 2022, Vol. 39
2022, Vol. 39扩展功能
文章信息
- 吕路, 李杰, 郭忠印, 阎莹, 高超
- LÜ Lu, LI Jie, GUO Zhong-yin, YAN Ying, GAO Chao
- 高速公路交通事故持续时间计算方法研究
- Study on Calculation Method of Expressway Accident Duration
- 公路交通科技, 2022, 39(12): 155-162
- Journal of Highway and Transportation Research and Denelopment, 2022, 39(12): 155-162
- 10.3969/j.issn.1002-0268.2022.12.019
-
文章历史
- 收稿日期: 2022-06-01

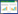


2. 山东高速信息集团有限公司, 山东 济南 250100;
3. 长安大学 运输工程学院, 陕西 西安 710064;
4. 陕西汇德通市政工程有限公司, 陕西 西安 710086
2. Shandong Hi-speed Information Group Co., Ltd., Jinan Shandong 250100, China;
3. School of Transportation Engineering, Chang'an University, Xi'an Shaanxi 710064, China;
4. Shaanxi Huidetong Municipal Engineering Co., Ltd., Xi'an Shaanxi 710086, China
交通事故是指车辆在道路上因过错或者意外造成人身伤亡或者财产损失的事件[1]。交通事故持续时间计算结果是划分事故等级,制定事故下的交通诱导、分流管控方案的重要依据。目前对交通事故持续时间的研究主要集中在事故影响因素分析[2]、事故持续时间计算方法[3]、降低交通事故损失[4]等方面,然而现有研究主要针对城市道路交通事故,对高速公路交通事故持续时间计算方法的研究不足。
不同于城市道路,高速公路交通感知、管控设施较少,交通流密度低、流速大,事故形态相对单一,由此导致城市道路交通事故与高速公路交通事故持续时间的影响因素存在差异[5],城市道路交通事故持续时间相关研究成果不适用于高速公路交通事故管理。除上述原因外,目前交通事故持续时间计算方法还存在计算复杂、模型稳定性差等问题[6]。
根据交通事故发生和处理过程,通常将交通事故持续时间划分为事件检测、事件响应、事件清除3个阶段,其大小由事故类型和当地交管部门的应急服务水平决定[7]。在建立交通事故持续时间计算模型时,将交通事故持续时间影响因素划分为交通事故特征、交通环境特征、交通状况特征以及道路特征[8]4个部分,各个特征又包含不同变量。重要性较大的变量组合能够显著提高模型计算精度[9]。随机森林和随机生存森林[10]、贝叶斯网络[11]、参数加速失效模型[12]等方法均可用于特征变量选择。
交通事故持续时间计算方法的适用性决定了模型计算结果的准确性。按照统计方法,交通事故持续时间计算模型可分为概率模型和非概率模型。决策树[13]、逻辑加速时间度量模型[14]、离散选择模型[15]是概率模型。线性回归模型[16]、时间序列模型[17]以及神经网络[18]是非概率模型。模糊Logistic回归模型[19]既可看作是概率模型,又可看作是非概率模型。受事故类型和交通环境差异影响,交通事故持续时间计算结果为一定误差范围内的估计值,对事故持续时间概率计算模型的应用研究越来越多。
本研究首先对贵州省高速公路交通事件持续时间分布进行了统计;其次,根据高速公路交通事故档案信息建立事故持续时间初始变量集,基于XGBoost方法对事故持续时间特征变量进行选择,建立了高速公路交通事故持续时间计算模型,并对各特征变量的敏感性进行了分析;最后,对模型性能和稳定性进行检验,建立了交通事故持续时间快速计算方法。
1 数据描述统计贵州省路网中心2020年8月1日至2021年7月31日记录的6 582条高速公路交通事件信息。每条数据包含事件初报和终报时间、事件地点、事件概况、事件类型、伤亡情况等要素。为了提高模型计算精度,对交通事件信息进行预处理。从描述性的事件概况中提取事件发生时间、事件发生位置以及车辆类型,消除事件发生和清除时间不明、事件类型等关键信息缺失的异常数据,删除发生在高速公路服务区、收费站站前广场等路外数据。为了避免异常值对计算结果产生影响,删除事件持续时间大于10 h的数据,最终得到6 332条有效数据。以50 min为间隔,绘制事件持续时间频数分布直方图,如图 1所示。

|
| 图 1 事件持续时间频数分布直方图 Fig. 1 Histogram of incident duration frequency distribution |
| |
图 1显示,随着事件持续时间的增加,事件频数迅速下降。事件持续时间主要集中在100 min以内,其中频数最大值出现在50 min以内。按照事件类型和事件发生的主要原因,将交通事件划分为道路交通事故、地质灾害、气象灾害、交通设施安全事件。处理后的各事件信息均包括事件发生时间、事件清除时间、事件类别、事件类型、事件地点、伤亡情况、涉及车辆类型、事件发生位置、事件阻塞车道数等信息。
不同事件类别持续时间分布特征统计结果,如表 1所示。表 1显示,道路交通事故是平均持续时间最短的一类事件,地质灾害事件和交通设施安全事件平均持续时间较长。除交通事故外,其他事件占交通事件总数的12.93%,表明交通事故是最常发生的一类事件。以下主要对交通事故持续时间计算方法进行研究。
| 事件类别 | 事件数量/起 | 事件持续时间均值/min | 事件持续时间标准差/min | 事件持续时间最小值/min | 事件持续时间最大值/min |
| 道路交通事故 | 5 513 | 37 | 12 | 17 | 236 |
| 地质灾害事件 | 75 | 354 | 91 | 114 | 583 |
| 气象灾害事件 | 713 | 95 | 63 | 45 | 174 |
| 交通设施安全事件 | 31 | 231 | 84 | 67 | 562 |
2 分析方法 2.1 初始变量集构建
由处理后的贵州省高速公路交通事件数据筛选得到交通事故数据集,按照交通事故特征、环境特征、交通状况特征以及道路特征构建事故持续时间的初始变量集。事故特征构成要素有事故类型、事故发生时段、受伤人数、死亡人数、涉及车辆类型、事故发生位置、剩余车道数;环境特征要素有能见度、气温、雨量、路面湿滑程度;交通状况特征要素有分车道流量、车型构成比例;道路特征要素包括道路类型、道路几何特征。
根据事件信息记录表,对各影响因素进行细分,建立交通事故持续时间初始变量集,其中环境特征和交通状况特征数据来源于高速公路沿线气象观测站和交通调查系统,道路特征数据来源于公路工程设计文件,结果见表 2。
| 影响因素分类 | 序号 | 事故影响因素 | 变量组成 |
| 交通事故特征 | 1 | 事故类型 | 1=单方事故,2=两车事故,3=多车事故 |
| 2 | 事故发生时段 | 1=黎明(3~7),2=早晨(7~11),3=中午(11~15),4=下午(15~19),5=午夜(19~23),6=夜晚(23~3)[20] | |
| 3 | 受伤人数/人 | 1=0,2=1,3=2,4=3+ | |
| 4 | 死亡人数/人 | 1=0,2=1,3=2,4=3+ | |
| 5 | 事故发生位置 | 1=互通立交区,2=其他 | |
| 6 | 涉及车辆类型 | 1=危险货物运输车,2=营运客车,3=货车,4=小客车 | |
| 7 | 剩余车道数 | 1=0,2=1,3=2+ | |
| 环境特征 | 8 | 能见度/km | 事故发生前10 min的平均能见度 |
| 9 | 气温/℃ | 事故发生前1 h内平均气温 | |
| 10 | 雨量/mm | 事故发生前1 h内累积降雨量 | |
| 11 | 湿滑程度 | 事故发生前10 min道路平均湿滑程度 | |
| 交通状况特征 | 12 | 服务水平 | 1=2级及以上,2=3级,3=4级,4=5级及以下 |
| 13 | 车型比例 | 事故发生前10 min断面交通流中的客车与货车比例 | |
| 道路特征 | 14 | 道路类型 | 1=隧道,2=桥梁,3=路堤,4=路堑 |
| 15 | 道路几何特征 | 1=(10直线,11平曲线),2=(20平坡,21上坡,22下坡) |
2.2 基于XGBoost的交通事故持续时间计算方法
极限梯度提升树(XGBoost)是梯度提升决策树(GBDT)的一个变种,属于顺序化的集成学习构建方法。同GBDT相比,最大的区别是XGBoost通过对目标函数中的结构损失函数做二阶泰勒展开,大大提高了模型的可扩展性、收敛速度和计算精度。
基于XGBoost的交通事故持续时间计算方法,主要包括特征变量选择和模型构建与参数调优两个步骤。以处理后的初始交通事故数据构建样本库,随机抽取50%的样本数据用于模型训练,另一半数据用于模型测试。算法流程为:
(1) 对原始事故信息进行预处理,构建初始变量训练集;基于XGBoost进行特征变量重要程度排序及选择。
XGBoost通过计算各特征变量给分裂节点带来信息增益的加权平均值,得到每个特征变量的重要性得分。特征变量重要性分数越高,其在模型构建中的价值越大。在特征变量按重要程度降序排列的基础上,依次计算由1个最重要特征变量至所有特征变量构建模型时的计算结果准确率,选择模型计算准确率最大时的特征变量作为变量筛选结果。
所得特征变量重要程度降序排列为:1,7,12,3,4,6,5,2,15,13,14,8,11,10,9,表明事故特征对事故持续时间的影响最大。图 2为模型计算准确率Rk随变量个数N的变化曲线,当变量个数由15减至7时,删除不重要变量能够减小冗余信息对算法带来的影响,模型计算准确率增加;当变量个数由7减至1时,随着重要特征变量被删除,模型计算准确率下降;当变量个数为7时,曲线有最大值。因此,事故类型、剩余车道数、服务水平、死亡人数、受伤人数、涉及车辆类型、事故发生位置即为筛选得到的交通事故持续时间特征变量。

|
| 图 2 模型计算准确率与变量个数之间的关系 |
| |
(2) 使用筛选得到的7个特征变量构建训练集来训练XGBoost,通过粒子群算法(PSO)优化模型参数。
在给定的包含n个样本和m个特征变量的数据集D={(xi, yi)}(|D|=n, xi∈Rm, yi∈R)中,集成树模型通过K步得到模型的计算值,如式(1)所示。
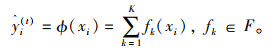
|
(1) |
式中, ŷi(t)为第i个样本在第t次迭代时的计算结果; φ(xi)为第i个样本的最终计算结果。每次迭代通过k步完成,其中,fk(xi)为第i个样本在第k步迭代时的计算结果,F={f(x)=wq(x)}(q: Rm→T, w∈RT)是回归树空间,R为实数集。即依次计算第k步的计算值与实际值的残差,通过残差的梯度下降最终得到真实值[21]。XGBoost模型的目标函数如式(2)所示。
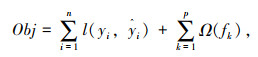
|
(2) |
式中,右半部分的第1项为损失函数,l(yi, ŷi)为第i个样本计算值与实际值的残差;第2项为抑制模型复杂度的正则项;fk为第k步迭代时的计算模型。
函数f(x+Δx)在点x处的二阶泰勒展开式为f(x+Δx)≈f(x)+f′(x)Δx+12f″(x)Δx2,通过类比可得到XGBoost的损失函数,如式(3)所示。
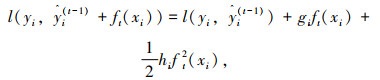
|
(3) |
式中,f(x)对应损失函数l(yi, ŷi(t-1));x对应前t-1棵树的计算值ŷi(t-1);Δx对应正在训练的第t棵树ft(xi);gi为损失函数的一阶导数;hi为损失函数的二阶导数,且均是对ŷi(t-1)求导。
通过枚举决策树每个叶节点中所有特征的可能分割方案,计算分裂前后目标函数的收益,以收益最大的特征作为分裂特征,用该特征的最佳分裂点作为结点的分裂位置,生成回归树模型。使用平均绝对百分误差(MAPE)评估模型计算准确率,MAPE值越小,模型计算准确率越高。
采用PSO算法优化模型参数,训练得到的模型计算误差率随迭代次数的变化关系,如图 3所示。当迭代次数为56时,模型计算误差率取得最小值29.5%,此时模型参数达到最优。

|
| 图 3 计算误差率曲线 Fig. 3 Calculation error rate curve |
| |
2.3 特征变量敏感性分析
通过XGBoost算法,可得到事故持续时间特征变量的重要程度序列。对筛选得到的交通事故持续时间特征变量进行敏感性分析,计算PSO算法优化后的各变量系数的指数值,得到不同特征变量对事故持续时间的影响程度,即当特征变量的取值改变1个单元时,事故持续时间变化的百分比,并使用指数系数进行表示,用于表征事故持续时间对特征变量的乘法效应估计。特征变量敏感性分析结果如表 3所示。
| 特征变量编号 | 特征变量* | 系数 | 标准差 | T统计量 | 指标影响程度/% |
| a1 | 事故类型:1, 2, 3 | 0.215 | 0.052 | 3.05 | 24.0 |
| a2 | 剩余车道数:1, 2, 3 | -0.154 | 0.041 | -3.12 | -14.3 |
| a3 | 服务水平:1, 2, 3, 4 | 0.132 | 0.039 | 2.75 | 14.1 |
| a4 | 死亡人数:1, 2, 3, 4 | 0.097 | 0.072 | 4.13 | 10.2 |
| a5 | 受伤人数:1, 2, 3, 4 | 0.056 | 0.075 | 7.24 | 5.8 |
| a6 | 涉及车型:1, 2, 3, 4 | -0.034 | 0.016 | -6.38 | -3.3 |
| a7 | 事发位置:1,2 | 0.024 4 | 0.047 | 1.75 | 2.5 |
| 常数项 | 3.264 | 0.027 | |||
| 样本量 | 5 513 | ||||
| 注: * 表 3中的特征变量与表 2中的变量组成一致。 | |||||
表 3显示,剩余车道数的增加、因涉及车型变化可能导致事故产生的人员伤亡和财产损失的减少,可降低交通事故持续时间,其余变量的变化将增加事故持续时间。死亡人数增加1人,引起的事故持续时间指数系数值为+e0.097,即事故持续时间将增加10.2%。同时,剩余车道数的变化引起的事故持续时间指数系数值为e-0.154,即85.7%,意味着剩余车道数每增加1条,事故持续时间将减少14.3%。
3 结果分析 3.1 模型性能比较统计交通事故持续时间计算模型在一定误差范围内的平均绝对百分误差(MAPE)。划分10,20,30,40,50 min共5个误差区间,按照事故持续时间小于50, 50~120, 120~300,300~600 min将交通事故划分为不同等级。基于XGBoost的交通事故持续时间计算结果误差率,如表 4所示。
| 事故持续时间T | 0 < t ≤50 min | 50 min < t ≤120 min | ||||||||||
| 误差范围/min | ≤10 | ≤20 | ≤30 | ≤40 | ≤50 | ≤10 | ≤20 | ≤30 | ≤40 | ≤50 | ||
| MAPE | 14 | 10 | 8 | 5 | 2 | 29 | 21 | 16 | 9 | 4 | ||
| 事故持续时间T | 120 min <t ≤300 min | 300 min <t ≤600 min | ||||||||||
| 误差范围/min | ≤10 | ≤20 | ≤30 | ≤40 | ≤50 | ≤10 | ≤20 | ≤30 | ≤40 | ≤50 | ||
| MAPE | 92 | 79 | 66 | 57 | 49 | 94 | 85 | 79 | 71 | 67 | ||
当MAPE小于等于20%时,可认为模型计算性能较好;当MAPE位于21%~50%之间时,可认为模型计算结果合理[22]。由表 4可知,当交通事故持续时间小于120 min时,此结果是可接受的,计算结论可作为制订事故发生后交通分流与管控方案的决策依据。但当交通事故持续时间大于120 min时,模型计算结果的MAPE大于50%,这主要是由于持续时间大于120 min的交通事故样本量小,特征变量构成复杂等原因造成的。
为了验证XGBoost交通事故持续时间计算方法的性能,采用邻近算法(KNN)和随机森林(RF)作为对比算法。不同模型在不同事故持续时间及误差范围内的计算准确率,结果如图 4所示。在不同事故持续时间和误差范围下,XGBoost模型的计算准确率高于KNN和RF。当交通事故持续时间大于120 min时,模型计算准确率在各误差范围内均下降至较低值。通过扩大样本量,对事故特征进行更加精细化的划分,可提高此类事故持续时间的计算准确率。

|
| 图 4 不同模型事故持续时间计算结果对比 Fig. 4 Comparison of accident durations calculated by different models |
| |
3.2 模型时空稳定性检验
受不同地区、不同时期交通运行环境差异影响,交通事故持续时间计算模型的变量系数可能不同,因此需要对模型时空稳定性进行检验。两个地区相同时期模型空间稳定性检验的对数似然比公式,如式(4)所示。
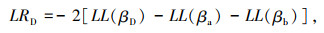
|
(4) |
式中,LL(βa)和LL(βb)分别为使用a地区和b地区的交通事故数据估计模型收敛时的对数似然;LL(βD)为两个地区所有的事故数据估计模型收敛时的对数似然。LR近似服从χ2(k)分布,其自由度k与筛选得到的事故持续时间特征变量个数相同。当显著性水平α取0.05时,查表可得模型区域稳定性对数似然比检验的临界值。
a地区数据为上述研究使用的贵州省2020年8月1日—2021年7月31日记录的5 513条高速公路交通事故信息,b地区数据为山东省2020年8月1日—2021年7月31日记录的3 423条高速公路交通事故信息。不同地区模型系数χ2(k)的检验结果,如表 5所示。
| 检验事项 | x2分布 | 自由度k | P值 |
| 山东数据检验贵州模型系数 | 3.998 | 7 | 0.78 |
| 贵州数据检验山东模型系数 | 3.549 | 7 | 0.83 |
| 贵州a和山东b地区所有事故数据估计模型收敛时的对数似然 | 0.435 | 7 | 1.00 |
同一地区不同时期模型时间稳定性检验的对数似然比公式,如式(5)所示。
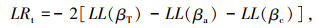
|
(5) |
式中,LL(βa)同式(4),LL(βc)为贵州省2017年10月1日—2018年9月30日记录的6 867条高速公路事故数据估计模型收敛时的对数似然;LL(βT)为两个时间段内所有事故数据估计模型收敛时的对数似然。不同时期模型系数χ2(k)的检验结果,如表 6所示。
| 检验事项 | x2分布 | 自由度k | P值 |
| 贵州a时期数据检验c时期模型系数 | 1.564 | 7 | 0.98 |
| 贵州c时期数据检验a时期模型系数 | 1.997 | 7 | 0.96 |
| 贵州a和c时期的所有事故数据估计模型收敛时的对数似然 | 0.435 | 7 | 1.00 |
同一时期不同地区的模型系数随地区转移不具有稳定性,但同一地区不同时期的模型系数随时间转移具有稳定性。在模型空间稳定性检验时,贵州交通事故数据检验山东模型系数的P值大于山东数据检验贵州模型系数的P值。这可能是因为贵州位于我国西南部,其地形、气候、交通环境更加多样,交通事故数据包含的信息更加全面,事故持续时间计算模型的适应性更好。
3.3 交通事故持续时间计算方法交通事故持续时间是指从交通事故发生至事故清除的时间,这一概念符合生存分析对生存时间的定义[23]。采用log-logistic函数对事故持续时间进行计算,事故持续时间风险函数的log-logistic模型表达式,如式(6)所示。
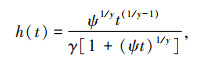
|
(6) |
式中,ψ=exp(-β′X),X为特征变量组成的列向量;β为参数;γ为示形参数,当γ < 1时,h(t)先增大后减小,当γ≥1时,h(t)单调递减。
单方事故、事故车辆停驶在硬路肩、路段服务水平为1级、死亡人数0人、受伤人数0人、涉及车型为小客车, 事发位置为基本路段的交通事故是最常见的一类事故,可将此类事故看作基准事故。风险函数h(t)是风险的一种度量,在时刻t1和时刻t2之间,h(t)越大,则事故清除(失效)发生的风险也越大。基准事故持续时间的失效风险如图 5所示,估算模型的拐点为29 min。意味着当事故持续时间超过29 min时将被很快清除,所以可认为基准事故的持续时间为29 min。

|
| 图 5 基准事故持续时间的失效风险 Fig. 5 Failure risk of base accident duration |
| |
事故持续时间的风险率随时间先增加后减小,表明示形参数γ小于1。根据交通事故持续时间特征变量敏感性分析结果,类比基准事故特征变量以及基准事故持续时间,建立交通事故持续时间计算模型,如式(7)所示。
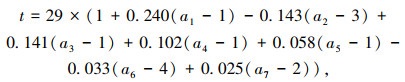
|
(7) |
式中,a1~a7的含义同表 3,取值方法见表 2。当交通事故发生时,高速公路管理人员可根据所发生的交通事故特征变量,快速进行事故持续时间计算。例如,事故类型为两车追尾、事发路段剩余1条通行车道、路段服务水平为3级、死亡人数0人、受伤人数2人、涉及车型为货车、事发位置为基本路段的事故持续时间计算方法,如式(8)所示
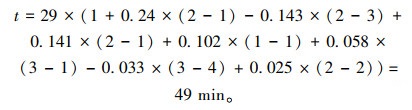
|
(8) |
本研究对高速公路交通事故持续时间计算方法进行了分析。利用贵州和山东省高速公路交通事件档案,交通和气象观测站统计数据以及高速公路设计文件,构建了包含4类15项事故持续时间影响因素的初始变量集。通过统计学习方法进行变量选择,建立了包含事故类型、剩余车道数、服务水平、死亡人数、受伤人数、涉及车辆类型、事故发生位置等7个变量在内的极限梯度提升树交通事故持续时间计算模型,并对模型性能进行了检验。得到的基本结论有:
(1) 将交通事件划分为道路交通事故、气象灾害、地质灾害、公路设施安全事件,交通事件发生频数和事件持续时间统计结果表明,交通事故是平均持续时间最短、发生频次最高的一类事件。
(2) 特征变量筛选结果表明,交通事故特征和交通状况特征对事故持续时间的影响程度高于道路特征和环境特征;根据所发生的交通事故特征,由变量敏感性分析结果、基准事故持续时间,可快速进行事故持续时间计算。
(3) 由于不同省份不同时期交通事故持续时间影响因素存在差异,所建交通事故持续时间计算模型具有时间稳定性,但不具备空间稳定性。
| [1] |
GB/T 39424.1—2020, 道路车辆交通事故分析第1部分: 术语[S]. GB/T 39424.1—2020, Road Vehicles — Traffic Accident Analysis — Part 1: Vocabulary[S]. |
| [2] |
VORKO-JOVIC A, KERN J, BILOGLAV Z. Risk Factors in Urban Road Traffic Accidents[J].
Journal of Safety Research, 2006, 37(1): 93-98.
DOI:10.1016/j.jsr.2005.08.009 |
| [3] |
GREIBE P. Accident Prediction Models for Urban Roads[J].
Accident Analysis and Prevention, 2003, 35(2): 273-285.
DOI:10.1016/S0001-4575(02)00005-2 |
| [4] |
NOLAND R B, OH L. The Effect of Infrastructure and Demographic Change on Traffic-related Fatalities and Crashes: A Case Study of Illinois County-level Data[J].
Accident Analysis and Prevention, 2004, 36(4): 525-532.
DOI:10.1016/S0001-4575(03)00058-7 |
| [5] |
中国公路学报编辑部. 中国交通工程学术研究综述·2016[J]. 中国公路学报, 2016, 29(6): 1-161. Editorial Department of China Journal of Highway and Transport. Review on China's Traffic Engineering Research Progress: 2016[J]. China Journal of Highway and Transport, 2016, 29(6): 1-161. DOI:10.3969/j.issn.1001-7372.2016.06.001 |
| [6] |
李维佳, 王建军, 白骅, 等. 路网环境下考虑大型车混入率的事故疏散诱导模型[J]. 中国公路学报, 2020, 33(11): 275-284. LI Wei-jia, WANG Jian-jun, BAI Hua, et al. An Accident Induction and Evacuation System Considering the Mixing Rate of the Large Vehicles Under the Freeway Network[J]. China Journal of Highway and Transport, 2020, 33(11): 275-284. DOI:10.3969/j.issn.1001-7372.2020.11.026 |
| [7] |
姬杨蓓蓓. 交通事件持续时间预测方法研究[D]. 上海: 同济大学, 2008. JIYANG Bei-bei. Research on Prediction Method of Traffic Incident Duration[D]. Shanghai: Tongji University, 2008. |
| [8] |
CHUNG Y, YOON B. Analytical Method to Estimate Accident Duration Using Archived Speed Profile and Its Statistical Analysis[J].
KSCE Journal of Civil Engineering, 2012, 16(6): 1064-1070.
DOI:10.1007/s12205-012-1632-3 |
| [9] |
商强, 林赐云, 杨兆升, 等. 基于变量选择和核极限学习机的交通事件检测[J]. 浙江大学学报(工学版), 2017, 51(7): 1339-1346. SHANG Qiang, LIN Ci-yun, YANG Zhao-sheng, et al. Traffic Incident Detection Based on Variable Selection and Kernel Extreme Learning Machine[J]. Journal of Zhejiang University (Engineering Science Edition), 2017, 51(7): 1339-1346. |
| [10] |
高珍, 柯阿香, 余荣杰, 等. 基于随机生存森林的交通事件持续时间预测[J]. 同济大学学报(自然科学版), 2017, 45(9): 1304-1310. GAO Zhen, KE A-xiang, YU Rong-jie, et al. Urban Expressway Traffic Incident Duration Prediction Based on Random Survival Forests[J]. Journal of Tongji University (Natural Science Edition), 2017, 45(9): 1304-1310. DOI:10.11908/j.issn.0253-374x.2017.09.008 |
| [11] |
杨超, 汪超. 快速路交通事件持续时间预测模型[J]. 同济大学学报(自然科学版), 2013, 41(7): 1015-1019. YANG Chao, WANG Chao. Traffic Incident Duration Forecast Model of Expressway[J]. Journal of Tongji University (Natural Science Edition), 2013, 41(7): 1015-1019. DOI:10.3969/j.issn.0253-374x.2013.07.009 |
| [12] |
HOJATI A T, FERREIRA L, WASHINGTON S, et al. Hazard Based Models for Freeway Traffic Incident Duration[J].
Accident Analysis and Prevention, 2013, 52: 171-181.
DOI:10.1016/j.aap.2012.12.037 |
| [13] |
姬杨蓓蓓, 张小宁, 孙立军. 基于贝叶斯决策树的交通事件持续时间预测[J]. 同济大学学报(自然科学版), 2008, 36(3): 319-324. JIYANG Bei-bei, ZHANG Xiao-ning, SUN Li-jun. Traffic Incident Duration Prediction Grounded on Bayesian Decision Method-based Tree Algorithm[J]. Journal of Tongji University (Natural Science Edition), 2008, 36(3): 319-324. DOI:10.3321/j.issn:0253-374X.2008.03.008 |
| [14] |
CHUNG Y. Development of an Accident Duration Prediction Model on the Korean Freeway Systems[J].
Accident Analysis and Prevention, 2010, 42(1): 282-289.
DOI:10.1016/j.aap.2009.08.005 |
| [15] |
LIN P W, ZOU N, CHANG G L. Integration of a Discrete Choice Model and a Rule-based System for Estimation of Incident Duration: a Case Study in Maryland[C]//CD-ROM of Proceedings of the 83rd TRB Annual Meeting. Washington, D.C. : TRB, 2004.
|
| [16] |
VALENTI G, LELLI M, CUCINA D. A Comparative Study of Models for the Incident Duration Prediction[J].
European Transport Research Review, 2010, 2(2): 103-111.
DOI:10.1007/s12544-010-0031-4 |
| [17] |
KHATTAK A J, SCHOFER J L, WANG M H. A Simple Time-Sequential Procedure for Predicting Freeway Incident Duration[J].
IVHS Journal, 1995, 2(2): 113-138.
|
| [18] |
WANG W, CHEN H, BELL M C. Vehicle Breakdown Duration Modelling[J].
Journal of Transportation and Statistics, 2005, 8(1): 75-84.
|
| [19] |
KIM H J, CHOI H K. A Comparative Analysis of Incident Service Time on Urban Freeways[J].
IATSS research, 2001, 25(1): 62-72.
DOI:10.1016/S0386-1112(14)60007-8 |
| [20] |
MENG F, WONG W, WONG S C, et al. Gas Dynamic Analogous Exposure Approach to Interaction Intensity in Multiple-vehicle Crash Analysis: Case Study of Crashes Involving Taxis[J].
Analytic Methods in Accident Research, 2017, 16: 90-103.
DOI:10.1016/j.amar.2017.09.003 |
| [21] |
CHEN T, GUESTRIN C, ASSOC COMP M. XGBoost: A Scalable Tree Boosting System[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco: [s. n. ], 2016.
|
| [22] |
JERALD F. Lawless. Statistical Models and Methods for Lifetime Data[M].
2nd ed. Hoboken, New Jersey: John Wiley & Sons, 2003.
|
| [23] |
CHUNG Y. Development of an Accident Duration Prediction Model on the Korean Freeway Systems[J].
Accident Analysis and Prevention, 2010, 42(1): 282-289.
DOI:10.1016/j.aap.2009.08.005 |