波动幅度较大的数据训练时容易陷入局部极小化情况。K近邻(K-nearest Neighbor)非参数回归是近年来在交通流预测领域应用广泛的一种方法,适用于不确定性、非线性变化的动态交通需求预测[13-16]。城市配送需求量预测的意义在于及时为相关平台和管理者提供决策依据,与其他方法相比,K近邻算法所需参数少,预测精度高,时效强且灵活性好,因此本研究拟基于K近邻算法进行城市配送需求的预测。
K近邻算法的预测精度主要受历史数据分类、状态向量选取、K值选取3个方面的影响[17-18]。现有的K近邻预测研究主要通过定性来划分历史数据集,根据历史数据趋势图主观判断,缺乏对数据分类的校验分析[19-20]。状态向量一般选择预测时刻前T时刻的历史数据,或通过影响因素与预测量之间的相关系数确定[19, 21-22]。K值的选取方法较多,主要根据历史数据预测精度的变化,通过交叉验证或遍历一定范围内的K值确定最佳K值[23-25]。
以上研究为K近邻算法预测城市配送需求提供了良好借鉴,但大部分单方面从K值或T值入手优化算法,而缺乏统筹考虑K值和T值的组合优化。为提高预测精度并满足实时预测城市配送需求,本研究拟改进搜索算法及调整参数规则,统筹动态优化T值和K值选取,提出一种适用性更强的改进K近邻算法,并与传统K近邻预测方法比较,验证改进预测方法的有效性。
1 研究方法 1.1 算法基本流程K近邻算法一般包含5个要素:历史数据库、状态向量、距离度量、近邻个数K及预测算法,其基本思想是在历史数据库中搜索与预测时刻状态向量最相似的K个历史数据,通过预测算法计算算数平均值(或加权值)输出预测值。算法的基本步骤如下。
步骤1:构建历史数据库。
步骤2:选取状态向量。
步骤3:定义距离度量方式。
步骤4:确定K值。
步骤5:计算预测结果。
步骤6:通过评价指标评估预测精度。
1.2 历史数据库历史数据库的构建是预测算法的基础,其数据质量和容量很大程度上影响了预测效率和精度。一方面需要对历史数据进行清洗,处理缺失值及异常值,以保证数据质量。另一方面需要对历史数据库按一定时间周期进行分类。历史数据不分类或分类太少都会影响预测精度,合理分类可改善预测算法的效率和精度。
1.3 K近邻算法搜索机制K近邻搜索是非参数回归中的关键环节,它由状态向量选取、距离度量和K值选取3部分组成。
状态向量选取。K近邻算法在历史数据集中搜索与当前数据近似的近邻点时,需要状态向量作为参考标准进行匹配,状态向量是指与预测量相关的因素组成的向量,一般可基于时间关联选取前T个时间段的历史数据,T的取值范围为[1, n-1],其中n为1个时间周期内时间单元的数量。
距离度量准则。距离度量是判断当前数据和历史数据库中数据近似程度的标准。为了平衡算法的预测速度与精度,一般采用等权重的欧式距离。
近邻个数K的选取。K值的选择对预测结果有较大影响,目前K值的选取大部分采用遍历法或交叉验证法。遍历法是在一定范围内取值,根据各个K值相应的预测精度选取最优K值。交叉验证法将历史数据分成m组、m-1组作为训练集,剩余1组作为测试集,依次变化训练集和测试集m次。交叉验证能有效评估预测效果的最佳K值,因此本研究通过交叉验证确定最合适的K值。
1.4 对比分析本研究通过统筹优化K和T值进而改进K近邻算法。为验证改进K近邻算法的合理性,并确定最优的预测算法,将改进K近邻算法与传统的K近邻算法进行比较,表 1列出比较的4种K近邻算法KNN1-4。
为确定不同算法的优劣,需要相应地评价指标衡量预测误差。常用的评价模型指标有平均绝对误差MAE、均方误差MSE、平均绝对百分比误差MAPE与均方百分比误差MSPE,MAPE能更直观地反映算法的预测精度,具有代表性。选取MAPE作为预测算法的评价指标及交叉验证中的标准,其值越小说明算法预测误差越小,预测精度越高。计算公式如下:
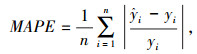
|
(1) |
式中,n为样本数;yi为样本实际值;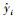
数据来自于安徽省合肥市2018年1月1日—2021年11月30日的城市配送数据。该城市配送数据包括日期、活跃车辆数、运输趟次、总核定载重及配送次数等,原始数据示例见表 2。
| 日期 | 活跃车辆数/veh | 总核定载重/t | 总行驶里程/km | 总运行时长/h | 总运输费用/元 | 配送次数/次 |
| 2018-01-01 | 417 | 265 881 | 7 128.9 | 952.2 | 44 234.0 | 590 |
| 2018-01-02 | 517 | 326 196 | 12 721.9 | 962.3 | 72 276.5 | 932 |
| 2018-01-03 | 492 | 279 926 | 11 125.4 | 5253.8 | 67 395.0 | 859 |
| … | … | … | … | … | … | … |
| 2021-11-29 | 922 | 715 423 | 35 821.31 | 2 233.46 | 175 189.04 | 2 020 |
| 2021-11-30 | 956 | 770 132 | 36 894.72 | 2 292.05 | 174 600.18 | 1 945 |
2018—2021年城市配送数据的变化趋势图如图 1所示。春节假日期间(2月份)城市配送需求量最低,其中2020年年初城市配送量发生断崖式下滑,主要是因为受疫情交通管制影响。临近暑期(6月)配送需求量较少,与全社会货运量趋势保持一致[26]。7月份后配送数量上升,且城市配送需求高峰期一般出现在每年7月至9月,9月底10月初国庆期间配送需求逐步减少,11月至12月期间配送需求又相应增加。

|
| 图 1 2018—2021年城市配送需求时间序列 Fig. 1 Time series of urban distribution demand from 2018 to 2021 |
| |
整体来看,重大节假日期如春节、中秋和国庆节期间配送需求较少,而非节假日期间配送需求相对较多,不同年度城市配送需求变化规律相似,且呈逐年缓慢上升趋势,但在同一年度内不同月份、日期表现出较大的突变性和不确定性等。
2.2 历史数据库的处理及分类考虑城市配送数据以天(d)为基本单位,本研究以周为时间序列将数据分成若干周。观察历史数据库,春节期间配送需求量几乎为0,预测意义不大,删除该时间段数据;2020年初城市配送受疫情严重影响,数据不具有代表性,删除该时间段数据。最终将205周数据整理为192周数据。
传统的交通流预测将历史数据分为平峰及高峰、休息日及工作日,或通过聚类分析分为几类数据集,起到了不错的预测效果。考虑到历史数据库分类越多预测精度相对越高,城市配送数据集以d为单位最多可分为7类子数据库。由此为提高预测精度,将历史数据分至最多类别——7类子数据库,即周一、周二、周三、周四、周五、周六和周日。
分类后数据的描述性统计见表 3,周一至周四及周六5类平均值较为接近,周五类城市配送均值最高1 507.38,而周日最低均值仅为1 288.72,各类子历史数据库标准差较大,说明城市配送数据离散程度较大,与城市配送的动态性变化吻合。ANOVA分析结果见表 4,统计量F=6.368(P=0.000 < 0.001)表明7类子历史数据库间有显著差异,依据上述分析结果确定历史数据库分为7类。
| 分类 | N | 最小值 | 最大值 | 均值 | 标准偏差 |
| 周一 | 192 | 88 | 2 615 | 1 480.99 | 427.15 |
| 周二 | 192 | 159 | 2 663 | 1 470.40 | 400.29 |
| 周三 | 192 | 249 | 2 419 | 1 482.22 | 379.35 |
| 周四 | 192 | 252 | 2 728 | 1 487.88 | 442.31 |
| 周五 | 192 | 176 | 2 517 | 1 507.38 | 446.01 |
| 周六 | 192 | 77 | 2 827 | 1 446.34 | 402.56 |
| 周日 | 192 | 37 | 2 315 | 1 288.72 | 349.96 |
| 分类 | 平方和 | 自由度 | 均方值 | F | 显著性 |
| 组间 | 6 362 254.448 | 6 | 1 060 375.741 | 6.368 | 0.000 |
| 组内 | 222 644 843.406 | 1 337 | 166 525.687 | — | — |
| 总计 | 229 007 097.854 | 1 343 | — | — | — |
7类子数据库的变化趋势见图 2,可知各类数据在配送量及波动趋势具有一定差异。周一和周五2类城市配送数据波动较明显,但周五配送数量高于周一,且一定时间段内波动更频繁;周二、周三和周四3类在配送量上相近,但在一定的时间区间内周二类数据集波动频率更频繁,波动范围更大;属于休息日的周六、周日2类子数据库,变化趋势在一定时间区间内相似,但数量级方面周六类更高,变化幅度更大。

|
| 图 2 七类历史城市配送数据变化趋势 Fig. 2 Trends of distribution data in 7 types of historical cities |
| |
2.3 状态向量的设计及度量方式
状态向量一般选取与预测对象最为相关的因素。交通流具有时间自相关性,一般选取历史流量数据为状态向量。由此选择预测当天前若干天的城市配送量作为状态向量,考虑数据集以周(7 d)为时间序列,则状态向量维度不超过6。通过SPSS25.0分别计算T=1~6时历史数据与预测需求间的皮尔逊相关系数,结果如表 5所示,分别为0.888,0.887,0.885,0.883,0.877及0.873,均呈显著正相关,说明历史数据能较好地反映预测当天的数据趋势,可以作为预测变量的状态向量。
| 变量 | 自相关系数 |
| 前(d-1) d配送量 | 0.888** |
| 前(d-2) d配送量 | 0.887** |
| 前(d-3) d配送量 | 0.885** |
| 前(d-4) d配送量 | 0.883** |
| 前(d-5) d配送量 | 0.877** |
| 前(d-6) d配送量 | 0.873** |
为了寻求最佳T值,以预测精度最高为目标,遍历所有T值。状态向量表达式见式(2)~(7):
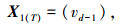
|
(2) |
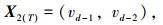
|
(3) |
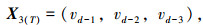
|
(4) |
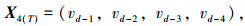
|
(5) |
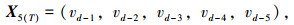
|
(6) |
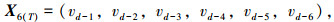
|
(7) |
式中,T为前T个时间间隔的城市配送数据; vd-1为预测日前1天的历史配送数据;vd-i为预测日前第i天的历史配送数据。
如预测周六的城市配送需求量,其6个T值对应的6个状态向量为:
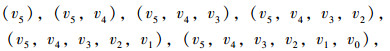
|
(8) |
式中,v0为上一周周日的城市配送量,以此类推v-1则为上一周周六的城市配送量。
在距离度量方面,采用最常用的等权重欧式距离作为度量指标:
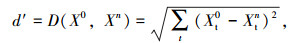
|
(9) |
式中,d′为预测周当日与历史周某日状态向量间的距离;X0为预测日当天的状态向量的集合;Xn为预测日前第n天的状态向量的集合;Xt0为预测日当天的前t个时间段状态向量子集;Xtn为预测日前第n天的前t个时间段的状态向量子集。
2.4 预测算法在K近邻搜索完成后,将搜索到的样本数据代入预测算法即可得出预测结果,预测算法是将K个近邻点的数据以一定的方式组合来预测下一时刻的配送需求量。已有研究表明带权重算法的预测性能和精度优于等权重算法。本研究采用基于度量距离倒数的加权平均预测算法,考虑预测数据点与近邻数据点的相关关系,以减小误差,预测算法如下:
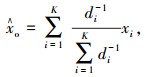
|
(10) |
式中,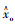
选择合理的K值和T值是K近邻预测算法的关键步骤。在历史数据库分类的基础上,计算各类子数据库在不同K值和T值下的预测精度,遍历所有历史数据,确定各类数据集的最优K值和T值。具体参数改进规则算法步骤如下。
步骤1:选择历史数据库中的任意1周Wn作为测试集,其他n-1周作为训练集,其中每个数据集有7个数据,分别代表 1周每7 d的城市配送量。
步骤2:依据时间属性对预测数据进行分类,预测值分为N类,设N=Ni,Ni∈[1, 7]。
步骤3:确定第Ni类预测数据下T的取值,设T=Ti,Ti∈[1, 6]。
步骤4:设K=Kj, Kj∈[1, Kmax],通常K值的上限在10~20,考虑平衡算法效率,确定Kmax=20。
步骤5:计算测试集Wn在各Ti和Kj下的第Ni类数据平均绝对误差百分比。
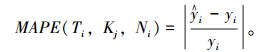
|
(11) |
步骤6:计算所有测试集在Ti和Kj下第Ni类数据的平均绝对误差百分比。
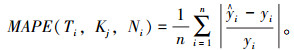
|
(12) |
步骤7:当MAPE取得最小值时,预测算法中所对应的Ti值和Kj值即为第Ni类子历史数据库的最优T值和K值。
遍历所有历史数据,各类子历史数据库下的最优K值和T值及相应的最小MAPE如表 6所示。可知各类子数据库的最佳K值为2或3,除周五最佳T值为6,其余类子数据库最佳T值均在1~3之间波动,通过改进K近邻搜索机制,遍历所有测试集,K的最佳搜索区间为[2, 3],而状态向量取前T个时间段历史数据的最佳搜索区间为[0, 6]。各分类数据的平均绝对百分比误差在均12%以内,预测值与实际值接近,其中周二类数据平均预测误差最小(2.92%),其次是周三类(3.55%),周四至周六类的预测误差相对较大,在10%左右。7类数据平均预测误差仅为7.65%,整体预测精度较高。
| 类别 | 最佳K值 | 最佳T值 | MAPE/% |
| 周一 | 2 | 2 | 5.46 |
| 周二 | 3 | 1 | 2.92 |
| 周三 | 3 | 2 | 3.55 |
| 周四 | 2 | 2 | 9.72 |
| 周五 | 2 | 6 | 10.47 |
| 周六 | 2 | 3 | 11.27 |
| 周日 | 3 | 1 | 10.13 |
3 预测结果及讨论 3.1 城市配送需求预测算法比较
为分析本研究K近邻算法的预测准确性与对城市配送需求的非线性和突变性变化的反应及时性,将表 1中提出的4种K近邻算法进行比较。
KNN1:设定固定的K值和T值。由于7类历史数据的最优K值为2或3,这里固定K为3;数据集以周为单位,目前大部分研究选取预测点时刻单位以外的时刻为T值,故固定T值为6。
KNN2:设定固定的K值,K值选择与KNN1一致,但改进T值的选取规则,对每类子数据库匹配最优T值再进行预测。
KNN3:设定固定的T值,T值选择与KNN1一致,但改进K值的选取规则,对每类子数据库匹配最优K值再进行预测。
KNN4:本研究提出的基于分类历史数据库,同时改进K值和T值选取规则的K近邻算法。
3.2 预测结果与分析选取合肥市2021年11月22日至2021年11月28日即最后1周的城市配送数据,分别采取4种K近邻预测算法进行该时间段的城市配送需求预测。
表 7对比了不同预测算法的平均预测误差指标,固定K和T、优化T、优化K及同时优化K和T值的4种K近邻预测算法的日平均绝对百分比误差分别为12.78%,9.03%,12.45%和8.18%,预测误差均在13%以内,说明K近邻算法能够较好地预测城市配送需求。
| 预测日期 | KNN1: 固定K和T |
KNN2: 优化T |
KNN3: 优化K |
KNN4: 优化K和T |
| 2021-11-22 | 6.87 | 6.75 | 5.55 | 5.38 |
| 2021-11-23 | 8.34 | 4.04 | 8.34 | 4.04 |
| 2021-11-24 | 13.32 | 4.66 | 13.32 | 4.66 |
| 2021-11-25 | 11.88 | 11.46 | 11.63 | 5.99 |
| 2021-11-26 | 16.07 | 11.30 | 15.93 | 10.02 |
| 2021-11-27 | 19.01 | 13.00 | 18.36 | 15.69 |
| 2021-11-28 | 13.99 | 12.02 | 13.99 | 11.45 |
相较于固定K和T的传统K近邻算法,单方面优化K或T值的改进K近邻算法的预测精度有所提高,其中优化K值算法预测精度提升有限,但优化T值算法预测误差降低了近4个百分点,而本研究提出的同时改进K和T值的K近邻算法预测精度比单纯优化T值更高,预测精度高达近92%。
由表 7可知,KNN1及KNN3的日平均绝对百分比误差较高, 分别为12.78%及12.45%,KNN2为9.03%,KNN4最低, 仅为8.18%,KNN2及KNN4的预测误差均低于KNN1及KNN3。KNN4的预测误差最低,比KNN1预测误差低4.6%,比KNN2低0.85%,比KNN3低4.27%。相较于KNN2(K值固定为3),算法KNN4的平均预测精度仅提高了0.85%,2种优化算法的精度差异不大,主要是因为受限于历史数据量和数据分类较少,优化后K值的集中为2和3,如能进一步扩充历史数据库和完善数据分类模式,优化K值和T值的预测准确率将进一步显著提升。本研究在平衡算法复杂度的前提下,KNN4的6类数据预测精度均不低于KNN2,且预测曲线更近似于实际城市配送需求的变化趋势。由此可见,同时改进K及T的K近邻算法具有更好的适应性,能及时反映城市配送数据的突变性和不确定性变化,说明改进的K近邻算法可更好地满足城市配送预测的需求。综上,统筹优化K值及T值,可显著降低K近邻算法的预测误差,预测精度可达92%左右,优于传统的K近邻预测算法,能够有效应用到城市配送需求预测领域中。
由图 3可知, 4种预测算法预测精度均较高,预测曲线与实际曲线均相似。其中固定K和T的预测算法(KNN1)在城市配送需求预测的变化趋势及数量上均与实际情况有一定出入,相较而言,虽然优化K值(KNN3)的K近邻算法预测准确度一般,但预测趋势基本符合实际值的走向。仅优化T值(KNN2)和同时优化K值及T值(KNN4)的K近邻算法的预测趋势与实际城市配送量变化趋势基本相似,预测曲线与实际值也比较吻合。

|
| 图 3 不同算法的城市配送需求量预测对比 Fig. 3 Comparison of predicted urban distribution demands obtained by different algorithms |
| |
4 结论
以城市配送需求预测为研究对象,对合肥市2018—2021年城市配送数据进行预处理,并分析了其数据特征。以周为数据集单位,对每天的城市配送需求数量进行方差分析,结果表明不同天的城市配送量具有显著差异,由此将历史数据集划分为7类子数据库。基于传统的K近邻非参数回归预测方法,以平均绝对百分比误差最小为基准,对K值和状态向量中T值的选取进行了改进,通过相关系数验证了T值的选取范围,对不同分类数据库匹配最佳K近邻搜索机制,构建了自适应K近邻模式预测算法,有效提高了预测精度。
选取1周城市配送数据进行预测。实证分析表明,固定K和T、优化T、优化K及同时优化K和T值的4种K近邻预测算法的日平均绝对百分比误差分别为12.78%,9.03%,12.45%和8.18%,本研究提出的同时优化K及T的改进K近邻算法整体预测精度为91.82%,优于其他3类未优化或单优化的K近邻算法,预测准确性和反应及时性更好。本研究对于精确化分析城市配送需求量,进而合理配置城市配送资源和运营方案有较大的意义。
在后续研究中,可在以下几个方面深化研究。一是考虑到城市配送平台还处于发展阶段,数据积累有待完善,需要扩大历史数据样本量,进一步验证算法的可靠性和适用性;二是应分别针对大中小等不同规模城市,深入分析其城市配送需求特性,分类别优化K近邻算法,进一步提升预测精度;三是考虑城市不同区域特征、天气条件及交通状况等相关因素优化状态向量的设计,提高算法的预测精度和效率。
| [1] |
赵胜男, 刘雨杭, 鲁子淇. 同城网络货运平台发展现状调查与分析[J]. 物流技术, 2022, 41(2): 26-29. ZHAO Sheng-nan, LIU Yu-hang, LU Zi-qi. Investigation and Analysis of Development Status of City Network Freight Platform[J]. Logistics Technology, 2022, 41(2): 26-29. |
| [2] |
佚名. 加快推动城市货运配送体系绿色低碳发展[J]. 中国环境监察, 2022(2): 7. An on. Accelerate Green and Low-carbon Development of Urban Freight Distribution System[J]. China Environment Supervision, 2022(2): 7. |
| [3] |
姜燕宁. 城市公共配送模式与公共配送系统研究[J]. 物流技术, 2013, 32(4): 51-53, 122. JIANG Yan-ning. Study on Urban Public Distribution Mode and Public Distribution System[J]. Logistics Technology, 2013, 32(4): 51-53, 122. DOI:10.3969/j.issn.1005-152X.2013.04.018 |
| [4] |
卫振林, 孙剑青. 面向中小电商企业城市共同配送模式探讨[J]. 北京交通大学学报(社会科学版), 2015, 14(1): 104-110. WEI Zhen-lin, SUN Jian-qing. A City-based Joint Distribution Model for Small and Medium-sized Electronic Enterprise[J]. Journal of Beijing Jiaotong University (Social Science Edition), 2015, 14(1): 104-110. DOI:10.3969/j.issn.1672-8106.2015.01.013 |
| [5] |
张婷, 赖平仲, 何琴飞, 等. 基于实时信息的城市配送车辆动态路径优化[J]. 系统工程, 2015, 33(7): 58-64. ZHANG Ting, LAI Ping-zhong, HE Qin-fei, et al. Optimization of Dynamic Vehicle Routing of Urban Distribution Based on the Real-time Information[J]. Systems Engineering, 2015, 33(7): 58-64. DOI:10.3969/j.issn.1001-2362.2015.07.040 |
| [6] |
葛显龙, 许茂增, 王伟鑫. 基于联合配送的城市物流配送路径优化[J]. 控制与决策, 2016, 31(3): 503-512. GE Xian-long, XU Mao-zeng, WANG Wei-xin. Route Optimization of Urban Logistics in Joint Distribution[J]. Control and Decision, 2016, 31(3): 503-512. DOI:10.13195/j.kzyjc.2014.1912 |
| [7] |
李栋, 高源发, 孙焰. 基于城市共同配送网络体的配送中心选址研究[J]. 综合运输, 2018, 40(2): 78-83, 88. LI Dong, GAO Yuan-fa, SUN Yan. Location of Distribution Center Based on the System Structure of Urban Joint Distribution[J]. China Transportation Review, 2018, 40(2): 78-83, 88. |
| [8] |
郑欢欢, 罗清玉, 陈会泽. 吉林省城市配送发展现状及需求预测分析[J]. 物流科技, 2016, 39(2): 102-106. ZHENG Huan-huan, LUO Qing-yu, CHEN Hui-ze. Distribution of Urban Development and Analysis of Demand Forecast in Jilin Province[J]. Logistics Sci-Tech, 2016, 39(2): 102-106. DOI:10.3969/j.issn.1002-3100.2016.02.029 |
| [9] |
FANG S S, CHEN Y Y, LIU X M, et al. Urban Distribution Demand Forecasting Analysis Base on T-S Fuzzy Inference System[J].
Agro Food Industry Hi-Tech, 2017, 28(1): 2437-2442.
|
| [10] |
孙剑青. 北京市物流需求预测研究[D]. 北京: 北京交通大学, 2016. SUN Jian-qing. Research on Logistics Demand Forecasting of Beijing[D]. Beijing: Beijing Jiaotong University, 2016. |
| [11] |
李赤林, 胡小辉. 基于BP神经网络的武汉城市圈物流需求预测[J]. 武汉理工大学学报(信息与管理工程版), 2009, 31(5): 773-776. LI Chi-lin, HU Xiao-hui. Method for Forecasting the Logistics Demand of Wuhan City Circle Based on BP Neural Network[J]. Journal of Wuhan University of Technology (Information & Management Engineering Edition), 2009, 31(5): 773-776. DOI:10.3963/j.issn.1007-144X.2009.05.024 |
| [12] |
吕淑丽. 基于支持向量机的城市物流需求预测研究[J]. 现代管理科学, 2013(11): 88-90. LÜ Shu-li. Research on Urban Logistics Demand Prediction Based on Support Vector Machine[J]. Modern Management Science, 2013(11): 88-90. DOI:10.3969/j.issn.1007-368X.2013.11.029 |
| [13] |
SMITH B L, WILLIAMS B M, OSWALD R K. Comparison of Parametric and Nonparametric Models For Traffic Flow Forecasting[J].
Transportation Research Part C: Emerging Technologies, 2002, 10(4): 303-321.
DOI:10.1016/S0968-090X(02)00009-8 |
| [14] |
吴晋武, 张海峰, 冉旭东. 基于数据约减和支持向量机的非参数回归短时交通流预测算法[J]. 公路交通科技, 2020, 37(7): 129-134. WU Jin-wu, ZHANG Hai-feng, RAN Xu-dong. Nonparametric Regressive Short-term Traffic Flow Forecast Algorithm Based on Data Reduction and SVM[J]. Journal of Highway and Transportation Research and Development, 2020, 37(7): 129-134. |
| [15] |
孙棣华, 李超, 廖孝勇. 高速公路短时交通流量预测的改进非参数回归算法[J]. 公路交通科技, 2013, 30(11): 112-118. SUN Di-hua, LI Chao, LIAO Xiao-yong. An Improved Nonparametric Regression Algorithm for Short-term Expressway Traffic Flow Forecasting[J]. Journal of Highway and Transportation Research and Development, 2013, 30(11): 112-118. DOI:10.3969/j.issn.1002-0268.2013.11.018 |
| [16] |
祁朵, 毛政元. 基于自适应时序剖分与KNN的短时交通流量预测[J]. 地球信息科学学报, 2022, 24(2): 339-351. QI Duo, MAO Zheng-yuan. Short-term Traffic Flow Prediction Based on Adaptive Time Slice and KNN[J]. Journal of Geo-information Science, 2022, 24(2): 339-351. |
| [17] |
梁艳平, 毛政元, 邹为彬, 等. 基于相似数据聚合与变K值KNN的短时交通流量预测[J]. 地球信息科学学报, 2018, 20(10): 1403-1411. LIANG Yan-ping, MAO Zheng-yuan, ZOU Wei-bin, et al. Short-term Traffic Flow Prediction Based on Similar Data Aggregation and KNN with Varying K-value[J]. Journal of Geo-information Science, 2018, 20(10): 1403-1411. DOI:10.12082/dqxxkx.2018.180281 |
| [18] |
陈佳维. 基于K近邻非参数回归方法的短时交通流预测[D]. 成都: 西南交通大学, 2017. CHEN Jia-wei. K-nearest Neighbors Nonparametric Regression in Short-time Traffic Flow Forecasting[D]. Chengdu: Southwest Jiaotong University, 2017. |
| [19] |
王翔, 陈小鸿, 杨祥妹. 基于K最近邻算法的高速公路短时行程时间预测[J]. 中国公路学报, 2015, 28(1): 102-111. WANG Xiang, CHEN Xiao-hong, YANG Xiang-mei. Short Term Prediction of Expressway Travel Time Based on K Nearest Neighbor Algorithm[J]. China Journal of Highway and Transport, 2015, 28(1): 102-111. DOI:10.3969/j.issn.1001-7372.2015.01.014 |
| [20] |
林培群, 陈丽甜, 雷永巍. 基于K近邻模式匹配的地铁客流量短时预测[J]. 华南理工大学学报(自然科学版), 2018, 46(1): 50-57. LIN Pei-qun, CHEN Li-tian, LEI Yong-wei. Short-term Forecasting of Subway Traffic Based on K-nearest Neighbour Pattern Matching[J]. Journal of South China University of Technology (Natural Science Edition), 2018, 46(1): 50-57. DOI:10.3969/j.issn.1000-565X.2018.01.007 |
| [21] |
于滨, 邬珊华, 王明华, 等. K近邻短时交通流预测模型[J]. 交通运输工程学报, 2012, 12(2): 105-111. YU Bin, WU Shan-hua, WANG Ming-hua, et al. K-nearest Neighbor Model of Short-term Traffic Flow Forecast[J]. Journal of Traffic and Transportation Engineering, 2012, 12(2): 105-111. DOI:10.3969/j.issn.1671-1637.2012.02.017 |
| [22] |
方琴, 李永前. K近邻短期交通流预测[J]. 重庆交通大学学报(自然科学版), 2012, 31(4): 828-831. FANG Qin, LI Yong-qian. On K-nearest Neighbor Short-Term Traffic Flow Prediction[J]. Journal of Chongqing Jiaotong University (Natural Science Edition), 2012, 31(4): 828-831. |
| [23] |
刘钊, 杜威, 闫冬梅, 等. 基于K近邻算法和支持向量回归组合的短时交通流预测[J]. 公路交通科技, 2017, 34(5): 122-128, 158. LIU Zhao, DU Wei, YAN Dong-mei, et al. Short-term Traffic Flow Forecast Based on Combination of K Nearest Neighbor Algorithm and Support Vector Regression[J]. Journal of Highway and Transportation Research and Development, 2017, 34(5): 122-128, 158. |
| [24] |
刘洋, 马寿峰. 基于聚类分析的非参数回归短时交通流预测方法[J]. 交通信息与安全, 2013, 31(2): 27-31, 40. LIU Yang, MA Shou-feng. Non-parametric Regression for Short-term Traffic Flow Forecasting Based on Cluster Analysis[J]. Journal of Transport Information and Safety, 2013, 31(2): 27-31, 40. DOI:10.3963/j.issn.1674-4861.2013.02.007 |
| [25] |
翁剑成, 荣建, 任福田, 等. 基于非参数回归的快速路行程速度短期预测算法[J]. 公路交通科技, 2007, 24(3): 93-97, 106. WENG Jian-cheng, RONG Jian, REN Fu-tian, et al. Non-parametric Regression Model Based Short-term Prediction for Expressway Travel Speed[J]. Journal of Highway and Transportation Research and Development, 2007, 24(3): 93-97, 106. DOI:10.3969/j.issn.1002-0268.2007.03.022 |
| [26] |
交通运输部. 公路货物运输量统计数据[EB/OL]. (2022-7-15)[2022-11-01]. https://www.mot.gov.cn/tongjishuju/gonglu/. Ministry of Transport. Statistical Data on Road Freight Traffic[EB/OL]. (2022-7-15)[2022-11-01]. https://www.mot.gov.cn/tongjishuju/gonglu/. |