 2022, Vol. 39
2022, Vol. 39扩展功能
文章信息
- 李志坚, 郭玉彬, 赵建东
- LI Zhi-jian, GUO Yu-bin, ZHAO Jian-dong
- 基于视频图像和深度学习的车辆轨迹检测与跟踪
- Vehicle Trajectory Detection and Tracking Based on Video Image and Deep Learning
- 公路交通科技, 2022, 39(12): 149-154
- Journal of Highway and Transportation Research and Denelopment, 2022, 39(12): 149-154
- 10.3969/j.issn.1002-0268.2022.12.018
-
文章历史
- 收稿日期: 2021-08-03

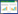


2. 北京交通大学 交通运输学院, 北京 100044
2. School of Traffic and Transportation, Beijing Jiaotong University, Beijing 100044, China
对车辆进行实时的异常行为检测,有利于提高道路交通管理的效率和车辆出行安全。利用计算机视觉方法对视频图像进行车辆检测成本低、实施方便,受到了越来越多的关注。
通过目标检测算法可以将图片中车辆的位置和类别信息检测出来,高精度的目标检测算法是进行车辆跟踪的重要基础。2015年,首个单阶段目标检测模型YOLO算法由Joseph[1]提出,该算法直接利用回归方法使用提取后的特征预测分类和边界框,具有快速检测的能力。随后该作者又提出速度更快精度更高的YOLO9000[2]、YOLOv3[3]算法。AlexAB[4]通过整合图像处理领域的各种提高精度的方法,提出了YOLOv4算法,相较于前一代精度提高10%。同年YOLOv5[5]发布算法,该模型在保持高精度检测的同时,速度更快。针对单阶段目标检测中前景与背景类别不均衡导致识别准确率较低的情况,Lin[6]等人提出RetinaNet模型和Focal Loss损失函数,使模型能够对所有类别进行充分的训练。但是当前针对类别不均衡问题并未得到完全的解决,仍然值得近一步研究。
在跟踪算法的研究中,Alex Bewley等人[7]提出SORT算法,该算法具有检测精度高,在检测速度方面比其他算法快20倍,但是该算法存在ID切换问题。随后提出的Deep Sort[8]算法,增加了级联匹配机制,并提取车辆外观特征,该算法有效地解决了ID切换和遮挡问题。Zhou等[9]提出CentreTrack跟踪算法,与Sort类算法不同的是,该算法是端到端的模型,以前一帧和后一帧图像以及前一帧图像检测结果渲染的热力图作为输入,直接完成追踪任务。如何解决遮挡问题是跟踪任务中的关键难点,虽然Deep Sort算法通过提取外观特征找回因遮挡而丢失的目标,但该模型性能较差,仍有改进空间。
综上,实时的车辆检测和跟踪算法研究主要存在以下难点:(1)如何在保证检测精度的同时,保持较高的检测速度;(2)在车辆轨迹追踪过程中如何解决遮挡问题,避免出现轨迹中断和ID跳变情况。本研究针对上述难点,建立高速公路车辆检测图像库,利用优化后的YOLOv5和Deep Sort算法进行车辆检测跟踪,得到精确的车辆轨迹。
1 道路监控视频图像库的建立车辆检测作为监督学习,需要对每张图片标注车辆类型以及在图像中的位置信息。由于研究场景为高位相机拍摄下的道路监控视频,视频中的车辆难以区分详细的类别信息,因此本研究将高速公路上的车辆分为小型车、公交客运车、货车3类,并用矩形框将车辆的位置标注出来。
从道路监控视频中抽取8 056张图片用于构建数据集,各类型车辆数量如表 1所示。在数据集构建的过程中,发现数据集中各类型车辆数量存在严重的不均衡现象,如小型车的数量比公交客运车多50 217个,另外道路监控视频下的车辆过于模糊,给检测造成一定的困难。在研究中,将数据集按6∶2∶2的比例进行划分。
2 基于YOLOv5的车辆检测研究 2.1 YOLOv5算法
(1) 网络结构
YOLOv5网络结构如图 1所示,输入的图片首先经过Focus结构进行下采样,接着通过由CBH结构和BottleneckCSP[10]结构组成的主干特征提取网络。CBH结构由卷积层、批归一化层、激活函数构成。经过主干特征网络后, 使用空间池化金字塔层[11],融合不同尺度的特征图信息,提高检测精度[12]。最后,使用PANet(Path Aggregation Network)[13]结构,针对3个不同尺度的特征图进行预测车辆目标信息。

|
| 图 1 YOLOv5网络结构 Fig. 1 Structure of YOLOv5 network |
| |
(2)损失函数
YOLOv5中使用的是损失函数如式(1)所示:
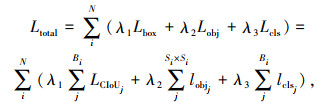
|
(1) |
式中,N为检测层的个数;YOLOv5中为3层;Lbox为边界框损失;Lobj为目标物体损失;Lcls为分类损失;λ1,λ2,λ3分别为上述3种损失对应的权重。
CIoU损失计算如式(2):
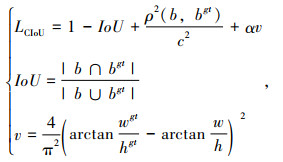
|
(2) |
式中,b,bgt分别为预测框和标签框;wgt,hgt为标签框的宽高;w,h为预测框的宽高;ρ为两个矩形框中心的距离[12];α为权重系数。
Lobj和Lcls计算方式如式(3):
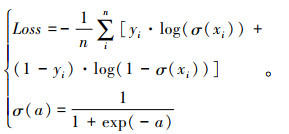
|
(3) |
通过对YOLOV5基准模型试验后发现,不同类别车型的检测精度和车型数量成正比,如数据集中小型车数量最多,模型可以学习到该类车型丰富的特征信息,因此检测精度最高。而数据集中公交客运车数量最少,模型没有得到很多的训练,因此检测精度最低。
2.3 YOLOv5算法优化(1) 网络结构优化
在基准YOLOv5网络中,Bottleneck模块中的Conv2层作为一种过渡层,不承担主要的特征提取任务,但增加了模型计算量,因此将该层去掉,减少参数;另一方面考虑引入Ghost Module[14]替换原始的右侧分支中Conv3卷积层,减少参数量。综合上述改进,提出CG3瓶颈层结构,其结构如图 2所示。其次,在CG3结构中的Bottleneck层中,引入参数相对较少的轻量注意力机制ECA(Efficient Channel Attention)[15],旨在提高网络模型的性能。

|
| 图 2 CG3-Attention瓶颈层 Fig. 2 CG3-Attention bottleneck layer |
| |
(2) 数据输入端优化
在基准网络试验中,发现不均衡的类别差异会给最后的检测结果带来较大的影响,因此从数据输入端进行优化。本研究以Mosaic[4]数据增强方法作为基础结合本数据集特点,提出Class-Weighted Mosaic(C-W-Mosaic)数据增强方法。具体步骤如下:
① 统计数据集中各车型的数量总数, 取倒数, 作为每一类车型的权重;
② 求每张图片的权重, 每类车型的权重乘图片中各车型的数量;
③ 将图片依据权重大小进行排序;
④ 首先随机抽取第1张图片, 第2, 3张图片从前n张图片中选取, 按照权重由大到小顺序选择, 第4张在剩余的部分中选择;
⑤ 随机将区域分为4部分,将上一步选择的4张图片放入;
⑥ 对于合成后的图片采用常用的数据增强手段。
(3) 网络结构改进试验结果对比
为了验证上述改进效果,在相同的试验条件(模型的超参数、训练数据集等)下,进行对比试验,验证集测试结果如表 2所示。通过表 2可以看出,在基准网络中使用CG3-Attention瓶颈层,检测指标mAP50和mAP50∶95分别提高了1.7%和2.4%。在数据输入端使用C-W-Mosaic数据增强相较于Mosaic方法,样本量较少的公交客运车检测精度AP50和AP50∶95分别提升0.9%和2.0%。通过试验结果表明,优化后的YOLOv5模型可以快速准确地检测车辆目标。
| 模型 | mAP50/% | mAP50∶ 95/% | 公交客运车 | |
| AP50/% | AP50∶95/% | |||
| 基准网络 | 92.8 | 70.0 | 86.7 | 66.7 |
| +CG3-Attention | 94.5 | 72.4 | 91.1 | 70.5 |
| +Mosaic | 96.2 | 76.0 | 95.0 | 76.6 |
| +C-W-Mosaic | 96.5 | 76.0 | 95.9 | 78.6 |
3 基于Deep Sort的多目标车跟踪改进算法 3.1 Deep Sort多目标跟踪算法原理
如图 3所示,本研究使用了Deep Sort多目标跟踪算法,完成车辆追踪任务,该算法通过提取车辆的外观特征,完成多帧图像车辆的匹配跟踪,使得车辆即使是在被遮挡的情况下仍能被再次匹配找回,增加了跟踪的稳定性。

|
| 图 3 Deep Sort多目标跟踪算法流程图 Fig. 3 Flowchart of Deep Sort multi-target tracking algorithm |
| |
3.2 Deep Sort算法优化
(1) 外观提取特征优化
原Deep Sort网络中,特征提取能力较差,并且高速公路高位相机拍摄的车辆尺度变化较大,同时容易受到环境因素影响,图像质量难以保证,加剧了Deep Sort的不稳定性。因此,本研究提出将Resnet18[16]残差网络作为原模型的特征提取网络,在保证检测速度的同时,提取更有分辨性的特征。另外,引入三元组损失[17],替换原有的损失函数。
三元组损失公式化表现如下:
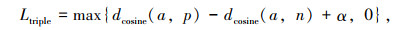
|
(4) |
式中dcosine(A, B)计算公式如式(5),表示两个向量之间的余弦距离。
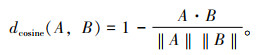
|
(5) |
使用公开的VeRi776车辆重识别数据集[18]进行训练,验证改进效果,结果对比如表 3所示。
| 模型 | Rank-1/% | Rank-5/% | mAP/% |
| Origin model | 81.6 | 91.0 | 42.8 |
| Resnet18 | 93.3 | 96.8 | 68.2 |
| Resnet18+Triple loss | 94.3 | 97.4 | 72.8 |
通过表 3可以发现原始的网络模型由于特征提取能力较较弱, 所以表现较差; 使用Resnet18残差网络之后,模型可以有效学习到相应的特征,检测精度相较于原始网络模型得到提升;损失函数改为三元组损失之后,模型检测精度得到近一步提升,对于车辆的区分能力更强。
3.3 改进跟踪算法结果对比选取高速公路监控视频对所提出的优化算法进行验证,所选择视频存在大量遮挡情况,具有一定的挑战性,能够有效的检验出优化后算法的稳定性。另外,选择主流的多目标追踪算法CenterTrack[9]和FairMOT[19]做对比试验。评价指标选用常用的MOTA(多目标跟踪准确率)、MOTP(多目标跟踪精确率)、MT(被跟踪到的轨迹占比)、FM(真实轨迹被打断的次数)[20]。
试验结果如表 4所示,可以发现改进后的模型跟踪效果更加稳定,轨迹被打断和ID跳变现象得到了有效缓解,在检测速度方面,优化后的模型可以达到25~30 fps,能够实时完成跟踪高速公路监控场下的车辆检测跟踪任务。
| 模型 | MOTA/% | MOTP/% | MT/% | FM |
| CenterTrack | 73.5 | 75.8 | 78.0 | 18 |
| FairMOT | 74.2 | 76.4 | 79.0 | 15 |
| DeepSort | 74.5 | 76.5 | 79.0 | 19 |
| 改进后DeepSort | 74.8 | 76.5 | 79.0 | 16 |
4 结论
本研究主要利用高速公路监控视频,研究车辆的检测和跟踪算法。制作了车辆检测数据集,从网络结构和数据增强方面优化了YOLOv5车辆检测模型,从外观特征提取模型和跟踪关联参数优化了多车跟踪模型,具体结论如下:
(1) 提出Class-weighted Mosaic数据增强方法,应用在YOLOv5目标检测模型的数据输入端,有效缓解少数量样本带来的问题;为了提高YOLOv5目标检测模型的检测效率和精度,设计CG3瓶颈层结构,提高车辆检测精度。
(2) 使用Resnet18残差网络作Deep Sort追踪模型的特征提取网络,并且将损失函数换成三元组损失函数,使得Deep Sort能够在车辆遮挡的情况下保持较高的检测稳定性。
(3) 试验结果表明,优化后的YOLOv5车辆检测模型,精确度由92.8%提高到了96.3%;Deep Sort多车跟踪优化模型有效降低了ID跳变和跟踪轨迹中断的次数,并且优化算法检测跟踪车辆可以达到25~30 fps的速度。
| [1] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
|
| [2] |
REDMON J, FARHADI A. YOLO9000: Better, Faster, Stronger[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7263-7271.
|
| [3] |
REDMON J, FARHADI A. YOLOv3: An Incremental Improvement[R]. [S. l. ]: arXiv Preprint, 2018.
|
| [4] |
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection[R]. [S. l. ]: arXiv Preprint, 2020.
|
| [5] |
YAN B, FAN P, LEI X, et al. A Real-time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5[J].
Remote Sensing, 2021, 13(9): 1619.
DOI:10.3390/rs13091619 |
| [6] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[J].
IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017(99): 2999-3007.
|
| [7] |
BEWLEY A, GE Z, OTT L, et al. Simple Online and Realtime Tracking[C]//2016 IEEE International Conference on Image Processing (ICIP). Phoenix: IEEE, 2016: 3464-3468.
|
| [8] |
WOJKE N, BEWLEY A, PAULUS D. Simple Online and Realtime Tracking with a Deep Association Metric[C]//2017 IEEE International Conference on Image Processing (ICIP). Beijing: IEEE, 2017: 3645-3649.
|
| [9] |
ZHOU X, KOLTUN V, KRAHENBUHL P. Tracking Objects as Points[C]//European Conference on Computer Vision. Springer: Cham, 2020: 474-490.
|
| [10] |
WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN[C] //2020IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 1571-1580.
|
| [11] |
HE K, ZHANG X, REN S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
DOI:10.1109/TPAMI.2015.2389824 |
| [12] |
郭玉彬. 基于视频图像的车辆检测跟踪及行为识别研究[D]. 北京: 北京交通大学, 2021. GUO Yu-bin. Vehicle Detection, Tracking and Behavior Recognition Based on Video Images[D]. Beijing: Beijing Jiaotong University, 2021.
|
| [13] |
LIU S, QI L, QIN H, et al. Path Aggregation Network for Instance Segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City: IEEE 2018: 8759-8768.
|
| [14] |
HAN K, WANG Y, TIAN Q, et al. Ghostnet: More Features from Cheap Operations[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 1580-1589.
|
| [15] |
WANG Q L, WU B G, ZHU P F, et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle: IEEE, 2020: 11531-11539.
|
| [16] |
HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| [17] |
SCHROFF F, KALENICHENKOE D, PHILBIN J. Facenet: A Unified Embedding for Face Recognition and Clustering[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 815-823.
|
| [18] |
LIU X, WU L, TAO M, et al. A Deep Learning-based Approach to Progressive Vehicle Re-identification for Urban Surveillance[C]// 2016 European Conference on Computer Vision. [S. l. ]: Springer, 2016.
|
| [19] |
ZHANG Y F, WANG C Y, WANG X G, et al. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking[J].
International Journal of Computer Vision, 2021, 129(11): 3069-3087.
DOI:10.1007/s11263-021-01513-4 |
| [20] |
BERNARDIN K, STIEFELHAGEN R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics[J].
EURASIP Journal on Image and Video Processing, 2008, 2008: 246309.
|